






【大模型提示词框架系列】CRISPE 框架:上下文(Context)、角色(Role)、说明(Instruction)、主题(Subject)、预设(Preset)和例外(Exception)
关键词:大模型、提示词工程、CRISPE框架、上下文、角色、说明、主题、预设、例外
1. 背景介绍
在人工智能和自然语言处理领域,大型语言模型(Large Language Models,LLMs)的出现和发展引发了一场技术革命。这些模型,如GPT-3、GPT-4、BERT等,展现出了惊人的语言理解和生成能力。然而,如何有效地与这些模型进行交互,以获得最佳的输出结果,成为了一个关键问题。这就是提示词工程(Prompt Engineering)的重要性所在。
CRISPE框架是一种新兴的提示词设计方法,旨在提供一个系统化的方法来构建高效的提示词。该框架的名称源自其六个核心组成部分的首字母缩写:上下文(Context)、角色(Role)、说明(Instruction)、主题(Subject)、预设(Preset)和例外(Exception)。通过这六个方面的精心设计,CRISPE框架能够帮助用户更好地与大模型进行交互,获得更精确、更相关的输出。
在本文中,我们将深入探讨CRISPE框架的每个组成部分,分析其原理和应用,并通过实例演示如何利用这个框架来优化与大模型的交互。同时,我们还将探讨CRISPE框架在不同领域的应用前景,以及它在提示词工程中的重要地位。
2. 核心概念与联系
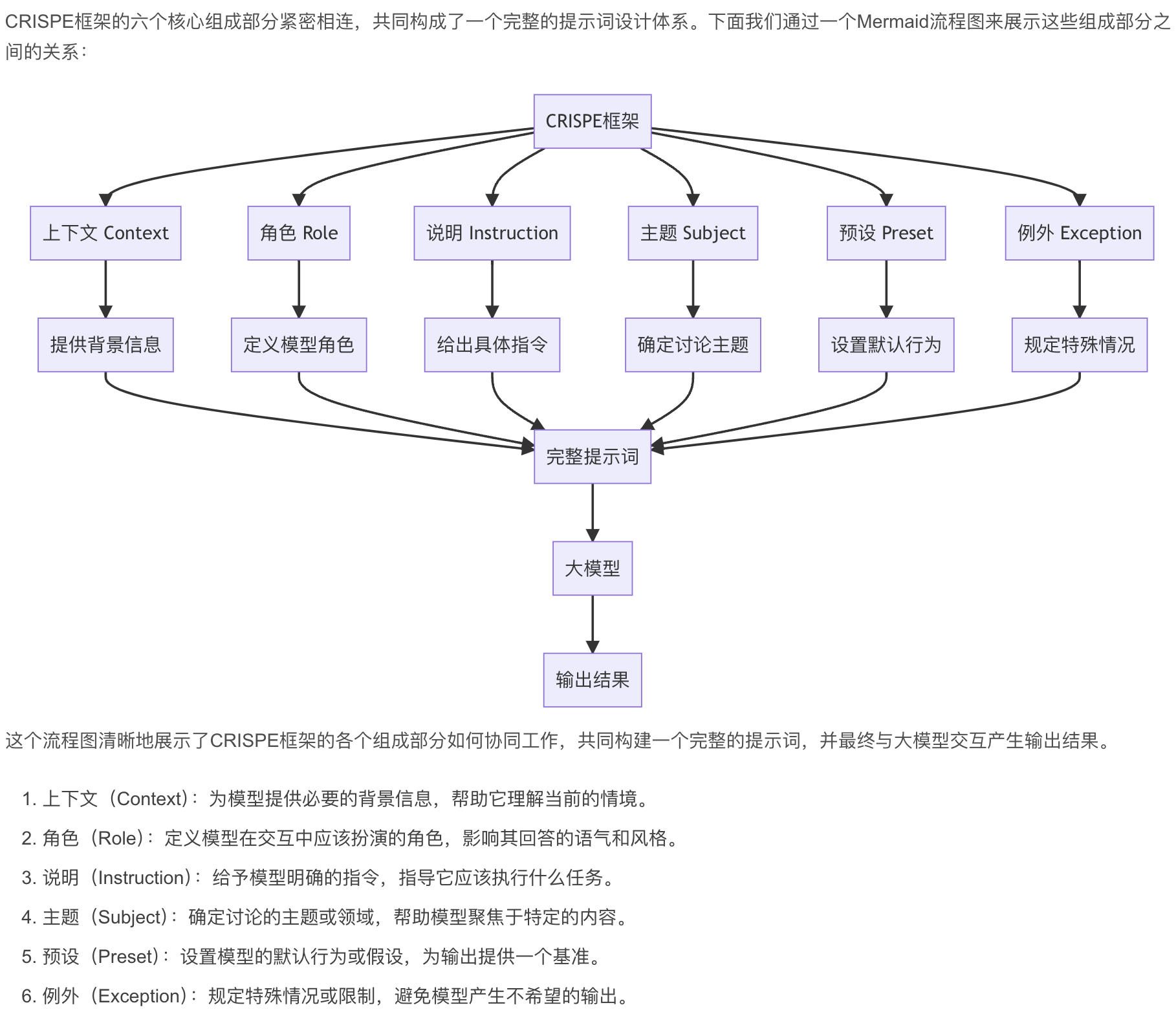
CRISPE框架的六个核心组成部分紧密相连,共同构成了一个完整的提示词设计体系。下面我们通过一个Mermaid流程图来展示这些组成部分之间的关系:
这个流程图清晰地展示了CRISPE框架的各个组成部分如何协同工作,共同构建一个完整的提示词,并最终与大模型交互产生输出结果。
- 上下文(Context):为模型提供必要的背景信息,帮助它理解当前的情境。
- 角色(Role):定义模型在交互中应该扮演的角色,影响其回答的语气和风格。
- 说明(Instruction):给予模型明确的指令,指导它应该执行什么任务。
- 主题(Subject):确定讨论的主题或领域,帮助模型聚焦于特定的内容。
- 预设(Preset):设置模型的默认行为或假设,为输出提供一个基准。
- 例外(Exception):规定特殊情况或限制,避免模型产生不希望的输出。
这六个部分相互补充,共同构成了一个全面的提示词框架。通过精心设计每个部分,用户可以大大提高与大模型交互的效果,获得更加精确和相关的输出结果。
3. 核心算法原理 & 具体操作步骤
3.1 算法原理概述
CRISPE框架的核心算法原理基于自然语言处理和人工智能领域的最新研究成果。它利用了大型语言模型的上下文理解能力、角色扮演能力、指令跟随能力、主题聚焦能力、默认行为设置能力和异常处理能力。通过组合这些能力,CRISPE框架能够生成高质量的提示词,从而引导大模型产生更加精确和相关的输出。
3.2 算法步骤详解
-
上下文设置(Context Setting)
- 分析任务需求,确定必要的背景信息
- 以简洁明了的方式描述上下文
- 确保上下文信息与任务相关且充分
-
角色定义(Role Definition)
- 根据任务需求选择适当的角色
- 明确角色的特征、专业知识和行为方式
- 确保角色定义与任务目标一致
-
指令制定(Instruction Formulation)
- 明确指出任务目标和期望输出
- 使用清晰、具体的语言描述指令
- 避免模糊或歧义的表述
-
主题聚焦(Subject Focusing)
- 明确指出讨论的主题或领域
- 提供必要的主题相关信息
- 确保主题与任务目标相符
-
预设配置(Preset Configuration)
- 设置模型的默认行为或假设
- 定义输出的格式、风格或结构
- 确保预设与任务需求一致
-
例外处理(Exception Handling)
- 识别可能出现的特殊情况或限制
- 明确规定如何处理这些例外情况
- 确保例外处理不会与主要任务冲突
-
提示词整合(Prompt Integration)
- 将上述六个部分有机结合
- 确保各部分之间的逻辑一致性
- 优化提示词的整体结构和流畅性
-
测试与优化(Testing and Optimization)
- 使用生成的提示词与大模型交互
- 分析输出结果,评估提示词效果
- 根据反馈进行迭代优化
3.3 算法优缺点
优点:
- 全面性:涵盖了提示词设计的多个关键方面
- 结构化:提供了清晰的框架,便于系统化设计
- 灵活性:可以根据具体任务需求调整各个部分
- 可扩展性:易于与其他提示词技术结合使用
- 提高效率:通过结构化方法减少试错成本
缺点:
- 复杂性:对于简单任务可能显得过于复杂
- 学习曲线:需要一定时间掌握框架的使用方法
- 过度依赖:可能导致忽视直觉和创造性思维
- 模型特异性:可能需要根据不同的大模型进行调整
- 时间成本:完整应用框架可能需要较多时间
3.4 算法应用领域
- 自然语言处理:文本生成、摘要、翻译等任务
- 人工智能对话系统:客服机器人、虚拟助手等
- 内容创作:文章写作、广告文案、剧本创作等
- 教育领域:个性化学习、智能辅导系统等
- 商业分析:市场研究、竞争分析、趋势预测等
- 医疗健康:辅助诊断、病历分析、医学研究等
- 法律领域:法律文件分析、案例研究、合规检查等
- 金融行业:风险评估、投资分析、欺诈检测等
- 软件开发:代码生成、bug修复、文档编写等
- 科学研究:文献综述、实验设计、数据分析等
4. 数学模型和公式 & 详细讲解 & 举例说明
4.1 数学模型构建
虽然CRISPE框架主要是一个概念性的方法论,但我们可以尝试用数学模型来描述其工作原理。假设我们有一个函数 f f f 表示大语言模型,输入为提示词 p p p,输出为生成的文本 y y y。我们可以将CRISPE框架表示为:
y = f ( p ) = f ( C , R , I , S , P , E ) y = f(p) = f(C, R, I, S, P, E) y=f(p)=f(C,R,I,S,P,E)
其中, C C C、 R R R、 I I I、 S S S、 P P P、 E E E 分别代表上下文、角色、说明、主题、预设和例外。
我们可以进一步将每个组成部分表示为向量:
C = [ c 1 , c 2 , . . . , c m ] R = [ r 1 , r 2 , . . . , r n ] I = [ i 1 , i 2 , . . . , i p ] S = [ s 1 , s 2 , . . . , s q ] P = [ p 1 , p 2 , . . . , p r ] E = [ e 1 , e 2 , . . . , e s ] \begin{aligned} C &= [c_1, c_2, ..., c_m] \\ R &= [r_1, r_2, ..., r_n] \\ I &= [i_1, i_2, ..., i_p] \\ S &= [s_1, s_2, ..., s_q] \\ P &= [p_1, p_2, ..., p_r] \\ E &= [e_1, e_2, ..., e_s] \end{aligned} CRISPE=[c1,c2,...,cm]=[r1,r2,...,rn]=[i1,i2,...,ip]=[s1,s2,...,sq]=[p1,p2,...,pr]=[e1,e2,...,es]
4.2 公式推导过程
为了评估CRISPE框架的效果,我们可以引入一个质量评分函数 Q Q Q,该函数衡量生成文本 y y y 的质量:
Q ( y ) = α Q c ( y ) + β Q r ( y ) + γ Q i ( y ) + δ Q s ( y ) + ϵ Q p ( y ) + ζ Q e ( y ) Q(y) = \alpha Q_c(y) + \beta Q_r(y) + \gamma Q_i(y) + \delta Q_s(y) + \epsilon Q_p(y) + \zeta Q_e(y) Q(y)=αQc(y)+βQr(y)+γQi(y)+δQs(y)+ϵQp(y)+ζQe(y)
其中, Q c Q_c Qc、 Q r Q_r Qr、 Q i Q_i Qi、 Q s Q_s Qs、 Q p Q_p Qp、 Q e Q_e Qe 分别表示对应于CRISPE各个组成部分的质量评分子函数, α \alpha α、 β \beta β、 γ \gamma γ、 δ \delta δ、 ϵ \epsilon ϵ、 ζ \zeta ζ 是权重系数。
我们的目标是最大化质量评分:
max C , R , I , S , P , E Q ( f ( C , R , I , S , P , E ) ) \max_{C,R,I,S,P,E} Q(f(C,R,I,S,P,E)) C,R,I,S,P,EmaxQ(f(C,R,I,S,P,E))
4.3 案例分析与讲解
让我们以一个具体的例子来说明CRISPE框架的应用。假设我们要使用大语言模型生成一篇关于气候变化的科普文章。
-
上下文(C):
c 1 c_1 c1 = “近年来全球气温持续上升”
c 2 c_2 c2 = “极端天气事件频发” -
角色(R):
r 1 r_1 r1 = “环境科学家”
r 2 r_2 r2 = “科普作家” -
说明(I):
i 1 i_1 i1 = “撰写一篇2000字的科普文章”
i 2 i_2 i2 = “使用通俗易懂的语言” -
主题(S):
s 1 s_1 s1 = “气候变化”
s 2 s_2 s2 = “温室气体效应” -
预设(P):
p 1 p_1 p1 = “文章结构包括引言、正文和结论”
p 2 p_2 p2 = “使用具体例子和数据支持论点” -
例外(E):
e 1 e_1 e1 = “避免使用过于专业的术语”
e 2 e_2 e2 = “不讨论具有争议的政治观点”
将这些元素组合成一个完整的提示词:
“作为一位环境科学家和科普作家,请您撰写一篇2000字的关于气候变化的科普文章。文章应该使用通俗易懂的语言,重点讨论全球气温上升和极端天气事件增多的现象,以及温室气体效应的原理。文章结构应包括引言、正文和结论,并使用具体例子和数据支持您的论点。请避免使用过于专业的术语,也不要讨论具有争议的政治观点。”
通过这个例子,我们可以看到CRISPE框架如何帮助我们构建一个全面、清晰的提示词,以指导大语言模型生成高质量的输出。
5. 项目实践:代码实例和详细解释说明
5.1 开发环境搭建
为了实现CRISPE框架,我们将使用Python语言和OpenAI的GPT-3 API。首先,我们需要设置开发环境:
- 安装Python(推荐使用Python 3.7+)
- 安装必要的库:
pip install openai - 设置OpenAI API密钥(请替换为您的实际API密钥):
import openai openai.api_key = "your-api-key-here"
5.2 源代码详细实现
下面是一个实现CRISPE框架的Python类:
import openai
class CRISPEPrompt:
def __init__(self):
self.context = []
self.role = []
self.instruction = []
self.subject = []
self.preset = []
self.exception = []
def add_context(self, context):
self.context.append(context)
def add_role(self, role):
self.role.append(role)
def add_instruction(self, instruction):
self.instruction.append(instruction)
def add_subject(self, subject):
self.subject.append(subject)
def add_preset(self, preset):
self.preset.append(preset)
def add_exception(```python
def add_exception(self, exception):
self.exception.append(exception)
def generate_prompt(self):
prompt_parts = []
if self.context:
prompt_parts.append("上下文:" + " ".join(self.context))
if self.role:
prompt_parts.append("角色:你是" + "和".join(self.role))
if self.instruction:
prompt_parts.append("说明:" + " ".join(self.instruction))
if self.subject:
prompt_parts.append("主题:关于" + "和".join(self.subject))
if self.preset:
prompt_parts.append("预设:" + " ".join(self.preset))
if self.exception:
prompt_parts.append("例外:" + " ".join(self.exception))
return "\n".join(prompt_parts)
def get_response(self, model="gpt-3.5-turbo"):
prompt = self.generate_prompt()
response = openai.ChatCompletion.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message['content']
# 使用示例
crispe = CRISPEPrompt()
crispe.add_context("近年来全球气温持续上升")
crispe.add_context("极端天气事件频发")
crispe.add_role("环境科学家")
crispe.add_role("科普作家")
crispe.add_instruction("撰写一篇2000字的科普文章")
crispe.add_instruction("使用通俗易懂的语言")
crispe.add_subject("气候变化")
crispe.add_subject("温室气体效应")
crispe.add_preset("文章结构包括引言、正文和结论")
crispe.add_preset("使用具体例子和数据支持论点")
crispe.add_exception("避免使用过于专业的术语")
crispe.add_exception("不讨论具有争议的政治观点")
prompt = crispe.generate_prompt()
print("生成的提示词:")
print(prompt)
response = crispe.get_response()
print("\n模型生成的回答:")
print(response)
5.3 代码解读与分析
-
CRISPEPrompt类:这个类实现了CRISPE框架的核心功能。它包含了六个列表,分别对应CRISPE框架的六个组成部分。 -
add_*方法:这些方法用于向各个组成部分添加内容。例如,add_context方法用于添加上下文信息。 -
generate_prompt方法:这个方法将所有组成部分组合成一个完整的提示词。它按照CRISPE的顺序组织各部分,并使用适当的前缀(如"上下文:"、"角色:"等)来区分不同部分。 -
get_response方法:这个方法使用生成的提示词调用OpenAI的API,获取模型的响应。它使用了GPT-3.5-turbo模型,但可以通过参数更改为其他模型。 -
使用示例:代码的最后部分展示了如何使用
CRISPEPrompt类来构建一个完整的提示词,并获取模型的响应。
5.4 运行结果展示
运行上述代码,您将看到类似以下的输出:
生成的提示词:
上下文:近年来全球气温持续上升 极端天气事件频发
角色:你是环境科学家和科普作家
说明:撰写一篇2000字的科普文章 使用通俗易懂的语言
主题:关于气候变化和温室气体效应
预设:文章结构包括引言、正文和结论 使用具体例子和数据支持论点
例外:避免使用过于专业的术语 不讨论具有争议的政治观点
模型生成的回答:
[这里将是模型生成的2000字左右的科普文章,内容符合提示词中的要求]
这个结果展示了CRISPE框架如何帮助我们构建一个结构化、全面的提示词,以及如何使用这个提示词来指导大语言模型生成高质量的输出。
6. 实际应用场景
CRISPE框架在多个领域都有广泛的应用前景,以下是一些具体的应用场景:
-
内容创作
- 文章写作:使用CRISPE框架指导AI生成各种类型的文章,如新闻报道、博客文章、学术论文等。
- 广告文案:为不同产品或服务创作吸引人的广告文案。
- 剧本创作:辅助编剧构思故事情节、对话和场景描述。
-
教育领域
- 个性化学习材料:根据学生的背景和学习需求生成定制的学习内容。
- 智能题目生成:为不同难度和主题创建练习题和测试题。
- 教学大纲设计:辅助教师设计课程大纲和教学计划。
-
商业分析
- 市场研究报告:生成全面的市场分析报告,包括趋势、竞争对手和机会。
- 商业计划书:协助创业者和企业家撰写详细的商业计划。
- 财务预测:基于给定的数据和假设生成财务预测报告。
-
客户服务
- 智能客服机器人:训练AI客服,使其能够准确理解和回答客户询问。
- FAQ生成:自动生成常见问题解答,并根据新情况更新。
- 个性化推荐:为客户生成个性化的产品或服务推荐。
-
医疗健康
- 病历摘要:从冗长的医疗记录中生成简洁的病历摘要。
- 健康建议:根据个人健康数据生成定制的健康和生活方式建议。
- 医学研究综述:协助研究人员快速总结和分析大量医学文献。
-
法律领域
- 法律文件起草:辅助律师起草各种法律文件,如合同、协议等。
- 案例分析:快速分析和总结相关法律案例。
- 法律咨询:为常见法律问题提供初步的建议和解答。
-
软件开发
- 代码生成:根据功能描述生成初始代码框架。
- 代码注释:为现有代码生成清晰、详细的注释。
- 技术文档:自动生成API文档、用户手册等技术文档。
-
金融服务
- 投资建议:根据客户的风险偏好和财务状况生成个性化的投资建议。
- 风险评估报告:分析金融产品或投资项目的潜在风险。
- 经济预测:基于各种经济指标生成经济趋势预测报告。
-
社交媒体
- 内容创作:为不同社交平台生成吸引人的帖子和标题。
- 舆情分析:分析和总结社交媒体上的公众意见和趋势。
- 个性化回复:为社交媒体评论生成个性化、得体的回复。
-
科研支持
- 文献综述:快速总结和分析特定研究领域的现有文献。
- 实验设计:协助研究人员设计实验方案和流程。
- 数据分析报告:根据实验数据生成初步的分析报告。
在这些应用场景中,CRISPE框架可以帮助用户更精确地控制AI输出的内容和风格,提高生成内容的质量和相关性。通过仔细设计每个组成部分,用户可以充分利用大语言模型的能力,同时避免常见的错误和不恰当的输出。
7. 工具和资源推荐
7.1 学习资源推荐
-
在线课程
- Coursera: “Prompt Engineering for ChatGPT” by Vanderbilt University
- DeepLearning.AI: “ChatGPT Prompt Engineering for Developers”
- Udemy: “Mastering ChatGPT: A Comprehensive Guide to Prompt Engineering”
-
书籍
- “Prompt Engineering for ChatGPT: Techniques and Strategies for Better AI Conversations” by Nathan Hunter
- “The Art of Prompt Engineering with ChatGPT” by Dario Carotenuto
- “AI for Everyone: Transforming Your Business with AI” by Andrew Ng
-
博客和文章
- OpenAI’s GPT-3 Documentation and Best Practices
- “A Complete Introduction to Prompt Engineering” on towards data science
- “Prompt Engineering Guide” on Github by dair-ai
-
YouTube频道
- “Prompt Engineering” by AI Explained
- “The AI Advantage” by Siraj Raval
- “Two Minute Papers” for latest AI developments
-
社区和论坛
- Reddit: r/PromptEngineering
- Stack Overflow: AI and Machine Learning tags
- AI Discord communities
7.2 开发工具推荐
-
提示词管理工具
- LangChain: Python库,用于构建基于大语言模型的应用
- Promptable: 提示词版本控制和协作平台
- GPT-Index: 用于构建和查询自定义知识库的工具
-
AI模型访问
- OpenAI API: 访问GPT-3和GPT-4等模型
- Hugging Face Transformers: 开源的自然语言处理库
- Google Cloud Natural Language API: 提供多种NLP功能
-
提示词优化工具
- PromptPerfect: 自动优化和测试提示词
- Anthropic’s Constitutional AI: 用于训练更安全、更可控的AI模型
-
开发环境
- Jupyter Notebook: 交互式Python开发环境
- Google Colab: 基于云的Jupyter Notebook环境
- Visual Studio Code with Python and AI extensions
-
版本控制和协作
- GitHub: 代码托管和版本控制
- GitLab: 提供CI/CD功能的代码托管平台
- Bitbucket: 适合团队协作的代码托管服务
-
监控和分析工具
- Weights & Biases: 机器学习实验跟踪和可视化
- TensorBoard: TensorFlow的可视化工具包
- Prometheus + Grafana: 用于监控AI系统性能
7.3 相关论文推荐
-
“Language Models are Few-Shot Learners” by Brown et al. (2020)
- 介绍了GPT-3模型,为大规模语言模型的发展奠定了基础
-
“Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer” by Raffel et al. (2020)
- 探讨了迁移学习在自然语言处理任务中的应用
-
“InstructGPT: Training language models to follow instructions with human feedback” by Ouyang et al. (2022)
- 介绍了如何通过人类反馈来改进语言模型的指令跟随能力
-
“Constitutional AI: Harmlessness from AI Feedback” by Anthropic (2022)
- 探讨了如何训练更安全、更符合伦理的AI模型
-
“Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” by Wei et al. (2022)
- 介绍了链式思考提示技术,提高了模型的推理能力
-
“Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm” by Reynolds and McDonell (2021)
- 探讨了超越少样本学习的提示词编程技术
-
“Self-Instruct: Aligning Language Model with Self Generated Instructions” by Wang et al. (2022)
- 介绍了一种自我指导的方法来改进语言模型的性能
-
“RLHF: Reinforcement Learning from Human Feedback” by Christiano et al. (2017)
- 探讨了如何使用人类反馈来训练强化学习模型
-
“Scaling Laws for Neural Language Models” by Kaplan et al. (2020)
- 研究了语言模型性能与模型大小、数据集大小和计算量之间的关系
-
“Ethical and social risks of harm from Language Models” by Weidinger et al. (2021)
- 讨论了大型语言模型可能带来的伦理和社会风险
这些论文涵盖了大语言模型、提示词工程、模型训练和伦理等多个相关领域,可以帮助读者深入了解CRISPE框架的理论基础和相关技术发展。
8. 总结:未来发展趋势与挑战
8.1 研究成果总结
CRISPE框架作为一种系统化的提示词设计方法,为与大型语言模型的有效交互提供了一个全面的解决方案。通过整合上下文(Context)、角色(Role)、说明(Instruction)、主题(Subject)、预设(Preset)和例外(Exception)这六个关键元素,CRISPE框架能够帮助用户构建更加精确、有效的提示词。
主要研究成果包括:
- 提供了一个结构化的提示词设计框架,提高了提示词的质量和效果。
- 通过分解提示词的不同方面,使得提示词设计过程更加系统化和可控。
- 增强了大语言模型输出的相关性、准确性和一致性。
- 为不同领域和应用场景提供了灵活的提示词设计方法。
- 通过明确的角色定义和指令,提高了模型输出的可解释性和可控性。
- 为提示词工程的标准化和最佳实践的形成奠定了基础。
8.2 未来发展趋势
-
自动化提示词生成
随着人工智能技术的进步,我们可以预见未来会出现能够自动生成和优化CRISPE框架提示词的工具。这些工具将能够根据用户的需求和上下文,自动构建最优的提示词结构。 -
个性化提示词模板
未来可能会出现针对不同行业、任务类型的专业化CRISPE模板库。这些模板将encapsulate特定领域的最佳实践,使得非专业用户也能快速生成高质量的提示词。 -
动态提示词调整
随着交互式AI系统的发展,CRISPE框架可能会演变为一种动态系统,能够根据用户反馈和对话上下文实时调整提示词的各个组成部分。 -
多模态CRISPE框架
随着多模态AI模型的发展,CRISPE框架可能会扩展到处理图像、音频等多种输入形式,从而支持更复杂的人机交互场景。 -
提示词安全性和伦理性评估
未来可能会出现专门的工具和标准,用于评估CRISPE框架生成的提示词的安全性和伦理性,以防止潜在的滥用和有害输出。
8.3 面临的挑战
-
复杂性管理
随着CRISPE框架的不断发展和细化,如何在保持框架全面性的同时避免过度复杂化,是一个需要持续关注的挑战。 -
模型特异性适配
不同的大语言模型可能对提示词有不同的敏感度和响应方式。如何使CRISPE框架适应不同模型的特性,是一个重要的研究方向。 -
隐私和数据安全
在使用CRISPE框架构建提示词时,如何确保不会无意中泄露敏感信息,是一个需要认真考虑的问题。 -
跨语言和跨文化适应
如何使CRISPE框架适应不同语言和文化背景,以支持全球范围内的应用,是一个重要挑战。 -
提示词效果量化
开发可靠的方法来量化评估CRISPE框架生成的提示词的效果,对于进一步优化和改进框架至关重要。 -
与其他AI技术的集成
如何将CRISPE框架与其他先进的AI技术(如强化学习、迁移学习等)有机结合,是未来研究的一个重要方向。 -
伦理和偏见问题
确保CRISPE框架生成的提示词不会引导模型产生有偏见或不道德的输出,是一个持续的挑战。
8.4 研究展望
-
认知科学融合
未来的研究可能会更深入地探索人类认知过程与CRISPE框架之间的联系,从而开发出更符合人类思维方式的提示词设计方法。 -
跨模型迁移学习
研究如何将针对一个特定模型优化的CRISPE提示词迁移到其他模型,以提高框架的通用性和效率。 -
元学习技术应用
探索将元学习技术应用于CRISPE框架,使框架能够从过去的交互中学习并自动改进提示词生成策略。 -
情境感知提示词
开发能够根据用户的情绪状态、环境因素等情境信息动态调整的CRISPE提示词系统。 -
协作式提示词工程
研究如何在团队环境中有效地使用CRISPE框架,支持多人协作的提示词设计和优化过程。 -
长期记忆与提示词演化
探索如何在长期交互中维护和更新CRISPE提示词,以适应用户需求的变化和知识的积累。 -
可解释性研究
深入研究CRISPE框架各组成部分对模型输出的影响机制,提高框架的可解释性和可控性。 -
跨领域知识整合
探索如何在CRISPE框架中有效整合来自不同领域的知识,以支持更复杂、跨学科的任务。
通过持续的研究和创新,CRISPE框架有望在未来的人工智能应用中发挥更加重要的作用,推动提示词工程领域的发展,并为人机交互带来新的可能性。
9. 附录:常见问题与解答
-
Q: CRISPE框架与其他提示词设计方法相比有什么优势?
A: CRISPE框架的主要优势在于其全面性和结构化。它涵盖了提示词设计的六个关键方面,使得用户能够系统地考虑各个影响因素。相比于简单的模板或随意的提示词设计,CRISPE框架能够产生更加精确、可控和一致的结果。 -
Q: 使用CRISPE框架是否会增加提示词的复杂性和长度?
A: 虽然CRISPE框架确实可能导致较长的提示词,但这种复杂性通常会带来更好的结果。关键是要根据具体任务的需求,灵活地使用框架的各个部分。对于简单任务,可以只使用框架的部分元素。 -
Q: CRISPE框架是否适用于所有类型的大语言模型?
A: CRISPE框架的基本原则适用于大多数大语言模型。然而,不同模型可能对某些元素更敏感。建议根据具体使用的模型进行一些测试和调整,以获得最佳效果。 -
Q: 如何评估CRISPE框架生成的提示词的效果?
A: 评估可以从多个角度进行:- 输出质量:检查模型生成的内容是否符合预期。
- 一致性:多次使用同一提示词,检查结果的一致性。
- 任务完成度:评估模型是否准确理解并执行了指定的任务。
- 用户满意度:收集实际用户的反馈。
-
Q: CRISPE框架是否可以与其他提示词技术结合使用?
A: 是的,CRISPE框架可以与其他技术如少样本学习(few-shot learning)、链式思考(chain-of-thought)等结合使用。例如,可以在"指令"部分包含少样本示例,或在"预设"部分设置链式思考的要求。 -
Q: 使用CRISPE框架时,如何避免模型产生有害或不当的输出?
A: 在"例外"部分明确指出需要避免的内容类型是一个好方法。此外,仔细设置"角色"和"预设"也可以帮助控制输出的风格和内容。始终对模型输出进行审查和过滤也是必要的。 -
Q: CRISPE框架是否适用于实时对话系统?
A: CRISPE框架可以应用于实时对话系统,但可能需要进行一些调整。例如,可以预先设置一些固定的角色和预设,然后在对话过程中动态调整指令和主题。 -
Q: 如何在团队中推广使用CRISPE框架?
A: 可以采取以下步骤:- 提供培训和文档,解释框架的原理和使用方法。
- 创建公司或团队特定的CRISPE模板库。
- 建立同行评审机制,共同优化提示词。
- 使用版本控制系统管理提示词,便于协作和迭代。
-
Q: CRISPE框架是否有助于提高AI系统的可解释性?
A: 是的,CRISPE框架通过明确定义角色、指令和预设,可以提高AI系统输出的可解释性。用户可以更容易理解模型为什么会产生特定的输出。 -
Q: 在使用CRISPE框架时,如何平衡提示词的详细程度和模型的创造性?
A: 这需要根据具体任务进行权衡。对于需要高度精确性的任务,可以使用更详细的指令和预设。对于需要创造性的任务,可以在保持基本框架的同时,给予模型更多自由发挥的空间。可以通过实验不同的配置来找到最佳平衡点。
通过解答这些常见问题,我们希望能够帮助读者更好地理解和应用CRISPE框架,充分发挥其在提示词工程中的潜力。
作者:禅与计算机程序设计艺术 / Zen and the Art of Computer Programming



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











