







不同于一般的介绍Linux Shell 的文章,本文并未花大篇幅去介绍 Shell 语法,而是以面向“对象” 的方式引入大量的实例介绍 Shell 日常操作,“对象” 涵盖数值、逻辑值、字符串、文件、进程、文件系统等。这样有助于学以致用,并在用的过程中提高兴趣。也可以作为 Shell 编程索引,在需要的时候随时检索。
1. 什么是 Shell ?
首先让我们从下图看看 Shell 在整个操作系统中所处的位置吧,该图的外圆描述了整个操作系统(比如 Debian/Ubuntu/Slackware 等),内圆描述了操作系统的核心(比如 Linux Kernel),而 Shell 和 GUI 一样作为用户和操作系统之间的接口。
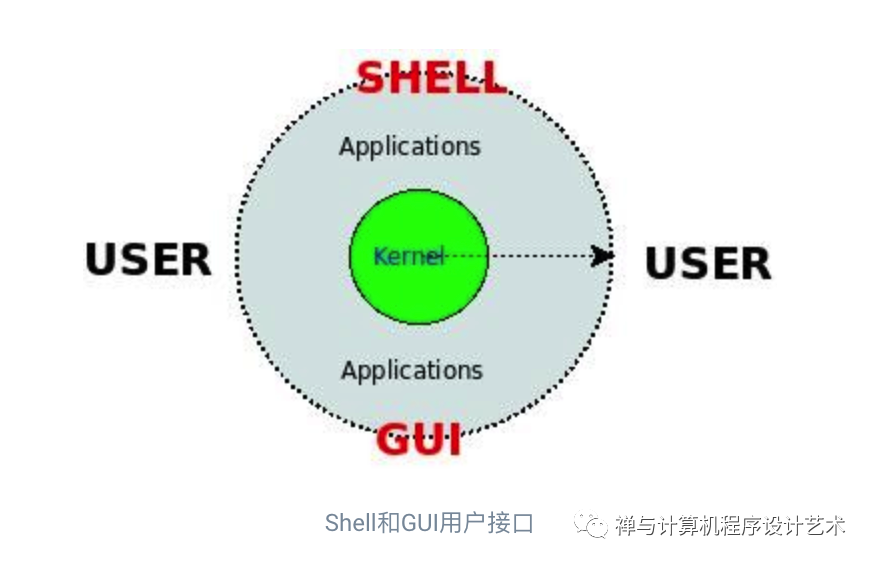
GUI 提供了一种图形化的用户接口,使用起来非常简便易学;而 Shell 则为用户提供了一种命令行的接口,接收用户的键盘输入,并分析和执行输入字符串中的命令,然后给用户返回执行结果,使用起来可能会复杂一些,但是由于占用的资源少,而且在操作熟练以后可能会提高工作效率,而且具有批处理的功能,因此在某些应用场合还非常流行。
Shell 作为一种用户接口,它实际上是一个能够解释和分析用户键盘输入,执行输入中的命令,然后返回结果的一个解释程序(Interpreter,例如在 linux 下比较常用的 Bash),我们可以通过下面的命令查看当前的 Shell :
$ echo $SHELL
/bin/bash
$ ls -l /bin/bash
-rwxr-xr-x 1 root root 702160 2008-05-13 02:33 /bin/bash该解释程序不仅能够解释简单的命令,而且可以解释一个具有特定语法结构的文件,这种文件被称作脚本(Script)。
既然该程序可以解释具有一定语法结构的文件,那么我们就可以遵循某一语法来编写它,它有什么样的语法,如何运行,如何调试呢?下面我们以 Bash 为例来讨论这几个方面。
搭建运行环境为了方便后面的练习,我们先搭建一个基本运行环境:在一个 Linux 操作系统中,有一个运行有 Bash 的命令行在等待我们键入命令,这个命令行可以是图形界面下的 Terminal (例如 Ubuntu 下非常厉害的 Terminator),也可以是字符界面的 Console (可以用 CTRL+ALT+F1~6 切换),如果你发现当前 Shell 不是 Bash,请用下面的方法替换它:
$ chsh $USER -s /bin/bash
$ su $USER或者是简单地键入Bash:
$ bash
$ echo $SHELL # 确认一下
/bin/bash如果没有安装 Linux 操作系统,也可以考虑使用一些公共社区提供的 Linux 虚拟实验服务,一般都有提供远程 Shell,你可以通过 Telnet 或者是 Ssh 的客户端登录上去进行练习。
有了基本的运行环境,那么如何来运行用户键入的命令或者是用户编写好的脚本文件呢 ?
假设我们编写好了一个 Shell 脚本,叫 test.sh 。
第一种方法是确保我们执行的命令具有可执行权限,然后直接键入该命令执行它:
$ chmod +x /path/to/test.sh
$ /path/to/test.sh第二种方法是直接把脚本作为 Bash 解释器的参数传入:
$ bash /path/to/test.sh
或
$ source /path/to/test.sh
或
$ . /path/to/test.sh
基本语法介绍
先来一个 Hello, World 程序。
下面来介绍一个 Shell 程序的基本结构,以 Hello, World 为例:
#!/bin/bash -v
# test.sh
echo "Hello, World"把上述代码保存为 test.sh,然后通过上面两种不同方式运行,可以看到如下效果。
方法一:
$ chmod +x test.sh
$ ./test.sh
./test.sh
#!/bin/bash -v
echo "Hello, World"
Hello, World方法二:
$ bash test.sh
Hello, World
$ source test.sh
Hello, World
$ . test.sh
Hello, World我们发现两者运行结果有区别,为什么呢?这里我们需要关注一下 test.sh 文件的内容,它仅仅有两行,第二行打印了 Hello, World,两种方法都达到了目的,但是第一种方法却多打印了脚本文件本身的内容,为什么呢?
原因在该文件的第一行,当我们直接运行该脚本文件时,该行告诉操作系统使用用#! 符号之后面的解释器以及相应的参数来解释该脚本文件,通过分析第一行,我们发现对应的解释器以及参数是 /bin/bash -v,而 -v 刚好就是要打印程序的源代码;但是我们在用第二种方法时没有给 Bash 传递任何额外的参数,因此,它仅仅解释了脚本文件本身。
Shell 程序设计过程Shell 语言作为解释型语言,它的程序设计过程跟编译型语言有些区别,其基本过程如下:
设计算法
用 Shell 编写脚本程序实现算法
运行脚本程序
可见它没有编译型语言的"麻烦的"编译和链接过程,不过正是因为这样,它出错时调试起来不是很方便,因为语法错误和逻辑错误都在运行时出现。下面我们简单介绍一下调试方法。
Shell 语言作为一门解释型语言,可以使用大量的现有工具,包括数值计算、符号处理、文件操作、网络操作等,因此,编写过程可能更加高效,但是因为它是解释型的,需要在执行过程中从磁盘上不断调用外部的程序并进行进程之间的切换,在运行效率方面可能有劣势,所以我们应该根据应用场合选择使用 Shell 或是用其他的语言来编程。
2 UNIX 程序设计
什么是 Shell Script 脚本 ?
Shell 是用户访问 Unix 操纵系统的接口。它接收用户的输入,然后基于该输入执行程序。程序执行完后,结果会显示在显示器上。
Shell 就是运行指令、程序和 Shell 脚本的运行环境。就和操作系统可以有很多种类一样,Shell 也有很多种。每一种 Shell 都有其特定的指令和函数集。
Shell 提示符
提示符 $ 被称为命令提示符。当显示命令提示符后,用户就可以键入命令。
Shell 在用户按 Enter 键后,从用户输入设备读入输入信息,它通过查看用户输入的第一个单词,来获知用户想要执行的命令。一个字即使字符不分割组成的字符串,一般是空格和制表符分割字。
下面是在显示器上显示当前日期和时间的 date 指令的例子:
$date
Thu Jun 25 08:30:19 MST 2009用户也可以定制自己喜欢的命令提示符,方法是改变环境变量 PS1。
Shell 类型
Unix 系统中有两种主要的 shell:
Bourne shell:如果用户使用 bourne shell,默认命令提示符是
$。C shell:如果用户使用 bourne shell,默认命令提示符是
%。
Bourne shell 也有如下几种子分类:
Bourne shell ( sh)
Korn shell ( ksh)
Bourne Again shell ( bash)
POSIX shell ( sh)
C shell不同的类型如下:
C shell ( csh)
TENEX/TOPS C shell ( tcsh)
最初的 UNIX Shell 是 Stephen R. Bourne 在 1970 年代中期写的。当时,他在新泽西的 AT&T 贝尔实验室工作。
Bourne shell是第一个出现在 Unix 系统中的 shell,因此它被称为标准的“shell”。
Bourne shell通常是安装在大多数版本的 Unix 中的 /bin/sh 目录。由于这个原因,在不同版本的 Unix 上也会选择这种 Shell 来编写脚本。
在本教程中,我们将覆盖 Bourne shell 中的大部分概念。
Shell 脚本
Shell 脚本的主要形式就是一系列的命令,这些命令会顺序执行。良好风格的 Shell 会有相应的注释。
Shell 脚本有条件语句(A 大于 B)、循环语句、读取文件和存储数据、读取变量且存储数据,当然,Shell 脚本也包括函数。
Shell 脚本和函数都是翻译型语言,所以他们并不会被编译。
在后面的部分,我们会尝试写一些脚本。他们是一些写有命令的简单文本文件。
脚本例子
假设我们创建一个名为 test.sh 的脚本。注意所有脚本的后缀名都必须为 .sh。假设之前,用户已经往里面添加了一些命令,下面就是要启动这个脚本。例子如下:
#!/bin/sh这个命令告诉系统,后面的是 bourne shell它应念成 shebang,因为 # 被称为 hash,!称为 bang
为了创建包含这些指令的脚本,用户需要先键入 shebang 行,然后键入指令:
#!/bin/bash
pwd
lsShell 注释
可以像下面一样来为脚本添加注释:
#!/bin/bash
# Author : Zara Ali
# Copyright (c) Tutorialspoint.com
# Script follows here:
pwd
ls现在用户已经保存了上述内容,然后就可以执行了:
$chmod +x test.sh执行脚本方式如下:
$./test.sh这会输出如下结果:
/home/amrood
index.htm unix-basic_utilities.htm unix-directories.htm
test.shunix-communication.htmunix-environment.htm注意:如果想要执行当前目录下的脚本,需要使用如下方式 ./program_name
扩展的 Shell 脚本:
Shell 脚本有几个构造告诉 Shell 环境做什么和什么时候去做。当然,大多数脚本比上面复杂得多。
毕竟,Shell 是一种真正的编程语言,它可以有变量,控制结构等等。无论多么复杂的脚本,它仍然只是一个顺序执行的命令列表。
以下脚本使用 read 命令从键盘输入并分配给变量 PERSON,最后打印 STDOUT。
#!/bin/sh
# Author : Zara Ali
# Copyright (c) Tutorialspoint.com
# Script follows here:
echo "What is your name?"
read PERSON
echo "Hello, $PERSON"下面是运行该脚本的例子:
$./test.sh
What is your name?
Zara Ali
Hello, Zara Ali
$变量
变量就是被赋值后的字符串。那个赋给变量的值可以是数字、文本、文件名、设备或其他类型的数据。
本质上,变量就是执行实际数据的指针。Shell 可以创建、赋值和删除变量。
变量名
变量名仅能包含字母、数字或者下划线。
约定俗成的,UNIX Shell 的变量名都使用大写。
下面是一些有效的变量名的例子:
_ALI
TOKEN_A
VAR_1
VAR_2下面是一些无效的变量名的例子:
2_VAR
-VARIABLE
VAR1-VAR2
VAR_A!不能使用!、*、-等字符的原因是,这些字符在 Shell 中有特殊用途。
定义变量
变量可以按照如下方式来定义:
variable_name=variable_value比如:
NAME="Zara Ali"上述例子定义了变量 NAME,然后赋值 "Zara Ali".这种类型的变量是常规变量,这种变量一次只能赋值一个。
Shell 可以随心所欲的赋值。比如:
VAR1="Zara Ali"
VAR2=100访问变量
为了获取存储在变量内的值,需要在变量名前加 $.
比如,下面的脚本可以访问变量 NAME 中的值,然后将之打印到 STDOUT:
#!/bin/sh
NAME="Zara Ali"
echo $NAME会出现下面的值:
Zara Ali只读变量
Shell 使用只读命令提供了使变量只读化的功能。这样的变量,都不能被改变。
比如,下面的脚本中,对变量 NAME 的值进行修改,系统会报错:
#!/bin/sh
NAME="Zara Ali"
readonly NAME
NAME="Qadiri"会出现如下结果:
/bin/sh: NAME: This variable is read only.删除变量
变量的删除会告诉 Shell 从变量列表中删除变量从而,无法对其进行跟踪。一旦用户删除了一个变量,将无法访问存储在变量中。
下面是使用 unset 指令的例子:
unset variable_name上述指令会取消已定义变量。下面是简单的例子:
#!/bin/sh
NAME="Zara Ali"
unset NAME
echo $NAME上述例子不会显示任何信息,不能使用 unset 指令取消被标记为只读模式的变量。
变量类型
Shell 脚本被执行的时候,主要存在如下三种变量类型:
局部变量:该类型变量只会在当前 Shell 实例内有效。他们无法适用于由 Shell 启动的程序。他们仅在命令提示符处进行设置。
环境变量:环境变量对 Shell 的任何子进程都有效。部分程序是需要正确的调用函数才需要环境变量。通常,Shell 脚本只会定义程序运行需要的环境变量。
Shell 变量:该类型变量是由 Shell 设置的专用变量,是用来正确调用函数用的。有时这些变量是环境变量,有时是局部变量。
特殊变量
之前的教程就在命名变量时,使用某些非字符数值作为字符变量名提出警告。这是因为这些字符用于作为特殊的 UNIX 变量的名称。这些变量是预留给特定功能的。
例如,$ 字符代表进程的 ID 码,或当前 Shell 的 PID:
$echo $$以上命令将输出当前 Shell 的 PID:
29949下面的表列出了一些特殊变量,可以在你的 Shell 脚本中使用它们:
| 变量 | 描述 |
|---|---|
| $0 | 当前脚本的文件名。 |
| $n | 这些变量对应于调用一个脚本时的参数。n 是一个十进制正整数,对应于特定参数的位置(第一个参数是 $1,第二个参数是 $2 等等)。 |
| $# | 提供给脚本的参数数量。 |
| $* | 所有的参数都表示两个引用。如果一个脚本接收了两个参数,即 $* 相当于 $1 $2。 |
| $@ | 所有的参数都是两个单独地引用。如果一个脚本接收了两个参数,即 $@ 相当于 $1 $2。 |
| $? | 执行最后一个命令的退出态。 |
| $$ | 当前 shell 的进程号。对于 shell 脚本,即他们正在执行的进程的 ID。 |
| $! | 最后一个后台命令的进程号。 |
命令行参数
命令行参数 $1,$2,$3,……$9 是位置参数,$0 指向实际的命令,程序,shell 脚本或函数。$1,$2,$3,……$9 作为命令的参数。
以下脚本使用与命令行相关的各种特殊变量:
#!/bin/sh
echo "File Name: $0"
echo "First Parameter : $1"
echo "Second Parameter : $2"
echo "Quoted Values: $@"
echo "Quoted Values: $*"
echo "Total Number of Parameters : $#"这是一个运行上述脚本的示例:
$./test.sh Zara Ali
File Name : ./test.sh
First Parameter : Zara
Second Parameter : Ali
Quoted Values: Zara Ali
Quoted Values: Zara Ali
Total Number of Parameters : 2特殊参数 $* 和 $@
存在一些特殊参数,使用它们可以访问所有的命令行参数。除非他们包含在双引号 "" 中,否则 $* 和 $@ 运行是相同的。
这两个参数都指定所有的命令行参数,但 $* 特殊参数将整个列表作为一个参数,各个值之间用空格隔开。而 $@ 特殊参数将整个列表分隔成单独的参数。
我们可以编写如下所示的 Shell 脚本,使用 $* 或 $@ 特殊参数来处理数量未知的命令行参数:
#!/bin/sh
for TOKEN in $*
do
echo $TOKEN
done作为示例,运行上述脚本:
$./test.sh Zara Ali 10 Years Old
Zara
Ali
10
Years
Old注意:这里 do……done 是一种循环,我们将在后续教程中介绍它。
退出态
$? 变量代表前面的命令的退出态。
退出态是每个命令在其完成后返回的数值。一般来说,大多数命令如果它们成功地执行,将 0 作为退出态返回,如果它们执行失败,则将 1 作为退出态返回。
一些命令由于一些特定的原因,会返回额外的退出状态。例如,一些命令为了区分不同类型的错误,将根据特定类型的失败原因返回各种不同的退出态值。
下面是一个成功命令的例子:
$./test.sh Zara Ali
File Name : ./test.sh
First Parameter : Zara
Second Parameter : Ali
Quoted Values: Zara Ali
Quoted Values: Zara Ali
Total Number of Parameters : 2
$echo $?
0
$数组
一个 Shell 变量只能够容纳一个值。这种类型的变量称为标量变量。
Shell 数组变量可以同时容纳多个值,它支持不同类型的变量。数组提供了一种变量集分组的方法。你可以使用一个数组变量存储所有其他的变量,而不是为每个必需的变量都创建一个新的名字。
Shell 变量中讨论的所有命名规则都将适用于命名数组。
定义数组值
一个数组变量和一个标量变量之间的差异可以解释如下。
假如你想描绘不同学生的名字,你需要命名一系列变量名作为一个变量集合。每一个单独的变量是一个标量变量,如下所示:
NAME01="Zara"
NAME02="Qadir"
NAME03="Mahnaz"
NAME04="Ayan"
NAME05="Daisy"我们可以使用一个数组来存储所有上面提到的名字。下面是创建一个数组变量的最简单的方法,将值赋给数组的一个索引。表示如下:
array_name[index]=value这里 array_name 是数组的名称,index 是数组中需要赋值的索引项,value 是你想要为这个索引项设置的值。
例如,以下命令:
NAME[0]="Zara"
NAME[1]="Qadir"
NAME[2]="Mahnaz"
NAME[3]="Ayan"
NAME[4]="Daisy"如果使用 ksh shell,数组初始化的语法如下所示:
set -A array_name value1 value2 ... valuen如果使用 bash shell,数组初始化的语法如下所示:
array_name=(value1 ... valuen)访问数组值
在为数组变量赋值之后,你可以访问它。如下所示:
${array_name[index]}这里 array_name 是数组的名称,index 是将要访问的值的索引。下面是一个最简单的例子:
#!/bin/sh
NAME[0]="Zara"
NAME[1]="Qadir"
NAME[2]="Mahnaz"
NAME[3]="Ayan"
NAME[4]="Daisy"
echo "First Index: ${NAME[0]}"
echo "Second Index: ${NAME[1]}"这将产生以下结果:
$./test.sh
First Index: Zara
Second Index: Qadir你可以使用以下方法之一,来访问数组中的所有项目:
${array_name[*]}
${array_name[@]}这里 array_name 是你感兴趣的数组的名称。下面是一个最简单的例子:
#!/bin/sh
NAME[0]="Zara"
NAME[1]="Qadir"
NAME[2]="Mahnaz"
NAME[3]="Ayan"
NAME[4]="Daisy"
echo "First Method: ${NAME[*]}"
echo "Second Method: ${NAME[@]}"这将产生以下结果:
$./test.sh
First Method: Zara Qadir Mahnaz Ayan Daisy
Second Method: Zara Qadir Mahnaz Ayan Daisy基本操作符
每一种 Shell 都支持各种各样的操作符。我们的教程基于默认的 Shell(Bourne),所以在我们的教程中涵盖所有重要的 Bourne Shell 操作符。
下面列出我们将讨论的操作符:
算术运算符。
关系运算符。
布尔操作符。
字符串运算符。
文件测试操作符。
最初的 Bourne Shell 没有任何机制来执行简单算术运算,它使用外部程序 awk 或者最简单的程序 expr。
下面我们用一个简单的例子说明,两个数字相加:
#!/bin/sh
val=`expr 2 + 2`
echo "Total value : $val"这将产生以下结果:
Total value : 4注意以下事项:
操作符和表达式之间必须有空格,例如 2+2 是不正确的,这里应该写成 2 + 2。
完整的表达应该封闭在两个单引号 '' 之间。
算术运算符
下面列出 Bourne Shell 支持的算术运算符。
假设变量 a 赋值为 10,变量 b 赋值为 20:
| 运算符 | 描述 | 例子 |
|---|---|---|
| + | 加法 - 将操作符两边的数加起来 | `expr $a + $b` = 30 |
| - | 减法 - 用操作符左边的操作数减去右边的操作数 | `expr $a - $b` = -10 |
| * | 乘法 - 将操作符两边的数乘起来 | `expr $a \* $b` = 200 |
| / | 除法 - 用操作符左边的操作数除以右边的操作数 | `expr $b / $a` = 2 |
| % | 取模 - 用操作符左边的操作数除以右边的操作数,返回余数 | `expr $b % $a` = 0 |
| = | 赋值 - 将操作符右边的操作数赋值给左边的操作数 | a=$b 将 b 的值赋给了 a |
| == | 相等 - 比较两个数字,如果相同,返回 true | [ $a == $b ] = false |
| != | 不相等 - 比较两个数字,如果不同,返回true。 | [ $a != $b ] = true |
这里需要非常注意是,所有的条件表达式和操作符之间都必须用空格隔开,例如 [$a == $b] 是正确的,而 [$a==$b] 是不正确的。
所有的算术计算都是针对长整数操作的。
关系运算符
Bourne Shell 支持以下的关系运算符,这些运算符是专门针对数值数据的。它们不会对字符串值起作用,除非他们的值是数值数据。
例如,下面的操作符将检查 10 和 20 之间的关系以及 “10” 和 “20” 的关系,但不能用于判断 “ten” 和 “twenty” 的关系。
假设变量 a 赋值为 10, 变量 b 赋值为 20:
| 运算符 | 描述 | 例子 |
|---|---|---|
| -eq | 检查两个操作数的值是否相等,如果值相等,那么条件为真。 | [ $a -eq $b ] is not true. |
| -ne | 检查两个操作数的值是否相等,如果值不相等,那么条件为真。 | [ $a -ne $b ] is true. |
| -gt | 检查左操作数的值是否大于右操作数的值,如果是的,那么条件为真。 | [ $a -gt $b ] is not true. |
| -lt | 检查左操作数的值是否小于右操作数的值,如果是的,那么条件为真。 | [ $a -lt $b ] is true. |
| -ge | 检查左操作数的值是否大于等于右操作数的值,如果是的,那么条件为真。 | [ $a -ge $b ] is not true. |
| -le | 检查左操作数的值是否小于等于右操作数的值,如果是的,那么条件为真。 | [ $a -le $b ] is true. |
这里需要非常注意是,所有的条件表达式和操作符之间都必须用空格隔开,例如 [$a <= $b] 是正确的,而 [$a<=$b] 是不正确的。
布尔操作符
Bourne Shell 支持以下的布尔操作符。
假设变量 a 赋值为 10, 变量 b 赋值为 20:
| 运算符 | 描述 | 例子 |
|---|---|---|
| ! | 这表示逻辑否定。如果条件为假,返回真,反之亦然。 | [ ! false ] is true. |
| -o | 这表示逻辑 OR。如果操作对象中有一个为真,那么条件将会是真。 | [ $a -lt 20 -o $b -gt 100 ] is true. |
| -a | 这表示逻辑 AND。如果两个操作对象都是真,那么条件才会为真,否则为假。 | [ $a -lt 20 -a $b -gt 100 ] is false. |
字符串运算符
Bourne Shell 支持以下字符串运算符。
假设变量 a 赋值为 "abc", 变量 b 赋值为 "efg":
示例说明
| 运算符 | 描述 | 例子 |
|---|---|---|
| = | 检查两个操作数的值是否相等,如果是的,那么条件为真。 | [ $a = $b ] is not true. |
| != | 检查两个操作数的值是否相等,如果值不相等,那么条件为真。 | [ $a != $b ] is true. |
| -z | 检查给定字符串操作数的长度是否为零。如果长度为零,则返回true。 | [ -z $a ] is not true. |
| -n | 检查给定字符串操作数的长度是否不为零。如果长度不为零,则返回true。 | [ -z $a ] is not false. |
| str | 检查字符串str是否是非空字符串。如果它为空字符串,则返回false。 | [ $a ] is not false. |
文件测试操作符
下列操作符用来测试与Unix文件相关联的各种属性。
假设一个文件变量 file,包含一个文件名 "test",文件大小是100字节,在其上有读、写和执行权限:
示例说明
| 运算符 | 描述 | 例子 |
|---|---|---|
| -b file | 检查文件是否为块特殊文件,如果是,那么条件为真。 | [ -b $file ] is false. |
| -c file | 检查文件是否为字符特殊文件,如果是,那么条件变为真。 | [ -c $file ] is false. |
| -d file | 检查文件是否是一个目录文件,如果是,那么条件为真。 | [ -d $file ] is not true. |
| -f file | 检查文件是否是一个不同于目录文件和特殊文件的普通文件,如果是,那么条件为真。 | [ -f $file ] is true. |
| -g file | 检查文件是否有组ID(SGID)设置,如果是,那么条件为真。 | [ -g $file ] is false. |
| -k file | 检查文件是否有粘贴位设置,如果是,那么条件为真。 | [ -k $file ] is false. |
| -p file | 检查文件是否是一个命名管道,如果是,那么条件为真。 | [ -p $file ] is false. |
| -t file | 检查文件描述符是否可用且与终端相关,如果是,条件为真实。 | [ -t $file ] is false. |
| -u file | 检查文件是否有用户id(SUID)设置,如果是,那么条件为真。 | [ -u $file ] is false. |
| -r file | 检查文件是否可读,如果是,那么条件为真。 | [ -r $file ] is true. |
| -w file | 检查文件是否可写,如果是,那么条件为真。 | [ -w $file ] is true. |
| -x file | 检查文件是否可执行,如果是,那么条件为真。 | [ -x $file ] is true. |
| -s file | 检查文件大小是否大于0,如果是,那么条件为真。 | [ -s $file ] is true. |
| -e file | 检查文件是否存在。即使文件是一个目录目录,只有存在,条件就为真。 | [ -e $file ] is true. |
决策
编写 Shell 脚本时,可能存在一种情况,你需要在两条路径中选择一条路径。所以你需要使用条件语句,确保你的程序做出正确的决策并执行正确的操作。
UNIX Shell 支持条件语句,这些语句基于不同的条件,用于执行不同的操作。在这里,我们将介绍以下两个决策语句:
if……else语句
case…… esac语句
if……else 语句:
if……else 语句是非常有用的决策语句,它可以用来从一个给定的选项集中选择一个选项。
Unix Shell 支持以下形式的 if……else 的语句:
if...fi statement
if...else...fi statement
if...elif...else...fi statement
大部分的 if 语句使用关系运算符检查关系,这部分知识在前一章已经讨论过。
case…… esac 语句
你可以使用多个 if……elif 语句执行一个多路分支。然而,这并不总是最好的解决方案,特别是当所有的分支都依赖于一个单一变量的值。
Unix Shell 支持 case……esac 语句,可以更确切地处理这种情况,它比重复 if……elif 语句更加有效。
case...esac 语句只有一种形式,详细说明如下:
case...esac statement
Unix Shell 的 case……esac 语句非常类似于 switch……case 语句,switch……case 语句在其他编程语言如 C 或 C++ 和 PERL 等中实现。
循环
循环是一个强大的编程工具,可以使您能够重复执行一系列命令。针对 Shell 程序员,有 4 种循环类型:
while 循环
for 循环
until 循环
select 循环
根据不同的情况使用不同的循环。例如只要给定条件仍然是 true,while 循环将执行给定的命令。而 until 循环是直到给定的条件变成 true,才会执行。
一旦你有了良好的编程实践,你就会开始根据情况使用适当的循环。while 循环和 for 循环在大多数其他编程语言如 C、C++ 和 PERL 等中都有实现。
嵌套循环
所有的循环都支持嵌套的概念,这意味着可以将一个循环放到另一个相似或不同的循环中。这个嵌套可以根据您的需求高达无限次。
下面是一个嵌套 while 循环的例子,基于编程的要求,其他循环类型也可以以类似的方式嵌套:
嵌套 while 循环
可以使用 while 循环作为另一个 while 循环体的一部分。
语法
while command1 ; # this is loop1, the outer loop
do
Statement(s) to be executed if command1 is true
while command2 ; # this is loop2, the inner loop
do
Statement(s) to be executed if command2 is true
done
Statement(s) to be executed if command1 is true
done例子
下面是循环嵌套的一个简单例子,在循环内部添加另一个倒计时循环,用来数到九:
#!/bin/sh
a=0
while [ "$a" -lt 10 ]# this is loop1
do
b="$a"
while [ "$b" -ge 0 ] # this is loop2
do
echo -n "$b "
b=`expr $b - 1`
done
echo
a=`expr $a + 1`
done这将产生以下结果。重要的是要注意 echo -n 是如何工作的。这里 -n 选项让输出避免了打印新行字符。
0
1 0
2 1 0
3 2 1 0
4 3 2 1 0
5 4 3 2 1 0
6 5 4 3 2 1 0
7 6 5 4 3 2 1 0
8 7 6 5 4 3 2 1 0
9 8 7 6 5 4 3 2 1 0循环控制
到目前为止你已经学习过创建循环以及用循环来完成不同的任务。有时候你需要停止循环或跳出循环迭代。
在本教程中你将学到以下语句用于控制 Shell 循环:
break 语句
continue 语句
无限循环
所有循环都有一个有限的生命周期。当条件为假或真时它们将跳出循环,这取决于这个循环。
一个循环可能会由于未匹配到适合得条件而无限执行。一个永远执行没有终止的循环会执行无数次。因此,这种循环被称为无限循环。
例子
这是一个使用 while 循环显示数字 0 到 9 的简单的例子:
#!/bin/sh
a=10
while [ $a -ge 10 ]
do
echo $a
a=`expr $a + 1`
done这个循环将永远持续下去,因为 a 总是大于或等于 10,它永远不会小于 10。所以这正是无限循环的一个恰当的例子。
break 语句
所有在 break 语句之前得语句执行结束后执行 break 语句,break 语句用于跳出整个循环。然后执行循环体后面的代码。然后在循环结束后运行接下来的代码。
语法
以下 break 语句将用于跳出一个循环:
breakbreak 语句也可以使用这种格式来退出嵌套循环式:
break n在这里 n 指定封闭循环执行的次数然后退出循环。
例子
这里是一个简单的例子,用来说明只要 a 变成 5 循环将终止:
#!/bin/sh
a=0
while [ $a -lt 10 ]
do
echo $a
if [ $a -eq 5 ]
then
break
fi
a=`expr $a + 1`
done这会产生以下结果:
0
1
2
3
4
5这里是一个简单的嵌套 for 循环的例子。如果 var1 等于 var2 以及 var2 等于 0 ,则这个脚本将跳出这个双重循环:
#!/bin/sh
for var1 in 1 2 3
do
for var2 in 0 5
do
if [ $var1 -eq 2 -a $var2 -eq 0 ]
then
break 2
else
echo "$var1 $var2"
fi
done
done这会产生以下结果。在内循环中,有一个 break 命令,其参数为 2。这表明,你应该打破外循环和内循环才能满足条件。
1 0
1 5continue 语句
continue 语句类似于 break 命令,二者不同之处在于,continue 语句用语结束当前循环,能引起当前循环的迭代的退出,而不是整个循环。
这个语句在当程序发生了错误,但你想执行下一次循环的时候是非常有用的。
语法
continue正如 break 语句,一个整型参数可以传递给 continue 命令以从嵌套循环中跳过命令。
continue n在这里 n 指定封闭循环执行的次数然后进入下一次循环。
例子
下面是使用 continue 语句的循环,它返回 continue 语句并且开始处理下一个语句:
#!/bin/sh
NUMS="1 2 3 4 5 6 7"
for NUM in $NUMS
do
Q=`expr $NUM % 2`
if [ $Q -eq 0 ]
then
echo "Number is an even number!!"
continue
fi
echo "Found odd number"
done这会产生以下结果:
Found odd number
Number is an even number!!
Found odd number
Number is an even number!!
Found odd number
Number is an even number!!
Found odd number替代
什么是替代?
当它遇到包含一个或多个特殊字符的表达式时 Shell 执行替代。
例
以下是一个例子,在这个例子中,变量被其真实值所替代。同时,“\n” 被替换为换行符:
#!/bin/sh
a=10
echo -e "Value of a is $a \n"这会产生以下结果。在这里 -e 选项可以解释反斜杠转义。
Value of a is 10下面是没有 -e 选项的结果:
Value of a is 10\n这里有以下转义序列可用于 echo 命令:
| Escape | Description |
|---|---|
| \\ | 反斜杠 |
| \a | 警报(BEL) |
| \b | 退格键 |
| \c | 抑制换行 |
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
默认情况下,你可以使用 -E 选项来禁用反斜线转义解释。
你你可以使用 -n 选项来禁用换行的插入。
命令替换:一种机制,通过它, Shell 执行给定的命令,然后在命令行替代他们的输出。
语法
当给出如下命令时命令替换就会被执行:
command当执行命令替换确保你使用反引号,而不是单引号字符。
例
命令替换一般是用来分配一个命令的输出变量。下面的示例演示命令替换:
#!/bin/sh
DATE=`date`
echo "Date is $DATE"
USERS=`who | wc -l`
echo "Logged in user are $USERS"
UP=`date ; uptime`
echo "Uptime is $UP"这会产生以下结果:
Date is Thu Jul 2 03:59:57 MST 2009
Logged in user are 1
Uptime is Thu Jul 2 03:59:57 MST 2009
03:59:57 up 20 days, 14:03, 1 user, load avg: 0.13, 0.07, 0.15变量代换
变量代换使 Shell 程序员操纵基于状态变量的值。
下面的表中是所有可能的替换:
| Form | Description |
|---|---|
| ${var} | 替代 var 的值 |
| ${var:-word} | 如果 var 为空或者没有赋值,word 替代 var。var 的值不改变。 |
| ${var:=word} | 如果 var 为空或者没有赋值, var 赋值为 word 的值。 |
| ${var:?message} | 如果 var 为空或者没有赋值,message 被编译为标准错误。这可以检测变量是否被正确赋值。 |
| ${var:+word} | 如果 var 被赋值,word 将替代 var。var 的值不改变。 |
例
以下是例子用来说明上述替代的各种状态:
#!/bin/sh
echo ${var:-"Variable is not set"}
echo "1 - Value of var is ${var}"
echo ${var:="Variable is not set"}
echo "2 - Value of var is ${var}"
unset var
echo ${var:+"This is default value"}
echo "3 - Value of var is $var"
var="Prefix"
echo ${var:+"This is default value"}
echo "4 - Value of var is $var"
echo ${var:?"Print this message"}
echo "5 - Value of var is ${var}"这会产生以下结果:
Variable is not set
1 - Value of var is
Variable is not set
2 - Value of var is Variable is not set
3 - Value of var is
This is default value
4 - Value of var is Prefix
Prefix
5 - Value of var is Prefix引用机制
元字符
UNIX Shell 提供有特殊意义的各种元字符,同时利用他们在任何 Shell 脚本,并导致终止一个字,除了引用。
举个例子,在列出文件中的目录时 ? 匹配一个一元字符,并且 * 匹配多个字符。下面是一个 Shell 特殊字符(也称为元字符)的列表:
* ? [ ] ' " \ $ ; & ( ) | ^ < > new-line space tab在一个字符前使用 \ ,它可能被引用(例如,代表它自己)。
例子
下面的例子,显示了如何打印 * 或 ? :
#!/bin/sh
echo Hello; Word这将产生下面的结果。
Hello
./test.sh: line 2: Word: command not found
shell returned 127现在,让我们尝试使用引用字符:
#!/bin/sh
echo Hello\; Word这将产生以下结果:
Hello; Word$ 符号是一个元字符,所以它必须被引用,以避免被 Shell 特殊处理:
#!/bin/sh
echo "I have \$1200"这将产生以下结果:
I have $1200是以下四种形式的引用:
| Quoting | Description |
|---|---|
| 单引号 | 所有在这些引号之间的特殊字符会失去它们特殊的意义 |
| 双引号 | 所有在这些引号之间的特殊字符会失去它们特殊的意义除了以下字符: - $ - ` - \$ - \' - \" -\\ |
| 反斜杠 | 任何直接跟在反斜杠后的字符会失去它们特殊的意义 |
| 反引号 | 所有在这些引号之间的特殊字符会被当做命令而被执行 |
单引号
考虑包含许多特殊的 Shell 字符的 echo 命令:
echo <-$1500.**>; (update?) [y|n]在每个特殊字符前加反斜杠会显得异常繁琐,并且不容易阅读:
echo \<-\$1500.\*\*\>\; \(update\?\) \[y\|n\]有一个简单的方法来引用一大组字符。将一个单引号(')放在字符串的开头和结尾:
echo '<-$1500.**>; (update?) [y|n]'单引号内的任何字符被引用正如每个字符前均加上一个反斜杠。所以,现在这个 echo 命令将正确地显示。
如果要输出的一个字符串内出现一个单引号,你不应该把整个字符串置于单引号内,相反你应该在单引号前使用反斜杠(\)如下:
echo 'It\'s Shell Programming'双引号
尝试执行以下 Shell 脚本。这个 Shell 脚本使用了单引号:
VAR=ZARA
echo '$VAR owes <-$1500.**>; [ as of (`date +%m/%d`) ]'这将输出以下结果:
$VAR owes <-$1500.**>; [ as of (`date +%m/%d`) ]所以这不是你想显示的内容。很明显,单引号防止变量替换。如果想替换的变量值和如预期那样使引号起作用,那么就需要把命令放置在双引号内,如下:
VAR=ZARA
echo "$VAR owes <-\$1500.**>; [ as of (`date +%m/%d`) ]"这将产生以下结果:
ZARA owes <-$1500.**>; [ as of (07/02) ]除以下字符外,双引号使所有字符的失去特殊含义:
$ 参数替代。
用于命令替换的反引号。
\$ 使美元标志在字面上显示。
\` 使反引号在字面上显示。
\" 启用嵌入式双引号。
\ 启用嵌入式反斜杠。
所有其他\字符在字面上显示(而不是特殊意义)。
单引号内的任何字符被引用正如每个字符前均加上一个反斜杠。所以,现在这个 echo 命令将正确地显示。
如果要输出的字符串内出现一个单引号,你不应该把整个字符串置于单引号内,相反你应该在单引号前使用反斜杠(\)如下:
echo 'It\'s Shell Programming'反引号
置于反引号之间的任何 Shell 命令将执行命令
语法
下面是一个简单的语法,把任何 Shell 命令置于反引号之间:
例子
var=`command`例子
下面将执行 date 命令,产生的结果将被存储在 DATA 变量中。
DATE=`date`
echo "Current Date: $DATE"这将输出以下结果:
Current Date: Thu Jul 2 05:28:45 MST 2009输入/输出重定向
大多数 UNIX 系统命令从你的终端接受输入并将所产生的输出发送回到您的终端。一个命令通常从一个叫标准输入的地方读取输入,默认情况下,这恰好是你的终端。同样,一个命令通常将其输出写入到标准输出,默认情况下,这也是你的终端。
输出重定向
一个命令的输出通常用于标准输出,也可以很容易地将输出转移到一个文件。这种能力被称为输出重定向:
如果记号 > file 添加到任何命令,这些命令通常将其输出写入到标准输出,该命令的输出将被写入文件,而不是你的终端:
检查下面的 who 命令,它将命令的完整的输出重定向在用户文件中。
$ who > users请注意,没有输出出现在终端中。这是因为输出已被从默认的标准输出设备(终端)重定向到指定的文件。如果你想检查 users 文件,它有完整的内容:
$ cat users
oko tty01 Sep 12 07:30
ai tty15 Sep 12 13:32
ruthtty21 Sep 12 10:10
pat tty24 Sep 12 13:07
steve tty25 Sep 12 13:03
$如果命令输出重定向到一个文件,该文件已经包含了一些数据,这些数据将会丢失。考虑这个例子:
$ echo line 1 > users
$ cat users
line 1
$您可以使用 >> 运算符将输出添加在现有的文件如下:
$ echo line 2 >> users
$ cat users
line 1
line 2
$输入重定向
正如一个命令的输出可以被重定向到一个文件中,所以一个命令的输入可以从文件重定向。大于号 > 被用于输出重定向,小于号 <用于重定向一个命令的输入。
通常从标准输入获取输入的命令可以有自己的方式从文件进行输入重定向。例如,为了计算上面 user 生成的文件中的行数,你可以执行如下命令:
$ wc -l users
2 users
$在这里,它产生的输出为 2 行。你可以通过从 user 文件进行 wc 命令的标准输入重定向:
$ wc -l < users
2
$请注意,两种形式的 wc 命令产生的输出是有区别的。在第一种情况下,用行数列出该文件的用户的名称,而在第二种情况下,它不是。
在第一种情况下,wc 知道,它是从文件用户读取输入。在第二种情况下,只知道它是从标准输入读取输入,所以它不显示文件名。
Here 文档
here document 被用来将输入重定向到一个交互式 Shell 脚本或程序。
在一个 Shell 脚本中,我们可以运行一个交互式程序,无需用户操作,通过提供互动程序或交互式 Shell 脚本所需的输入。
Here 文档的一般形式是:
command << delimiter
document
delimiter这里的 Shell 将 << 操作符解释为读取输入的指令,直到它找到含有指定的分隔符线。然后所有包含行分隔符的输入行被送入命令的标准输入。
分隔符告诉 Shell here 文档已完成。没有它,Shell 不断的读取输入。分隔符必须是一个字符且不包含空格或制表符。
以下是输入命令 wc -l 来进行计算行的总数:
$wc -l << EOF
This is a simple lookup program
for good (and bad) restaurants
in Cape Town.
EOF
3
$可以用 here document 编译多行,脚本如下:
#!/bin/sh
cat << EOF
This is a simple lookup program
for good (and bad) restaurants
in Cape Town.
EOF这将产生以下结果:
This is a simple lookup program
for good (and bad) restaurants
in Cape Town.下面的脚本用 vi 文本编辑器运行一个会话并且将输入保存文件在 test.txt 中。
#!/bin/sh
filename=test.txt
vi $filename <<EndOfCommands
i
This file was created automatically from
a shell script
^[
ZZ
EndOfCommands如果用 vim 作为 vi 来运行这个脚本,那么很可能会看到以下的输出:
$ sh test.sh
Vim: Warning: Input is not from a terminal
$运行该脚本后,你应该看到以下内容添加到了文件 test.txt 中:
$ cat test.txt
This file was created automatically from
a shell script
$丢弃输出
有时你需要执行命令,但不想在屏幕上显示输出。在这种情况下,你可以通过重定向到文件 /dev/null 以丢弃输出:
$ command > /dev/null在这里 command 是要执行的命令的名字。文件 /dev/null 是一个自动丢弃其所有的输入的特殊文件。
为了丢弃一个命令的输出和它的错误输出,你可以使用标准重定向来将 STDOUT 重定向到 STDERR :
$ command > /dev/null 2>&1在这里,2 代表 STDERR , 1 代表 STDOUT。可以上通过将 STDERR 重定向到 STDERR 来显示一条消息,如下:
$ echo message 1>&2重定向命令
以下是可以用来重定向的命令的完整列表:
| 命令 | 描述 |
|---|---|
| pgm > file | pgm 的输出被重定向到文件 |
| pgm < file | pgm 程序从文件度它的输入 |
| pgm >> file | pgm 的输出被添加到文件 |
| n > file | 带有描述符 n 的输出流重定向到文件 |
| n >> file | 带有描述符 n 的输出流添加到文件 |
| n >& m | 合并流 n 和 流 m 的输出 |
| n <& m | 合并流 n 和 流 m 的输入 |
| << tag | 标准输入从开始行的下一个标记开始。 |
| | | 从一个程序或进程获取输入,并将其发送到另一个程序或进程。 |
需要注意的是文件描述符 0 通常是标准输入(STDIN),1 是标准输出(STDOUT),2 是标准错误输出(STDERR)。
函数
函数允许你将一个脚本的整体功能分解成更小的逻辑子部分,然后当需要的时候可以被调用来执行它们各自的任务。
使用函数来执行重复性的任务是一个创建代码重用的很好的方式来。代码重用是现代面向对象编程的原则的重要组成部分。
Shell 函数类似于其他编程语言中的子程序和函数。
创建函数
声明一个函数,只需使用以下语法:
function_name () {
list of commands
}函数的名字是 function_name,在脚本的其它地方你可以用函数名调用它。函数名后必须加括号,在其后加花括号,其中包含了一系列的命令。
例子
以下是使用函数的简单例子:
#!/bin/sh
# Define your function here
Hello () {
echo "Hello World"
}
# Invoke your function
Hello当你想执行上面的脚本时,它会产生以下结果:
$./test.sh
Hello World
$函数的参数传递
你可以定义一个函数,在调用这些函数的时候可以接受传递的参数。这些参数可以由 $1,$2 等表示。
以下是一个例子,我们传递两个参数 Zara 和 Ali ,然后我们在函数中捕获和编译这些参数。
#!/bin/sh
# Define your function here
Hello () {
echo "Hello World $1 $2"
}
# Invoke your function
Hello Zara Ali这将产生以下结果:
$./test.sh
Hello World Zara Ali
$函数返回值
如果你从一个函数内部执行一个 exit 命令,不仅能终止函数的执行,而且能够终止调用该函数的 Shell 程序。
如果你只是想终止该函数的执行,有一种方式可以跳出定义的函数。
根据实际情况,你可以使用 return 命令从你的函数返回任何值,其语法如下:
return code这里的 code 可以是你选择的任何东西,但很明显,考虑到将脚本作为一个整体,你应该选择有意义的或有用的东西。
例子
下面的函数返回一个值 1:
#!/bin/sh
# Define your function here
Hello () {
echo "Hello World $1 $2"
return 10
}
# Invoke your function
Hello Zara Ali
# Capture value returnd by last command
ret=$?
echo "Return value is $ret"这将产生以下结果:
$./test.sh
Hello World Zara Ali
Return value is 10
$嵌套函数
函数更有趣的功能之一就是他们可以调用本身以及调用其他函数。调用自身的函数被称为递归函数。
下面简单的例子演示了两个函数的嵌套:
#!/bin/sh
# Calling one function from another
number_one () {
echo "This is the first function speaking..."
number_two
}
number_two () {
echo "This is now the second function speaking..."
}
# Calling function one.
number_one这将产生以下结果:
This is the first function speaking...
This is now the second function speaking...从 Prompt 函数调用
你可以把常用函数的定义放置到文件 .profile 中,这样当你载入的时候可以得到它们并且在 prompt 命令中使用它们。
或者,你可以将多个函数定义在一个文件中,比如 test.sh,然后通过键入以下内容当前 Shell 中执行该文件:
$. test.sh这样做可以使 test.sh 内定义的任何函数被读入,定义到当前 Shell ,如下:
$ number_one
This is the first function speaking...
This is now the second function speaking...
$要从 Shell 删除函数的定义,你可以使用带 .f 选项的 unset 命令。这也是用来删除 Shell 中一个变量的定义的命令。
$unset .f function_nameManpage 帮助
UNIX 命令都有许多可选的和强制性的选项,而忘记这些命令的完整语法是很常见的事情。
因为没有人能记住每个 UNIX 命令及其所有选项,所以在 UNIX 的最早版本中,用户就可以获得在线帮助。
UNIX 版本的帮助文件被称为 Manpage。如果你知道所有命令的名称,但你不知道如何使用它,这时 Manpage 可以在每一步中帮助你。
语法
UNIX 系统工作时,以下是获取 UNIX 命令细节的简单指令
$man command举例
你现在想象任何一个命令并且你需要得到与这个命令对应的帮助。假设你想知道 pwd 命令的用法,那么你只需要使用以下命令:
$man pwd上面的命令将打开一个帮助,它会给你提供关于 pwd 命令的完整的信息。自己试试根据你的命令提示符来获得更多的细节。
使用以下命令,你可以获得更详细的关于 man 命令的细节:
$man manMan Page 选项
Man Page通常被划分为不同的部分,而且由于不同 Man page 作者的偏好不同,划分情况也不一样。下面是一些常见的部分:
| 部分 | 描述 |
| 名称 | 命令的名字 |
| 描述 | 一般描述命令和他的作用 |
| 摘要 | 一般命令所使用的参数 |
| 选项 | 描述命令的所有参数和选项 |
| 另请参阅 | 列出其他的在 Manpage 中与该命令直接相关的命令或功能相似的命令 |
| 漏洞 | 描述存在于命令或输出中的问题或错误 |
| 例子 | 常见的用法示例,让读者了解如何使用命令。 |
| 作者 | Manpage 或其他命令的作者。 |
所以最后,我想说,当你需要使用 UNIX 命令或它的系统文件信息时, Man page 是一个至关重要的资源。
有用的 Shell 命令
下面的链接中给出了最重要和频繁使用 UNIX Shell命令列表。
如果你不知道如何使用命令,可以使用 Man page 获得命令的完整细节。
3 UNIX 进阶
正则表达式和 SED
正则表达式是一个字符串,可以用来描述几个字符序列。UNIX 的这些命令中会用到正则表达式,包括 ed、sed、awk、grep,以及 vi。
本教程将教你如何使用正则表达式和 sed。
这里 sed 代表的流编辑器是一个面向流的编辑器,是专门为执行脚本创建的。因此你的所有输入都会被送到 STDOUT 并且它不改变输入文件。
调用 sed
在我们开始之前,让我们以确保你有/etc/passwd文本文件的本地副本。
如前所述,可以通过一个 pipe 发送数据而调用s ed,如下所示:
$ cat /etc/passwd | sed
Usage: sed [OPTION]... {script-other-script} [input-file]...
-n, --quiet, --silent
suppress automatic printing of pattern space
-e script, --expression=script
...............................cat 命令转储 /etc/passwd 的内容到 sed 是通过 pipe 进入 sed 的模式空间。sed 使用模式空间的内部工作缓冲区来做它的工作。
sed 的一般语法:
下面是 sed 的一般语法
/pattern/action在这里,pattern 是一个正则表达式,action 则是在下表中给出的命令。当省 pattern 时,如上面我们已经看到的,action 会执行每一行命令。
围绕 pattern 的斜杠字符(/)是不可省略的,因为它们是作为分隔符使用。
| 范围 | 描述 |
| p | 输出该行 |
| d | 删除该行 |
| s/模式1/模式2/ | 替代第一次出现的模式1和模式2 |
用 sed 删除所有行
再次调用 sed ,但这一次使用 sed 的编辑命令删除一行记录,使用字母 d 表示其:
$ cat /etc/passwd | sed 'd'
$除了通过 pipe 发送一个文件来调用 sed,你可以指导 sed 从文件中读取数据,示例如下。
下面的命令与前面是完全一样的,尝试一下,里面不包括 cat 命令:
$ sed -e 'd' /etc/passwd
$sed地址
sed 也可以理解为所谓的地址。地址可以是文件中的一个位置,也可以是一个特殊的编辑命令适用的范围。当 sed 遇到没有地址的情况时,它会对文件中的每一行执行其操作。
下面的命令将一个基本的地址添加到您使用的 sed 命令中:
$ cat /etc/passwd | sed '1d' |more
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/sh
$注意,数字 1 添加在删除命令前面。这告诉 sed 在文件的第一行执行编辑命令。在这个例子中,sed将删除/etc/password文件的第一行并打印文件的其他部分。
sed 地址范围
所以如果你想从文件中删除一行,您可以指定一个地址范围如下:
$ cat /etc/passwd | sed '1, 5d' |more
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/sh
$以上命令应用的范围是 1 到 5 行。所以将删除这五行。
尝试以下地址范围:
| 范围 | 描述 |
| '4,10d' | 删除第 4 到 10 行 |
| '10,4d' | 只删除第 10 行,因为 sed 不能反方向工作 |
| '4,+5d' | 这将匹配文件中的第 4 行,删除这一行之后,继续删除下一个五行,然后停止其删除操作并输出其他行 |
| '2,5!d' | 这将删除除 2 到 5 行外的所有其他行。 |
| '1~3d' | 删除第一行后,跳过接下来的三行,然后删除第四行。sed 继续这种模式直到文件的末尾。 |
| '2~2d' | sed 删除第二行,跳过下一行后,删除下面的一行,并重复,直到到达文件的末尾。 |
| '4,10p' | 输出 4 到 10 行之间的内容。 |
| '4,d' | 产生语法错误。 |
| ',10d' | 也产生语法错误。 |
注意:在使用 p action 的时候,您应该使用 - n 选项来避免重复输出。检查以下两个命令的 betweek 差异:
$ cat /etc/passwd | sed -n '1,3p'上面的命令不加 - n 的情形如下:
$ cat /etc/passwd | sed '1,3p'替换命令
替换命令,用 s 表示,将取代你指定的任何其他字符串。
用一个字符串替代另一个,你需要告诉 sed 你第一个字符串的结束位置和想要替换的字符串的开始位置。传统上是由正斜杠(/)将两个字符串分开的。
以下命令将替换第一次出现的 root 和 amrood 字符串。
$ cat /etc/passwd | sed 's/root/amrood/'
amrood:x:0:0:root user:/root:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
..........................非常重要的一点是,sed 替代只在一个命令行的某一字符串第一次出现时才能使用。如果字符串 root 在一行里面出现不止一次,只有第一个 root 字符串被替换。
sed 去做一个全局替换,需要添加字母 g 到命令末尾,命令如下:
$ cat /etc/passwd | sed 's/root/amrood/g'
amrood:x:0:0:amrood user:/amrood:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
...........................替换标志
除了 g 标志外,还有许多其他有用的标志可以使用,而且您每次可以指定多余一个标志。
| 标志 | 描述 |
| g | 替换所有可以匹配的字符而不仅仅是第一个 |
| NUMBER | 仅仅替换第 NUMBLER 个匹配的字符 |
| p | 如果发生了替换,则输出模式空间 |
| w FILENAME | 如果发生了替换,则将结果写到 FILENAME |
| I or i | 以不区分大小写的方式匹配 |
| M or m | 除了拥有特殊正则表达式字符`^`和`$`的正常的行为外,这个标志使`^`匹配换行符后的空字符串,使$匹配换行符前的空字符串。 |
使用一个可替换的字符串分隔符
你会发现自己不得不对包含斜杠字符的字符串做一个替换。在这种情况下,您可以对 s 后的字符来指定一个不同的分隔符。
$ cat /etc/passwd | sed 's:/root:/amrood:g'
amrood:x:0:0:amrood user:/amrood:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/sh在上面的例子中:/ 作为定界符使用,而不是斜线/。因为我们试图搜索 /root,而不是简单的 root 字符串。
使用空串的执行替换
使用一个空的替换字符串去删除/etc/passwd文件的 root 字符串。
$ cat /etc/passwd | sed 's/root//g'
:x:0:0::/:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/sh地址替换
如果你想只在第 10 行用字符串 sh 替换字符串 quiet,你可以指定如下:
$ cat /etc/passwd | sed '10s/sh/quiet/g'
root:x:0:0:root user:/root:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/quiet同样的,做一个地址范围替换,你可以做如下操作:
$ cat /etc/passwd | sed '1,5s/sh/quiet/g'
root:x:0:0:root user:/root:/bin/quiet
daemon:x:1:1:daemon:/usr/sbin:/bin/quiet
bin:x:2:2:bin:/bin:/bin/quiet
sys:x:3:3:sys:/dev:/bin/quiet
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/sh正如你从输出所看到的,前五行里面的字符串 sh 都改为了 quiet,但是其他行里面的 sh 都丝毫没有改变。
匹配命令
你可以使用 p 参数和 - n 参数输出所有匹配的行,如下所示:
$ cat testing | sed -n '/root/p'
root:x:0:0:root user:/root:/bin/sh
[root@ip-72-167-112-17 amrood]# vi testing
root:x:0:0:root user:/root:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/sh使用正则表达式
在进行模式匹配时,您可以使用正则表达式,它提供了更多的灵活性。
检查下面的例子中以 daemon 开始的行然后删除:
$ cat testing | sed '/^daemon/d'
root:x:0:0:root user:/root:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/bin/sh
man:x:6:12:man:/var/cache/man:/bin/sh
mail:x:8:8:mail:/var/mail:/bin/sh
news:x:9:9:news:/var/spool/news:/bin/sh
backup:x:34:34:backup:/var/backups:/bin/sh下面是将删除以 sh 结尾的所有行的例子:
$ cat testing | sed '/sh$/d'
sync:x:4:65534:sync:/bin:/bin/sync下表列出了四个在正则表达式里面非常有用的特殊字符。
| 字符 | 描述 |
| ^ | 匹配一行的起始 |
| $ | 匹配一行的结尾 |
| . | 匹配任何的单个字符 |
| * | 匹配零个或多个以前出现的字符 |
| [chars] | 为了匹配任何字符串的字符。您可以使用`-`字符来表示字符的范围。 |
匹配字符
来看看在其他的表达式里面如何演示元字符的使用。例如下面的模式:
| 表达式 | 描述 |
| /a.c/ | 匹配包含字符串如a+c,a-c,abc, match, 还有 a3c |
| /a*c/ | 匹配相同的字符串还有字符串比如ace,yacc,以及arctic |
| /[tT]he/ | 匹配字符The和the |
| /^$/ | 匹配空白行 |
| /^.*$/ | 不管任何情况,都匹配一整行 |
| / */ | 匹配一个或多个空格 |
| /^$/ | 匹配空行 |
下表给出了一些常用的字符:
| 集 | 描述 |
| [a-z] | 匹配一个小写字母 |
| [A-Z] | 匹配一个大写字母 |
| [a-zA-Z] | 匹配一个字母 |
| [0-9] | 匹配数字 |
| [a-zA-Z0-9] | 匹配单个字母或数字 |
字符类关键词
通常来说,一些特殊的关键字对 regexp 来说也是适用的,尤其是 GNU 实用程序会使用 regexp。对 sed 正则表达式来说这些都是非常有用的,因为这样既简化了表达式又增强了可读性。
例如,字符 a 到 z 以及字符 A 到 Z 构成了这样一个用关键字[[:alpha:]]表示的类。
使用字母表的字符类关键词,这个命令输出/etc/syslog.conf文件里面以字母表的字母开始的行:
$ cat /etc/syslog.conf | sed -n '/^[[:alpha:]]/p'
authpriv.* /var/log/secure
mail.* -/var/log/maillog
cron.* /var/log/cron
uucp,news.crit /var/log/spooler
local7.* /var/log/boot.log下表是 GNU sed 的可用的字符类关键词的一个完整的列表。
| 字符类 | 描述 |
| [[:alnum:]] | 字母(a - z A-Z 0 - 9) |
| [[:alpha:]] | 字母(a - z A-Z) |
| [[:blank:]] | 空白字符(空格或制表键) |
| [[:cntrl:]] | 控制字符 |
| [[:digit:]] | 数字[0 - 9] |
| [[:graph:]] | 任何可见字符(不包括空格) |
| [[:lower:]] | 小写字母的[a -ž] |
| [[:print:]] | 可打印字符(无控字符) |
| [[:punct:]] | 标点字符 |
| [[:space:]] | 空白 |
| [[:upper:]] | 大写字母的[A -Z] |
| [[:xdigit:]] | 十六进制数字[0 - 9 a - f A-F] |
&引用
sed 元字符 & 代表被匹配的 pattern 的内容。例如,假设您有一个名为 phone.txt 的文件,里面都电话号码,如下所示:
5555551212
5555551213
5555551214
6665551215
6665551216
7775551217你想让前三个数字被括号括起来以更容易阅读。要做到这一点,您可以使用 & 替换字符,如下所示:
$ sed - e ' s / ^[[数位:]][[数位:]][[数位:]](&)/ g phone.txt
(555)5551212
(555)5551213
(555)5551214
(666)5551215
(666)5551216
(777)5551217先匹配 3 位数字,然后使用 & 取代那些括号括起来的数字。
使用多个 sed 命令
您可以在一个 sed 命令下使用多个 sed 命令,如下:
$ sed -e 'command1' -e 'command2' ... -e 'commandN' files这里 commandN 到 command1 都是我们之前讨论的 sed 类型命令。这些命令应用于每个文件列表的行。
以相同的机制,我们可以以下面的方式写上面的电话号码:
$ sed - e ' s / ^[[数位:]]\ \ { 3 } /(&)/ g \
- e ' s /)[[数位:]]\ \ { 3 } / & - / g phone.txt
(555)555 - 1212
(555)555 - 1213
(555)555 - 1214
(666)555 - 1215
(666)555 - 1216
(777)555 - 1217注意:在上面的例子中,不是重复字符类关键字[[:digit:]] 三次,而是代之以\{3\},这意味着前三次正则表达式相匹配。
引用
& 元字符是有用的,但更有用的功能是能够在正则表达式中定义特定区域,通过定义正则表达式的特定的一部分,您可以引用字符引用这部分。
反向引用时,你必须首先定义一个区域,然后回顾这个区域。定义一个区域是在你感兴趣的区域插入\和括号。你周围的第一区域被通过\ 1引用,第二个地区用 \ 2引用,等等。
假设 phone.txt 有以下文本:
(555)555 - 1212
(555)555 - 1213
(555)555 - 1214
(666)555 - 1215
(666)555 - 1216
(777)555 - 1217现在试试下面的命令:
$ cat phone.txt | sed 's/\(.*)\)\(.*-\)\(.*$\)/Area \
code: \1 Second: \2 Third: \3/'
Area code: (555) Second: 555- Third: 1212
Area code: (555) Second: 555- Third: 1213
Area code: (555) Second: 555- Third: 1214
Area code: (666) Second: 555- Third: 1215
Area code: (666) Second: 555- Third: 1216
Area code: (777) Second: 555- Third: 1217注意:在上面的例子中每个括号内的正则表达式将引用\ 1,,\ 2等等。
文件系统基础知识
文件系统是一个分区或磁盘上的文件的逻辑集合。一个分区是一个信息的容器,如果需要可以跨整个硬盘。
你的硬盘可以有不同的分区,但通常只包含一个文件系统,如一个文件系统涵盖 /file 系统,另一个包含 /home 文件系统。
一个文件系统分区允许不同文件系统的逻辑维护和管理。
UNIX 中一切都被认为是一个文件,包括物理设备,如 DVD-ROMs、USB 设备、软盘驱动器等等。
目录结构
UNIX 使用文件系统层次结构,就像一棵倒置的树,根目录(/) 是文件系统的底部,所有其他的目录都从那里蔓延。
UNIX 文件系统是文件和目录的集合,具有以下属性:
它有一个根目录 (/),包含其他的文件和目录。
使用名字唯一地标识每个文件或目录,这个名字可以是它所在的目录,或者一个独特的标识符,通常被称为一个 inode。
按照惯例,根目录的 inode 编号为 2,lost+found 目录的 inode 编号为 3。Inode 编号 0 和 1 暂不使用。文件的 inode 编号可以通过 ls 命令的 -i 选项指定。
它是自包含的。一个文件系统和其他文件系统之间没有依赖关系。
目录有特定的目的,通常存储相同类型的信息以实现更容易定位文件的目的。以下是主要的 UNIX 版本上存在的目录:
| 目录 | 描述 |
|---|---|
| / | 这是根目录,只包含顶层文件结构所需的目录。 |
| /bin | 这是可执行文件所在的地方。他们提供给所有用户使用。 |
| /dev | 这些是设备驱动程序。 |
| /etc | 上级目录的命令,配置文件,磁盘配置文件,有效的用户列表,组,以太网,主机等各种发送重要信息的地方。 |
| /lib | 包含共享库文件,例如其他内核相关文件。 |
| /boot | 包含系统启动相关的文件。 |
| /home | 包含用户的主目录和其他账户。 |
| /mnt | 用来挂载其他临时文件系统,比如分别针对光盘和软盘的 CD-ROM 驱动器和软盘驱动器。 |
| /proc | 标记为一个包含所有进程的文件,这些进程使用进程编号或其他信息标记。这个文件是一个动态的系统。 |
| /tmp | 包含系统启动期间所有的临时文件。 |
| /uer | 用于各种各样的用途,可以被许多用户使用。包括行政命令、共享文件、库文件等等。 |
| /var | 通常包含变长文件,如日志和打印文件和任何其他类型的文件,该文件包含的数据的量可能是变化的。 |
| /sbin | 包含二进制(可执行的)文件,通常用于系统管理。比如 fdisk 和 ifconfig 功能。 |
| /kernel | 包含内核文件。 |
浏览文件系统
既然已经了解了文件系统的基本知识,现在就可以开始导航到所需要的文件。以下列出导航到文件系统可以使用的命令:
| 命令 | 描述 |
|---|---|
| cat filename | 显示文件名。 |
| cd dirname | 移动到确定的目录。 |
| cp file1 file2 | 复制一个文件/目录到指定位置。 |
| file filename | 识别文件类型(二进制、文本等)。 |
| find filename dir | 发现一个文件/目录。 |
| head filename | 显示一个文件的开始。 |
| less filename | 从结束或开始位置浏览一个文件。 |
| ls dirname | 显示指定目录的内容。 |
| mkdir dirname | 创建指定目录。 |
| more filename | 从头到尾浏览一个文件。 |
| mv file1 file2 | 移动一个文件/目录的位置或重命名一个文件/目录。 |
| pwd | 显示用户当前所在的目录。 |
| rm filename | 删除一个文件。 |
| rmdir dirname | 删除一个目录。 |
| tail filename | 显示一个文件的结束。 |
| touch filename | 创建一个空白文件或修改现有文件的属性。 |
| whereis filename | 显示一个文件的位置。 |
| which filename | 如果文件在你的路径内,显示它的位置,。 |
df命令
管理分区空间的第一种方式是 df (磁盘空闲)命令。命令 df -k(磁盘空闲)以千字节的形式显示磁盘空间的使用情况,如下所示:
$df -k
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/vzfs10485760 7836644 2649116 75% /
/devices0 0 0 0% /devices
$一些目录,比如 /devices,以千字节形式显示使用为 0,且可用列以及能力都为 0%。这些特殊的(或虚拟的)文件系统,虽然他们驻留在磁盘上,但他们本身不占用磁盘空间。
在所有 UNIX 系统上 df -k 的输出通常都是相同的。它一般包括:
| 列 | 描述 |
|---|---|
| Filesystem | 物理文件系统名称。 |
| kbytes | 存储介质上的可用空间总字节。 |
| used | 被文件使用过的空间的总字节。 |
| avail | 可用空间的总字节。 |
| capacity | 被文件使用的空间和总额的比例。 |
| Mounted on | 文件系统正在安装的。 |
您可以使用 -h (可读的)选项来设置显示,使用易于理解的符号,合适的大小等输出格式。
du 命令
du (磁盘使用量) 命令使您能够按指定目录来显示一个特定的目录中磁盘空间的使用情况。
如果你想判断一个特定的目录正在使用多少空间,这个命令是很有用的。以下命令将显示被每个目录消耗的块的数量。根据系统的不同,一个块可能需要 512 字节或 1 千字节。
$du /etc
10 /etc/cron.d
126/etc/default
6 /etc/dfs
...
$-h 选项使输出更容易理解:
$du -h /etc
5k/etc/cron.d
63k /etc/default
3k/etc/dfs
...
$挂载文件系统
文件系统必须安装以用于系统的正常使用。为了查看您的系统上目前安装(可用)的文件系统,可以使用这个命令:
$ mount
/dev/vzfs on / type reiserfs (rw,usrquota,grpquota)
proc on /proc type proc (rw,nodiratime)
devpts on /dev/pts type devpts (rw)
$UNIX 协定的 /mnt 目录,就是临时挂载的地方(例如 CD-ROM 驱动器,远程网络驱动器,软盘驱动器)。如果你需要挂载文件系统,您可以使用 mount 命令,语法如下:
mount -t file_system_type device_to_mount directory_to_mount_to例如,如果你想挂载 CD-ROM 到目录 /mnt/cdrom,你可以输入:
$ mount -t iso9660 /dev/cdrom /mnt/cdrom假设您的 CD-ROM 设备称为 /dev/cdrom,你想挂载到 /mnt/cdrom。可以参考安装手册页获得更具体的信息或类型,在命令行输入 -h 得到帮助信息。
安装之后,您可以使用 cd 命令通过挂载点来浏览可用的新文件系统。
卸载文件系统
通过识别挂载点或设备,从你的系统中卸载(删除)文件系统。使用 umount 命令实行。
例如,可以使用以下命令卸载光盘:
$ umount /dev/cdrommount 命令使你能够访问你的文件系统,但在大多数现代 UNIX 系统中,加载函数使这个过程对用户不可见且不需要用户干预。
用户和组配额
提供用户和组配额的机制:单个用户或特定组中的所有用户所使用的空间量可以由管理员定义的值限制。
配额操作有两种限制。如果空间的数量或磁盘块的数量开始超过管理员定义的限制,允许用户采取行动:
软限制:如果用户超过限制的定义,有一个宽限度,允许用户释放一些空间。
硬限制:当达到硬限制使,忽略宽限度,没有进一步的文件或块可以分配。
有许多命令来管理配额:
| 命令 | 描述 |
|---|---|
| quota | 显示组中一个用户的磁盘使用情况和限制。 |
| edquota | 这是一个配额编辑器。可以使用这个命令编辑用户或组配额。 |
| quotacheck | 扫描文件系统,为了磁盘使用、制造、检查和修复配额文件 |
| setquota | 这也是一个命令行配额编辑器。 |
| quotaon | 系统宣布应该在一个或多个文件系统上启用磁盘配额。 |
| quotaoff | 系统宣布应该禁用一个或多个文件系统上的磁盘配额。 |
| repquota | 打印指定文件系统的磁盘使用和配额的汇总 |
您可以使用 Manpage 帮助 查看这里提到每个命令的完整语法。
用户管理
在 UNIX 系统中,有三种类型的账户:
root 帐户:这也被称为超级用户,这类用户对系统拥有完整的和不受约束的控制权。超级用户可以运行任何命令,而不受任何限制。这类用户应该承担作为一个系统管理员的任务。
系统账户:系统账户是为操作系统特定组件的需要提供的,例如邮件账户和 sshd 账户。这些账户通常是为了满足系统上一些特定的功能的需要而设定的,对它们进行的任何修改都可能会对系统造成负面影响。
用户帐号:用户帐户提供交互式访问系统的用户和用户组。通常给普通用户分配这些账户,通常附带有对关键系统文件和目录有限的访问权限。
UNIX 支持组帐号(Group Account)的概念,在逻辑上是许多账户的群组。每个帐户都可能是任何组账号的一部分。UNIX 组在处理文件权限和流程管理中发挥了重要的作用。
管理用户和组
下面列出三个主要的用户管理文件:
/etc/passwd:此文件保存用户帐户和密码信息。这个文件包含了 UNIX 系统上大多数的账户信息。
/etc/shadow:此文件包含相应帐户的加密密码。不是所有的系统都支持这个文件。
/etc/group:此文件包含每个帐户的组信息。
/etc/gshadow:此文件包含安全组帐号信息。
使用 cat 命令检查上述所有文件。
大多数 UNIX 系统可用以下命令来创建和管理帐户和组:
| 命令 | 描述 |
|---|---|
| useradd | 将账户添加到系统。 |
| usermod | 修改账户属性。 |
| userdel | 从系统删除账户。 |
| groupadd | 将组添加到系统。 |
| groupmod | 修改组属性。 |
| groupdel | 从系统中删除组。 |
可以使用 Manpage 帮助 查看这里提到每个命令的完整语法。
创建一个组
在创建任何账户之前需要先创建组,否则将不得不使用系统中现有的组。你会在 /etc/groups 文件中找到所有组的列表。
所有默认组都是系统帐户组成的特定组,不推荐普通账户使用。所以下面给出用来创建一个新组帐户的语法:
groupadd [-g gid [-o]] [-r] [-f] groupname下面列出详细的参数:
| 选项 | 描述 |
|---|---|
| -g GID | 组 ID 的数值。 |
| -o | 这个选项允许给组添加一个非唯一的 GID。 |
| -r | 这个标志表示给组添加一个系统账户。 |
| -f | 如果指定的组已经存在,这个选项会导致成功退出。附带 -g 时,如果指定 GID 已经存在,就选择其他(独特的) GID。 |
| groupname | 创建一个真实的组名称。 |
如果你没有指定任何参数,那么系统将使用默认值。
以下示例将使用默认值创建开发人员组,这为大部分的管理员接受。
$ groupadd developers修改组
修改一个组,使用 groupmod 语法:
$ groupmod -n new_modified_group_name old_group_name将 developers_2 组的名称改为 developer,例如:
$ groupmod -n developer developer_2下边描述如何将 developer 的 GID 更改为 545:
$ groupmod -g 545 developer删除一个组
删除现有的组,需要的所有东西就是 groupdel 命令和组名。例如删除 developer 组,命令是:
$ groupdel developer这个操作只是删除了组,而不涉及任何跟组相关的文件。这些文件仍然可以被它们的主人访问。
创建一个帐户
让我们看看如何在 UNIX 系统上创建一个新的帐户。下面是用来创建一个用户帐户的语法:
useradd -d homedir -g groupname -m -s shell -u userid accountname下面列出详细的参数:
| 选项 | 描述 |
|---|---|
| -d homedir | 指定账户的主目录。 |
| -g groupname | 指定该账户所属的组账户。 |
| -m | 如果它不存在,则创建主目录。 |
| -s shell | 指定该帐户的默认 shell。 |
| -u userid | 您可以为账户指定一个用户id。 |
| accountname | 创建一个真实的帐户名称 |
如果你没有指定任何参数,那么系统将使用默认值。useradd 命令将修改 /etc/passwd 文件、/etc/shadow 文件、/etc/group 文件并创建一个主目录。
下面的示例将创建一个帐户:mcmohd,主目录设置为 /home/mcmohd,组为 developers。将 Korn Shell 分配给这个用户。
$ useradd -d /home/mcmohd -g developers -s /bin/ksh mcmohd上面的命令执行之前,必须确保你已经使用 groupadd 命令创建了 developers 组。
创建一个帐户之后,你可以使用 passwd 命令设置它的密码,如下所示:
$ passwd mcmohd20
Changing password for user mcmohd20.
New UNIX password:
Retype new UNIX password:
passwd: all authentication tokens updated successfully.当您输入 passwd 账户名,它会假定你是超级用户,从而更改密码。否则你只能使用这样的命令改变你的密码,而不能更改指定帐户的密码。
修改一个账户
usermod 命令允许从命令行更改现有的账户。它使用和 useradd 命令相同的参数,加上 -l 参数,允许更改帐户名称。
例如,将账户名称 mcmohd 更改为 mcmohd20 并相应地改变主目录,需要执行以下命令:
$ usermod -d /home/mcmohd20 -m -l mcmohd mcmohd20删除一个账户
userdel 命令可以用来删除现有的用户。这是一个非常危险的命令,必须小心使用。
这个命令只有一个参数或可用的选项:.r,用来删除帐户的主目录和邮件文件。
例如,删除帐户 mcmohd20,需要发出以下命令:
$ userdel -r mcmohd20如果为了备份的目的,想保留它的主目录,省略 -r 选项。可以根据需要在稍后的时间删除主目录。
系统性能
本教程的目的是介绍一些可用的免费性能分析工具来对 UNIX 系统性能进行监控和管理,并提供了如何分析和解决 UNIX 环境中性能问题的指导。
UNIX 有以下需要进行监控和调整的主要资源类型:
CPU
内存
磁盘空间
通信线路
I/O 时间
网络时间
应用程序
性能组件
主要有以下五个组件,随着总系统时间的推移而变化:
| 组件 | 描述 |
|---|---|
| 用户状态 CPU | 在用户状态下,CPU 运行用户程序的所花费的时间。它包括用于执行库函数调用的时间,但是不包括自己在内核中花费的时间。 |
| 系统状态 CPU | 在系统状态下,CPU 花费在运行程序上的时间。所有的 I/O 例程均需要内核服务。程序员可以通过使用阻塞 I/O 传输来影响这个值。 |
| I/O 时间和网络时间 | 这些是花费在移动数据和 I/O 请求服务的时间 |
| 虚拟内存的性能 | 这包括了上下文的切换和交换。 |
| 应用程序 | 花费在运行其他程序的时间--系统没有为这个应用程序提供服务是因为另一个应用程序在当前状态下持有 CPU。 |
性能工具
UNIX 提供了以下重要工具来估量和调整 UNIX 系统的性能:
| 命令 | 描述 |
|---|---|
| nice/renice | 修改运行程序的调度优先级。 |
| netstat | 打印网络连接,路由表,接口状态,无效连接和多播成员。 |
| time | 测量一个普通命令的运行时间或资源的使用情况。 |
| uptime | 系统平均负载。 |
| ps | 显示当前进程的快照。 |
| vmstat | 显示虚拟内存信息的统计。 |
| gprof | 显示调用关系图资料。 |
| prof | 进程性能分析。 |
| top | 显示系统的任务。 |
系统日志
UNIX 系统有一个非常灵活和强大的日志系统,它让你能够记录几乎任何你能想象的东西,然后你可以操作日志来获取你需要的信息。
许多版本的 UNIX 提供了一个名为 syslog 的通用日志工具,有信息需要记录的单独程序要将信息发送到 syslog。
Unix syslog 是一个主机可配置的,统一的系统日志工具。该系统采用集中式的系统日志进程,其运行程序 /etc/syslogd 或者 /etc/syslog。
系统记录器的操作是相当简单的。程序发送日志条目到 syslogd,其将会在配置文件 /etc/syslogd.conf 或 /etc/syslog 中查找,当找到一个匹配后,将日志消息写入到期望的日志文件中。
现有你应该了解的四种基本日志术语:
| 术语 | 描述 |
|---|---|
| Facility | 此标识符用来描述提交的日志信息的应用程序或进程。例如邮件,内核和 FTP。 |
| Priority | 一个显示消息重要性的指示器。syslog 作为准则定义了消息的级别,从调试信息到关键事件。 |
| Selector | 一个或更多的 facility 和 level 的结合体 。当一个输入事件匹配一个 selector 时,一个 action 会被执行。 |
| Action | 传入的消息匹配 selector 时会发生的事情。Action 可以将消息写入日志文件,将消息回传到控制台或其他设备,将消息写入到一个登录用户,或将消息发送到另一个日志服务器。 |
Syslog Facilities
下面是 selector 可用的 facility。不是所有的 facility 都存在于所有版本的 UNIX。
| Facility | 描述 |
|---|---|
| auth | 需要用户名和密码的相关活动(getty,su,login) |
| authpriv | 类似于 auth 的认证,但是记录的文件只能被授权的用户读取。 |
| console | 用于捕获信息,这些信息一般会传向系统控制台。 |
| cron | 与 cron 系统有关的计划任务信息。 |
| daemon | 所捕获的所有系统守护进程信息。 |
| ftp | ftp 守护进程相关的信息。 |
| kern | 内核信息。 |
| local0.local7 | 用户自定义使用的本地信息。 |
| lpr | 与打印服务系统有关的信息。 |
| 与邮件系统相关的信息。 | |
| mark | 用于生产日志文件中时间戳的伪事件。 |
| news | 与网络新闻传输协议( nntp )有关的信息。 |
| ntp | 与网络时间协议有关的信息。 |
| user | 普通用户进程产生的信息。 |
| uucp | UUCP 子系统生成的信息。 |
Syslog 优先级
syslog 的优先级( Priority )如下表:
| Priority | 描述 |
|---|---|
| emerg | 紧急情况,如即将发生的系统崩溃,通常会广播到所有用户。 |
| alert | 需要立即修改的情况,如系统数据库的损坏。 |
| crit | 关键的情况,如一个硬件的错误。 |
| err | 普通错误。 |
| warning | 警告 |
| notice | 不是一个错误的情况,但是可能需要用特定方式的处理一下。 |
| info | 报告性的消息。 |
| debug | 用于调试程序的消息。 |
| none | 没有重要级别,通常用于指定非日志的消息。 |
facility 和 level 的组合能够让你辨别记录了什么和这些日志信息去哪儿了。
每个程序尽职尽责地向系统记录器发送消息,记录器基于 selector 定义的 level 决定跟踪什么和舍弃什么信息。
当你指定了一个 level,系统会记录这一 level 及更高 level 的一切信息。
文件 /etc/syslog.conf
文件 /etc/syslog.conf 用于配置记录消息的位置。一个典型的 syslog.conf 文件看起来应该像这样:
*.err;kern.debug;auth.notice /dev/console
daemon,auth.notice /var/log/messages
lpr.info /var/log/lpr.log
mail.* /var/log/mail.log
ftp.* /var/log/ftp.log
auth.* @prep.ai.mit.edu
auth.* root,amrood
netinfo.err /var/log/netinfo.log
install.* /var/log/install.log
*.emerg *
*.alert |program_name
mark.* /dev/console文件中的每一行包含两部分:
一个消息 selector,其指定了哪种消息用来记录。例如,内核的所有错误信息或所有调试信息。
一个 action,其指明了对接收的消息该怎么处理。例如,写入一个文件中或者将消息发送到用户的终端。
下面是上述配置的注意事项:
消息 selector 有两部分:facility 和 priority。例如, kern.debug 选择了所有由内核( facility )产生的的调试信息( priority )。
消息 selectetor kern.debug 选择了所有 priority 大于 debug 的信息。
在任何 facility 和 priority 位置上的星号,表示“所有”的意思。例如, *.debug 表示所有 facility 的调试信息,而 kern.* 表示内核所产生的所有信息。
你也可以用逗号来指定多个 facility。两个或两个以上的 selectetor 可以用分号组合在一起。
日志记录 Action
action 部分指定了下面五个 action 中的其中一个:
将信息记录到一个文件或设备。例如,
/var/log/lpr.log或者/dev/console。发送一个消息给一个用户。你可以用逗号分开指定多个用户名(例如,root,amrood)。
发送一个消息给所有用户。在这种情况下,action 部分包含了一个星号(例如,*)。
用管道发送消息到程序。在这种情况下,程序是在 UNIX 管道符号(|)后指定。
将消息发送到另一台主机上的 syslog。在这种情况下,action 部分包含了一个前面有 at 符号的主机名(例如,@jikexueyuan.com)。
logger 命令
UNIX 提供了 logger 命令,这是处理系统日志记录的一个非常有用的命令。logger 命令发送日志消息到 syslogd 守护进程,从而驱使系统记录日志。
这意味着我们可以随时用命令行检查 syslogd 守护进程及其配置。logger 命令提供了一种在命令行上添加一行条目到系统日志文件中的方法。
该命令的格式是:
logger [-i] [-f file] [-p priority] [-t tag] [message]...下面是具体的参数细节:
| 选项 | 描述 |
|---|---|
| -f filename | 使用文件 filename 的内容作为消息来记录。 |
| -i | 日志的每一行都记录进程的 id。 |
| -p priority | 指定输入消息的优先级 priority(指定的 selector),优先级 priority 可以是数字或者指定为 facility.level 对的格式。默认参数是 user.notice。 |
| -t tag | 用指定 tag 标记记录到日志中的每一行。 |
| message | 字符串参数,它的内容以特定顺序连接在一起,由空格分开。 |
日志轮换
日志文件有快速增长的特点,并消耗大量的磁盘空间。大多数 UNIX 发行版系统使用了工具(如 newsyslog 或 logrotate)启用日志轮换功能。
这些工具由 cron 守护进程在一个频繁的时间间隔里调用。你可以在 newsyslog 或 logrotate 的手册页中获取更多的细节内容。
重要日志文件的位置
所有的系统应用程序创建自己的日志文件在 /var/log 和它的子目录里。下面这里有几个重要的应用,其相应的日志目录:
| 应用 | 目录 |
|---|---|
| httpd | /var/log/httpd |
| samba | /var/log/samba |
| cron | /var/log/ |
| /var/log/ | |
| mysql | /var/log/ |
信号和 Traps
信号是发送给程序的软件中断,表明已发生的重要事件。这些事件的范围可以是从用户请求到非法内存访问错误。这些信号,如中断信号,表明用户要求程序做一些非一般流程控制下的事情。
以下是一些你可能会遇到的并且需要在程序中使用的常见信号:
| 信号名 | 信号值 | 描述 |
|---|---|---|
| SIGHUP | 1 | 控制终端意外终止或者是控制进程结束时发出 |
| SIGINT | 2 | 用户发送一个中断信号时发出(Ctrl+C)。 |
| SIGQUIT | 3 | 用户发送一个退出信号时发出(Ctrl+D)。 |
| SIGFPE | 8 | 当非法的数学操作执行时发出。 |
| SIGKILL | 9 | 一个进程获取到此信号,它必须立即退出,并且不能进行任何清除操作。 |
| SIGALRM | 14 | 时钟信号(用于定时器) |
| SIGTERM | 15 | 软件终止信号(kill 命令缺省产生此信号)。 |
信号列表
有一个简单的方法可以列出你的系统所支持的所有信号。仅仅用命令 kill -l 就可以显示系统所有支持的信号:
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL
5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE
9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2
13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT
17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU
25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH
29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN
35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4
39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12
47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14
51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10
55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6
59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAXSolaris, HP-UX 和 Linux 之间实际的信号列表会有所不同。
默认动作
每一个信号都有一个与之相随的默认动作。一个信号的默认动作是当脚本或程序接收到一个信号时,它的执行表现。
这些可能的默认动作是:
终止进程。
忽略信号。
内核映像转储。当收到信号时,此动作将创建一个称为 core 的文件,其包含进程的内存映像。
停止进程。
继续停止的进程。
发送信号
有几种向程序或者脚本传递信号的方法。其中用户最常见的是在正在运行的脚本的时候,按下 Ctrl+C 或者 INTERRUPT 键。
当你按下 Ctrl+C 键,信号 SIGINT 被发送到脚本中,根据之前定义的默认动作,脚本将会被终止。
另外一种常见的传送信号的方法是使用 kill 命令,其语法如下所示:
$ kill -signal pid这里的 signal 要么是信号值,要么是信号名称。 pid 是信号要发送到的进程的 ID。 例如:
$ kill -1 1001发送 HUP 信号(即意外终止信号)到运行进程 ID 为 1001 的程序。 用下面的命令来发送一个 kill 信号到同样的进程:
$ kill -9 1001这条命令会杀死运行进程 ID 为 1001 的程序。
捕获信号
当一个 Shell 程序正在执行的过程中,你在终端按下了 Ctrl+C 或 Break 键,通常情况下,程序会立即终止,并且你的命令提示返回。但这可能并不总是你所期望的。例如,这可能会留下一堆未清理的临时文件。
捕获这些信号是很容易的,捕获命令(trap)的语法如下:
$ trap commands signals这里的 commands 可以是任何有效的 UNIX 命令,甚至可以是一个用户定义的函数。
signals 可以是一个你想捕获的任何数量信号的列表。
在 Shell 脚本中,trap 有三种常见的用途:
清除临时文件
忽略信号
清除临时文件
作为 trap 命令的一个例子,下面的命令展示了,如果有人试图从终端中止程序时,你如何先删除一些文件,然后退出:
$ trap "rm -f $WORKDIR/work1$$ $WORKDIR/dataout$$; exit" 2如果程序收到了信号值为 2 的信号,trap 命令将会被执行。从 Shell 程序上执行 trap 的这一点开始,work1$$ 和 dataout$$ 这两个文件会自动被删除。
所以如果用户中断程序的运行,这个 trap 将会被执行,你可以确保这两个文件将被清理掉。rm 后面的这个 exit 命令,它的存在是必要的。如果没有它,程序会在它中断点(也就是信号接收的时刻)继续执行。
信号值 1 是由挂断产生的:要么是有人故意挂断终端或者是终端被意外断开。
在这种情况下,把信号值 1 增加到信号列表中,你可以通过这样修改上面的 trap 命令,从而删除那两个指定的文件:
$ trap "rm $WORKDIR/work1$$ $WORKDIR/dataout$$; exit" 1 2现在,如果终端被挂起或者是 Ctrl+C 被按下,这些文件将被删除。
指定的 trap 命令如果包含多个命令,那么它们必须括在引号中。还要注意,当 trap 命令执行时,shell 会扫描一遍命令行,当接收到信号列表的其中一个信号时,也会再执行一次扫描。
所以在上面的例子中,当 trap 命令执行后,WORKDIR 和 $$ 的值将会被替换。如果你想要这种替换仅仅发生在信号值 1 或者 2 接收到的时候,你可以用单引号把多个命令引起来:
$ trap 'rm $WORKDIR/work1$$ $WORKDIR/dataout$$; exit' 1 2忽略信号
如果 trap 命令的 command 字段是空的,那么当接收到指定的信号后,信号将被忽略。例如下面的一个命令:
$ trap '' 2指定的中断信号将被忽略。当执行某些可能不想被打断的操作时,你可能会想忽略掉些特定的信号。按如下所示,你可以指定要忽略的多个信号:
$ trap '' 1 2 3 15注意,如果要一个信号被忽略掉,那么第一个参数必须是指定的空,它不等同于如下的命令,下面的命令有自己单独的意义:
$ trap 2如果你忽略了一个信号,那么你所有的子 Shell 也会忽略此信号。然而,如果你指定了接收一个信号所采取的动作,那么所有的子 shell 接收到此信号后会采取相同动作。
重置 Traps
当你改变了信号接收后的默认动作,你可以通过一个简单的省略第一个参数的 trap 命令将默认动作重置回来。
那么命令
$ trap 1 2将信号 1 和 2 接收后采取的动作重置为其原有的默认动作。
【更多阅读】【编程语言】Scala 函数式编程
【编程实践】SQLite 极简教程
【编程实践】Google Guava 极简教程
【编程语言】AWK 极简教程
Bito AI:免费使用 ChatGPT 编写代码/修复错误/创建测试用例Use ChatGPT to 10x dev work
写代码犹如写文章: “大师级程序员把系统当故事来讲,而不是当做程序来写” | 如何架构设计复杂业务系统? 如何写复杂业务代码?
【工作10年+的大厂资深架构师万字长文总结 精华收藏!】怎样设计高可用、高性能系统?关于高可用高性能系统架构和设计理论和经验总结
【企业架构设计实战】0 企业数字化转型和升级:架构设计方法与实践
【企业架构设计实战】1 企业架构方法论
【企业架构设计实战】2 业务架构设计
【企业架构设计实战】3 怎样进行系统逻辑架构?
【企业架构设计实战】4 应用架构设计
【企业架构设计实战】5 大数据架构设计
【企业架构设计实战】6 数据架构
企业数字化转型和升级:架构设计方法与实践
【成为架构师课程系列】怎样进行系统逻辑架构?
【成为架构师课程系列】怎样进行系统详细架构设计?
【企业架构设计实战】企业架构方法论
【企业架构设计实战】业务架构设计【企业架构设计实战】应用架构设计【企业架构设计实战】大数据架构设计【软件架构思想系列】分层架构【软件架构思想系列】模块化与抽象软件架构设计的核心:抽象与模型、“战略编程”企业级大数据架构设计最佳实践编程语言:类型系统的本质程序员架构修炼之道:软件架构设计的37个一般性原则程序员架构修炼之道:如何设计“易理解”的系统架构?“封号斗罗” 程序员修炼之道:通向务实的最高境界程序员架构修炼之道:架构设计中的人文主义哲学
Gartner 2023 年顶级战略技术趋势【软件架构思想系列】从伟人《矛盾论》中悟到的软件架构思想真谛:“对象”即事物,“函数”即运动变化【模型↔关系思考法】如何在一个全新的、陌生的领域快速成为专家?模仿 + 一万小时定律 + 创新
Redis 作者 Antirez 讲如何实现分布式锁?Redis 实现分布式锁天然的缺陷分析&Redis分布式锁的正确使用姿势!
红黑树、B树、B+树各自适用的场景
你真的懂树吗?二叉树、AVL平衡二叉树、伸展树、B-树和B+树原理和实现代码详解
【动态图文详解-史上最易懂的红黑树讲解】手写红黑树(Red Black Tree)
我的年度用户体验趋势报告——由 ChatGPT AI 撰写
我面试了 ChatGPT 的 PM (产品经理)岗位,它几乎得到了这份工作!!!
大数据存储引擎 NoSQL极简教程 An Introduction to Big Data: NoSQL《人月神话》(The Mythical Man-Month)看清问题的本质:如果我们想解决问题,就必须试图先去理解它【架构师必知必会】常见的NoSQL数据库种类以及使用场景新时期我国信息技术产业的发展【技术论文,纪念长者,2008】B-树(B-Tree)与二叉搜索树(BST):讲讲数据库和文件系统背后的原理(读写比较大块数据的存储系统数据结构与算法原理)HBase 架构详解及数据读写流程【架构师必知必会系列】系统架构设计需要知道的5大精要(5 System Design fundamentals)《人月神话》8 胸有成竹(Chaptor 8.Calling the Shot -The Mythical Man-Month)《人月神话》7(The Mythical Man-Month)为什么巴比伦塔会失败?《人月神话》(The Mythical Man-Month)6贯彻执行(Passing the Word)《人月神话》(The Mythical Man-Month)5画蛇添足(The Second-System Effect)《人月神话》(The Mythical Man-Month)4概念一致性:专制、民主和系统设计(System Design)《人月神话》(The Mythical Man-Month)3 外科手术队伍(The Surgical Team)《人月神话》(The Mythical Man-Month)2人和月可以互换吗?人月神话存在吗?在平时的工作中如何体现你的技术深度?Redis 作者 Antirez 讲如何实现分布式锁?Redis 实现分布式锁天然的缺陷分析&Redis分布式锁的正确使用姿势!程序员职业生涯系列:关于技术能力的思考与总结十年技术进阶路:让我明白了三件要事。关于如何做好技术 Team Leader?如何提升管理业务技术水平?(10000字长文)当你工作几年就会明白,以下几个任何一个都可以超过90%程序员编程语言:类型系统的本质软件架构设计的核心:抽象与模型、“战略编程”【图文详解】深入理解 Hbase 架构 Deep Into HBase ArchitectureHBase 架构详解及读写流程原理剖析HDFS 底层交互原理,看这篇就够了!MySQL 体系架构简介一文看懂MySQL的异步复制、全同步复制与半同步复制【史上最全】MySQL各种锁详解:一文搞懂MySQL的各种锁腾讯/阿里/字节/快手/美团/百度/京东/网易互联网大厂面试题库Redis 面试题 50 问,史上最全。一道有难度的经典大厂面试题:如何快速判断某 URL 是否在 20 亿的网址 URL 集合中?【BAT 面试题宝库附详尽答案解析】图解分布式一致性协议 Paxos 算法Java并发多线程高频面试题编程实践系列: 字节跳动面试题腾讯/阿里/字节/快手/美团/百度/京东/网易互联网大厂面试题库
[精华集锦] 20+ 互联网大厂Java面试题全面整理总结
【BAT 面试题宝库附详尽答案解析】分布式事务实现原理……














 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











