







前言
为了更好的掌握数据处理的能力,因而开启Python网络爬虫系列小项目文章。
- 小项目小需求驱动,每篇文章会使用两种以上的方式(Xpth、Bs4、PyQuery、正则)获取想要的数据。
- 博客系列完结后,将会总结各种方式。
一、需求
- 批量爬取4k类型的图片
- 下载到各类文件夹中
二、分析

1、Ctrl+U 查看网页源代码
$$$$
4
k
各类型主页
U
R
L
4k各类型主页URL
4k各类型主页URL$$$$

$$$$ 4 k 各类型图片 U R L 4k各类型图片URL 4k各类型图片URL$$$$

2、进一步分析
- 获取各类型url,拼接主页url地址
- 请求各类型url,获取具体4k图片下载地址
- 访问4k图片下载地址下载资源
三、处理
Bs4 +正则处理
- 通过page.find_all(“div”, attrs={“class”:“nav-m clearfix tran”}) 找到该类属性的div
- 发现数据堆在一条中,利用正则获取url、title(通用方法.*?)
def get_4k_url(source_code):
# 初始化bs4
page = BeautifulSoup(source_code,"html.parser")
info_4k = page.find_all("div", attrs={"class":"nav-m clearfix tran"})
# 利用正则获取相关信息
process = re.compile(r'<a href="(?P<url>.*?)" .*?>(?P<title>.*?)</a>',re.S)
# 将html转为字符串
result = process.finditer(str(info_4k))
# 定义字典进行存储
pic_dict = {}
for img in result:
title = img.group("title")
url = img.group("url")
if url.startswith("/"):
pic_dict[title] = f"{INDEX_URL}{url}"
return pic_dict
- 这里4k手机壁纸的类属性不一样,做了个判定处理
- 通过Select选择器定位到a标签获取src属性值
def get_img_url(url):
# 获取网页源代码
source_code = process_index(url)
# 初始化bs4
page = BeautifulSoup(source_code, "html.parser")
# 处理部分特殊(4k手机壁纸)
if url == "http://pic.netbian.com/shoujibizhi/":
info_4k_a = page.select(".alist > ul > li > a")
else:
info_4k_a = page.select(".slist > ul > li > a")
url_list = []
for a in info_4k_a:
# 获取url
url = a.find("img")["src"]
url_list.append(f"{INDEX_URL}{url}")
return url_list
PyQuery+正则处理
- 直接定位.nav-m 类属性
- 发现数据堆在一条中,利用正则获取url、title(通用方法.*?)
def get_4k_url(source_code):
doc = pq(source_code)
info_4k = doc(".nav-m")
# 利用正则获取相关信息
process = re.compile(r'<a href="(?P<url>.*?)" .*?>(?P<title>.*?)</a>',re.S)
# 将html转为字符串
result = process.finditer(str(info_4k))
# 定义字典进行存储
pic_dict = {}
for img in result:
title = img.group("title")
url = img.group("url")
if url.startswith("/"):
pic_dict[title] = f"{INDEX_URL}{url}"
return pic_dict
- 这里4k手机壁纸的类属性不一样,做了个判定处理
- 通过点位.slist/.alist 属性,再其定位li标签,获取img中的src
def get_img_url(url):
# 返回每一4k类型具体图片url
code = process_index(url)
doc = pq(code)
# 处理部分特殊(4k手机壁纸)
if url == "http://pic.netbian.com/shoujibizhi/":
ul = doc(".alist li")
else:
ul = doc(".slist li")
# 获取url
url_list = []
for li in ul.items():
url = li("img").attr("src")
url_list.append(f"{INDEX_URL}{url}")
return url_list
四、运行效果
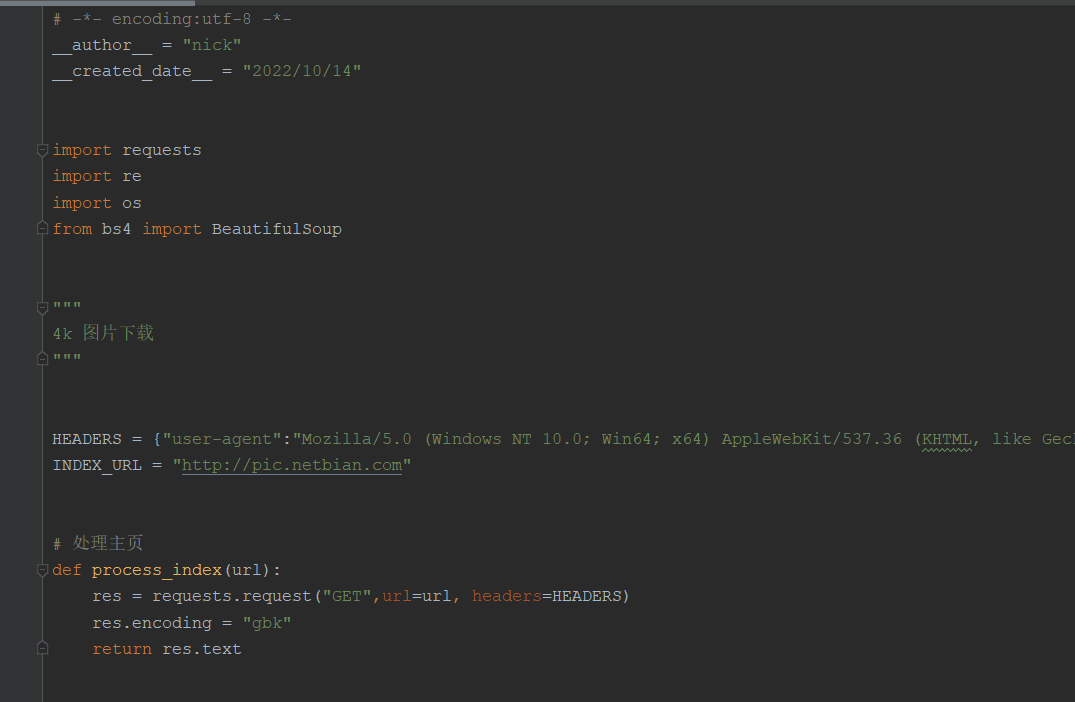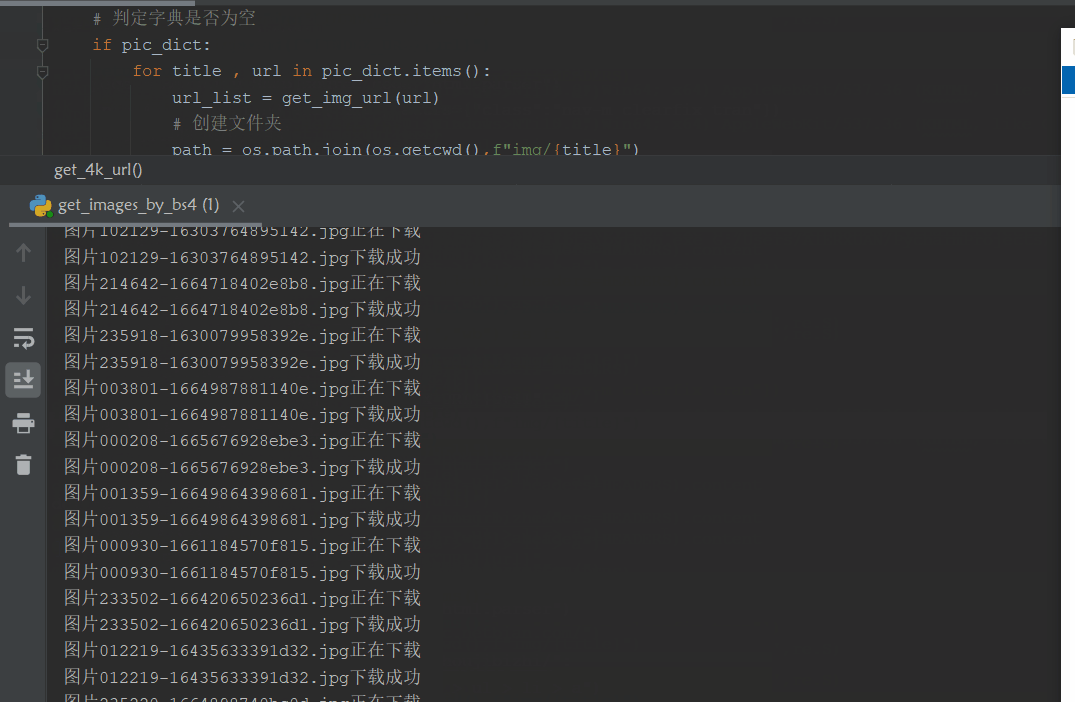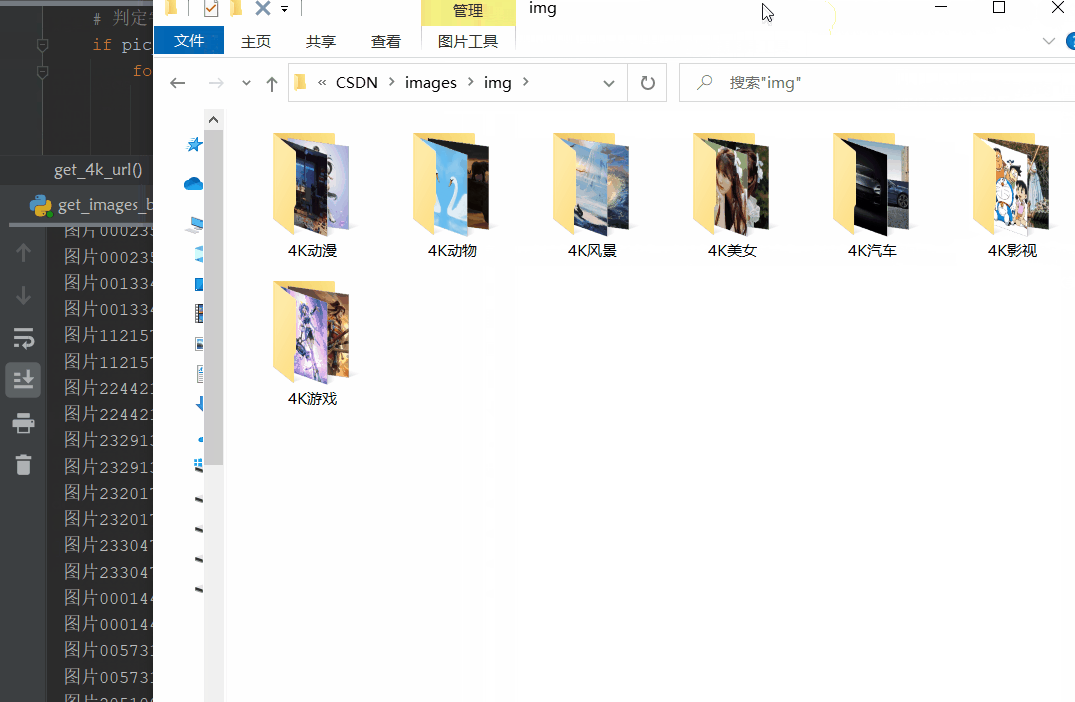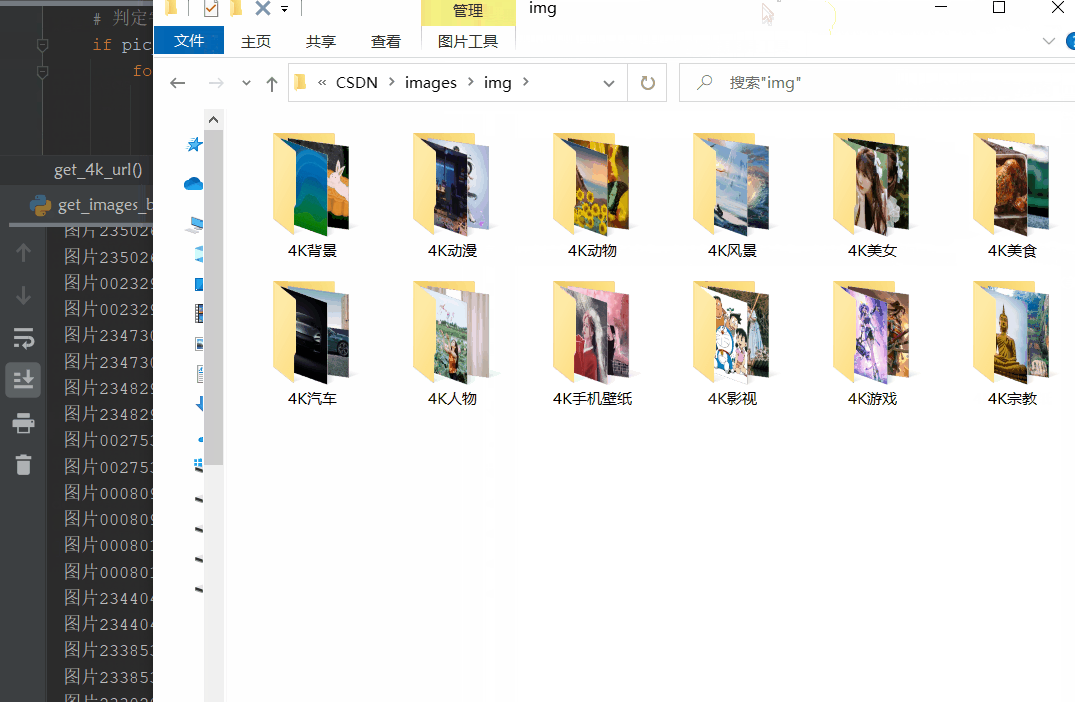
源码附在在知识星球-网络爬虫模块内
https://t.zsxq.com/077MNvfYJ














 2385
2385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









