








 该专栏为热销专栏榜 第67名
该专栏为热销专栏榜 第67名 超级会员免费看
超级会员免费看

 知识图谱作为一种揭示实体间关系的语义网络,起源于Google的Knowledge Graph,通过信息抽取、知识融合和知识加工构建。它在智能搜索、问答、推荐系统等领域广泛应用,支持企业实现智能商业、工业4.0的智能工厂。知识图谱的架构包括逻辑架构和技术架构,涉及实体、关系、属性的存储和计算。随着深度学习的发展,知识图谱在AI应用中扮演着重要角色,成为连接感知和认知的关键。未来,知识图谱将进一步推动智能服务的创新和落地应用。
知识图谱作为一种揭示实体间关系的语义网络,起源于Google的Knowledge Graph,通过信息抽取、知识融合和知识加工构建。它在智能搜索、问答、推荐系统等领域广泛应用,支持企业实现智能商业、工业4.0的智能工厂。知识图谱的架构包括逻辑架构和技术架构,涉及实体、关系、属性的存储和计算。随着深度学习的发展,知识图谱在AI应用中扮演着重要角色,成为连接感知和认知的关键。未来,知识图谱将进一步推动智能服务的创新和落地应用。
关键词:基于行为的学习,基于知识的学习,商业智能,工业4.0,知识图谱,企业图谱, 图数据库, 图计算引擎, 数据可视化
应用场景:征信、风控、问答、医疗、能源、舆情、反欺诈、市场营销、社交网络、企业关系等数据关系丰富的业务场景。
特征:千亿级节点关系的存储和计算,准实时响应节点搜索、多跳查询、最短路径分析等在线查询操作。支持PageRank、社群发现、相似度计算、模糊子图匹配等离线计算。
起源
2012 年 5 月 17 日,Google 正式提出了知识图谱(Knowledge Graph)的概念,其初衷是为了优化搜索引擎返回的结果,增强用户搜索质量及体验。2013年以后开始在学术界和业界普及。
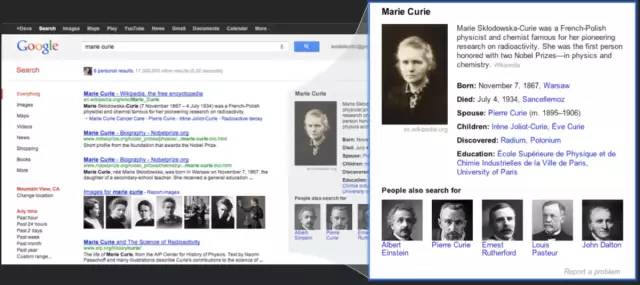
We hope this added intelligence will give you a more complete p

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











