






文章目录
摘要
本周通过神奇宝贝识别的例子进一步学习了什么是generative model,然后又通过对该模型进行改进,从而了解了Logistic Regression(逻辑回归)的概念以及所使用的Discriminative方法。
Pokemon Classification - Generative Model
Prior 只考虑水系和自然系两种
用小于400的ID标识training,大于400的ID标识testing。
Training = 79 water(水系),61 Normal(自然系)
水系概率P(C1)=79/(79+61)=0.56
自然系概率P(C2)=61/(79+61)=0.44
Probability from class - feature
使用vector(向量)来描述一只宝可梦,该vector也是一种feature。
首先考虑Defense和 SP Defense两种属性。
假设这些点服从高斯分布(正态分布)。

注:高斯分布
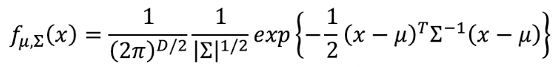
输入:向量x 输出:选中x的可能性
函数的形状由期望μ和矩阵∑决定。
其中期望μ为均值向量,协方差矩阵∑是对称正定矩阵。
Maximum Likelihood(最大化可能性)

以水系为例:
对水系的79个样品进行编号x1-x79,求出使得这个79个点可能性最高的高斯分布模型,求出此时的μ和∑,最大的μ是对x1-x79求平均值,最大的Σ如下图所示。

继续求出自然系的情况,得到下图所示的∑1,∑2,μ1,μ2
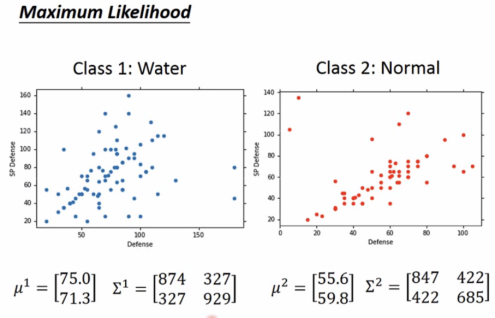
此时所有的未知数都已解出,可以对水系和自然系进行分类,如果P(C1|x)>0.5,则为水系,否则为自然系。

分类准确率并不能令人满意,即使考虑扩展防御和特防到七维属性,正确率依旧不高。

Modifying Model
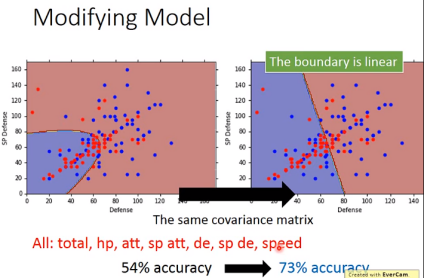
对water和normal使用相同的∑,可以减少parameters的数量。此时求解μ1和
μ2的过程不变,但∑有所改变。

Three Steps
Function set(Model):

Goodness of a function:
if P(C1|x)> 0.5,输出class 1水系,否则输出class 2 自然系。
Fine the best function:easy
修改后的模型使用七维的识别正确率提高了很多,由54%提高到73%。
Probability Distribution
事实上,使用哪种分布模型是根据具体问题来的。
例如,遇到binary features(0-1二元选择)应该使用伯努利分布,
如果假设所有的未知数x都是独立的,则应该使用朴素贝叶斯法。

Posterior Probability

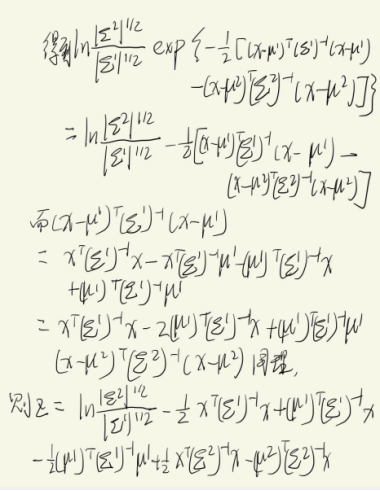

在generative model中,预估∑1、∑2、μ1、μ2,然后得到w和b。

Logistic Regression(逻辑回归)
step 1:Funcion set

step 2:Goodness of a Function
假设生成数据基于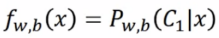
当给定一组w,b的集合时,求出生成数据的可能性,找出最大的L(w,b)
和此时的w*,b*的值。



接下来计算cross entropy(交叉熵),

step 3:Find the best Function
仍然使用gradient descent找最优解:

logistic regression与linear regression进行对比

Discriminative和Generative进行对比
Discriminative:直接找w,b,挖掘数据关系,样本量越大越准确。
Generative:先找∑1、μ1、μ2,再求w,b(做了假设,例如符合高斯分布等等)

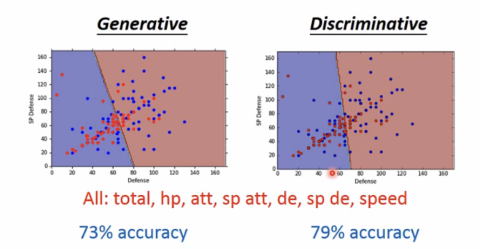
从结果来看,Discriminative(判别)比Generative(生成)更加准确。但Generative也有
以下优势:
当训练数据较少时表现更好,面对训练集中的错误更加健壮,prior和class-independent 可以来自不同的resources。
总结
本周所学的各种模型用到了概率论,线性代数以及微分等数学知识,还需要好好消化吸收。














 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









