









Keras
输入shape:(samples,timesteps,input_dim)
- (100,5,64)表示输入100个句子,每个句子5个单词,每个单词用一个64-dim的向量表示
- 所以
concat = torch.cat((x1,x3),1)#(none,50,2,244)
input_dim = 2*244
timesteps = 50
#每个句子有50个单词,每个单词表示向量为488-dim
Pytorch

LSTM基础知识
参考:
介绍
-
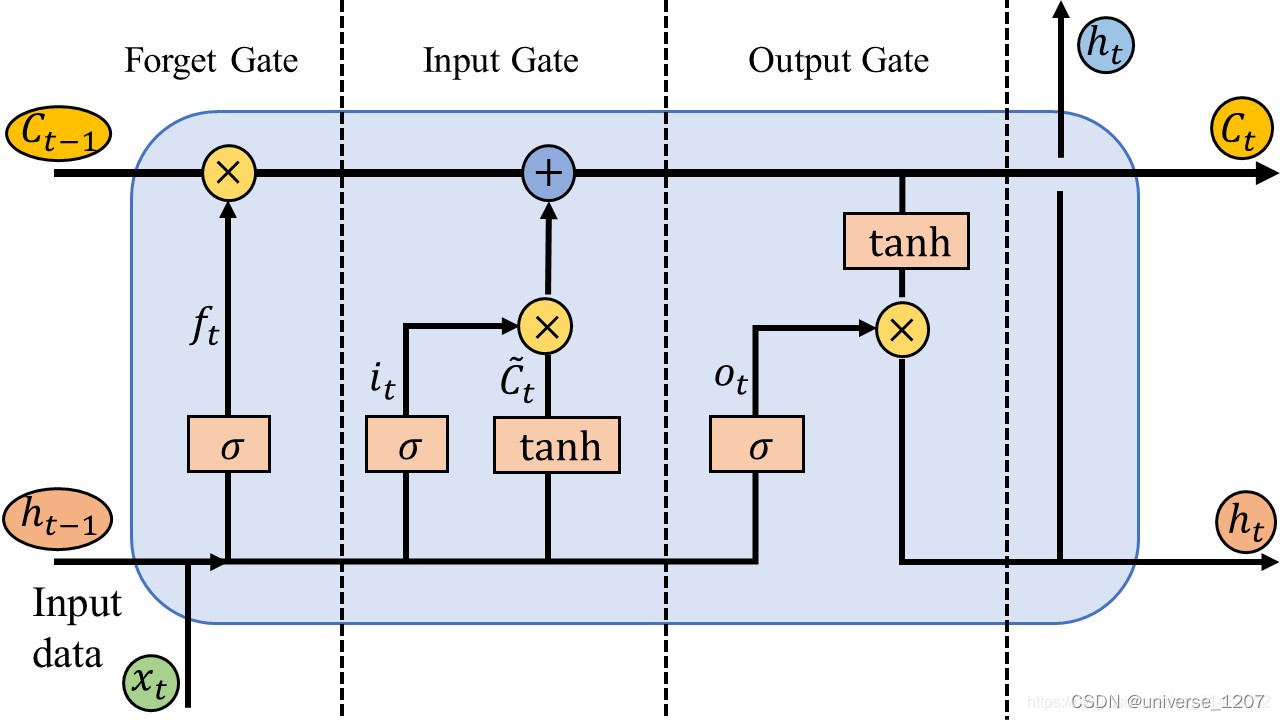
LSTM采用了门控输出的方式,即三门(输入门、遗忘门、输出门)两态(Cell State长时、Hidden State短时)。其核心即Cell State
-
-
遗忘门: f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_{t}=\sigma\left(W_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right) ft=σ(Wf⋅[ht−1,xt]+bf)
-
输入门: i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_{t}=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right) it=σ(Wi⋅[ht−1,xt]+bi) C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) \tilde{C}_{t}=\tanh \left(W_{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right) C~t=tanh(WC⋅[ht−1,xt]+bC)以及t时刻cell的状态(长时): C t = f t ⋅ C t − 1 + i t ⋅ C ~ t C_{t}=f_{t} \cdot C_{t-1}+i_{t} \cdot \tilde{C}_{t} Ct=ft⋅Ct−1+it⋅C~t
-
输出门: o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_{t}=\sigma\left(W_{o} \cdot\left[h_{t-1}, x_{t}\right]+b_{o}\right) ot=σ(Wo⋅[ht−1,xt]+bo) h t = o t ⋅ tanh ( C t ) h_{t}=o_{t} \cdot \tanh \left(C_{t}\right) ht=ot⋅tanh(Ct)
-
这里的 f t , i t , C t ⋯ f_t,i_t,C_t\cdots ft,it,Ct⋯的维数都是hidden_size(cell个数) × 1 \times 1 ×1
-
https://www.wangt.cc/2021/12/lstm%E6%80%BB%E7%BB%93%E7%AC%94%E8%AE%B0/
-
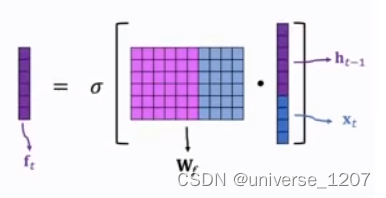
要注意,以上都是将 h t − 1 与 x t h_{t-1}与x_t ht−1与xt拼接起来的,但它本来应该是这样的
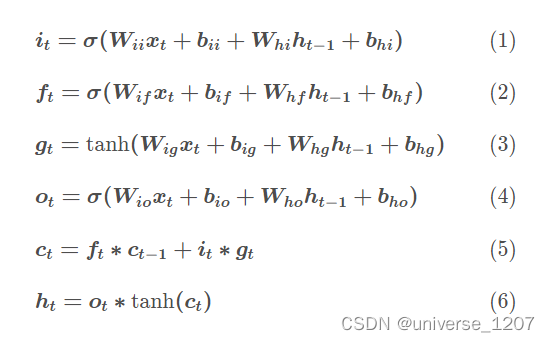
-
为什么要提到这个呢?因为不同的深度学习框架学习的参数是不一样的,后面计算参数那部分会说
LSTM参数计算
- 首先,经过个人实践,发现keras和pytorch的计算有一点点差异,原因就在上面说的h,x拼接那,拼接了之后偏置就只按合并的一个算,先看采取拼接的keras
- 其实要计算的就三个公式的 σ \sigma σ和一个 t a n h tanh tanh的参数,这里的参数都不是共享的哦,都不一样,只要计算一个的,再×4即可
- 先看一个的:
- 所以参数公式记为: ( d h + d x ) × d h + d h ( 这 是 偏 置 ) (d_h+d_x)\times d_h+d_h(这是偏置) (dh+dx)×dh+dh(这是偏置)
- 该层所有参数为: 4 [ ( d h + d x ) × d h + d h ] 4[(d_h+d_x)\times d_h+d_h] 4[(dh+dx)×dh+dh]
- pytorch版本/paddle版本则是 d h × d h + d x × d h + 2 d h d_h\times d_h+d_x\times d_h+2d_h dh×dh+dx×dh+2dh
- 所有参数为: 4 [ ( d h + d x ) × d h + 2 d h ] 4[(d_h+d_x)\times d_h+2d_h] 4[(dh+dx)×dh+2dh]
















 3592
3592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











