








 该专栏为热销专栏榜 第37名
该专栏为热销专栏榜 第37名 超级会员免费看
超级会员免费看

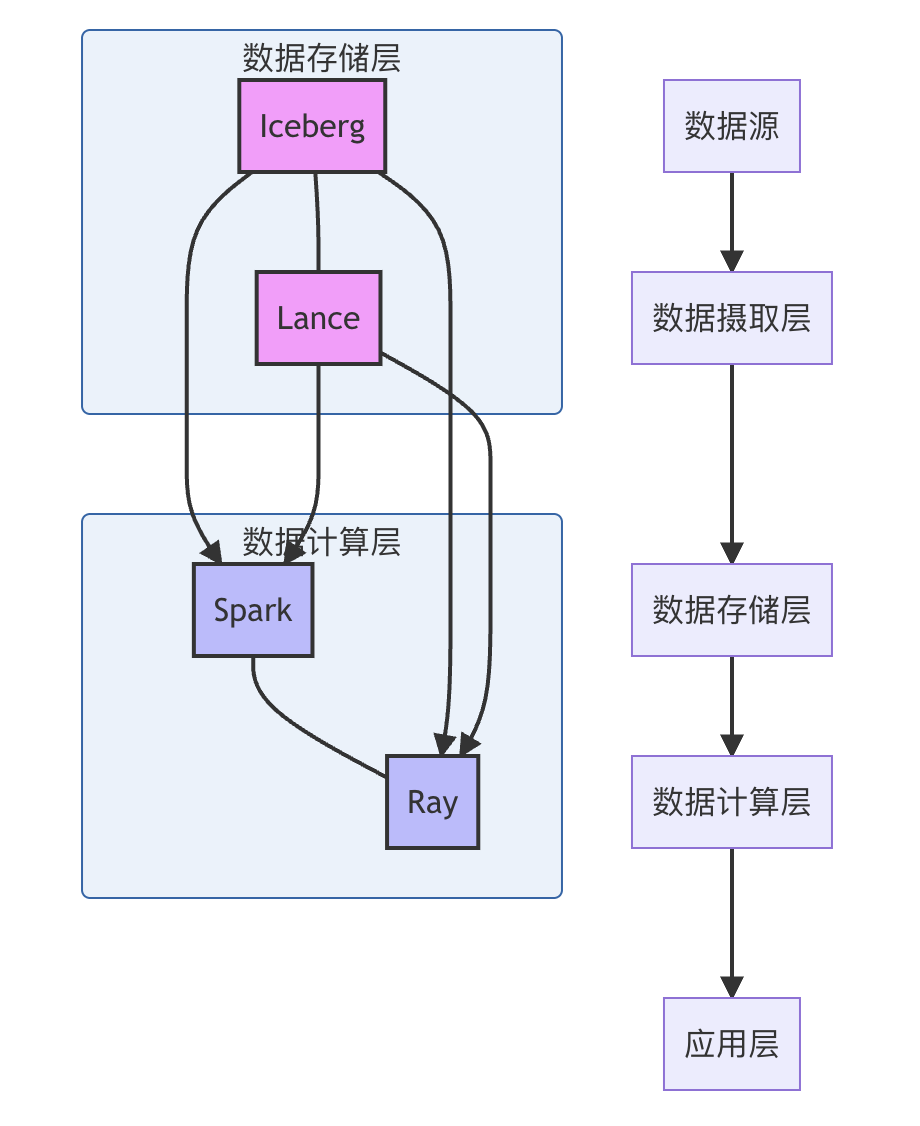
万字详解:Spark、Ray、Iceberg、Lance 计算引擎实现原理剖析、对比与应用
关键词:分布式计算、数据湖、数据处理引擎、大数据架构、计算优化
摘要:本文深入剖析了四种现代数据处理技术:Spark、Ray、Iceberg和Lance的核心原理与实现机制。通过生动易懂的类比和实例,从数据处理的历史演变出发,详细解析了这些技术如何解决大规模数据处理的挑战。文章对比了四种技术的架构设计、性能特点和适用场景,并通过实际项目案例展示了它们在企业中的应用价值。同时,提供了完整的环境搭建、系统设计和核心代码实现,帮助读者快速掌握这些技术。最后,探讨了大数据处理技术的未来发展趋势,为数据工程师和架构师提供了全面的技术参考。
文章目录
- 万字详解:Spark、Ray、Iceberg、Lance 计算引擎实现原理剖析、对比与应用
1. 问题背景:数据洪流中的"交通管理"挑战
想象一下,小明家附近有一条小溪。小时候,他可以轻松用小桶从溪流中取水。随着时间推移,这条小溪变成了湍急的大河,水量激增到小明无法用原来的方式取水了。
在数据世界

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











