






文章目录
摘要
本周阅读了一篇基于LSTM-CTC的语音识别模型的文章,文章中将LSTM和CTC相结合,提高了训练的准确率、节省了训练时长。同时,我对LSTM相关内容进行补充学习,进一步了解了LSTM的本质。
Abstract
This week reading an article on a speech recognition model based on LSTM-CTC, which combines LSTM and CTC to improve training accuracy and save training time. At the same time, conducting supplementary learning on LSTM related content to further understand the essence of LSTM.
文献阅读
题目
A Speech Recognition Acoustic Model Based on LSTM-CTC
创新点
摘要声学模型在语音识别系统中起着非常重要的作用。与以往大多采用判别模型结合HMM混合模型进行声学模型训练的系统相比,本文基于联结主义时态分类(CTC)原理,将CTC训练与LSTM模型相结合,提出了一种LSTM-CTC模型。通过将LSTM顶部输出的Softmax向量插入到CTC模型中,并使用CTC解码方法,该模型减少了整个序列的损失,并在LSTM输出的预测概率中正确预测序列标签。
DNN-HMM MODEL
声学模型必须考虑每个特征帧的长时间相关性,因为句子中相邻音素的语音会相互影响。DNN-HMM采用左右相邻特征拼接的方法建立上下文信息模型,体现了相邻帧之间的相关性。但相邻特征拼接不反映长时间依赖性,对时间建模的贡献有限。
Time Classifier CTC
CTC是RNN为解决语音识别中时间序列的输入特征和输出标签长度不一定相等的问题而进行的顶层设计。CTC可以优化全局模型参数,并使使用RNN构建语音识别系统成为可能,而无需标签随时间逐个对齐。将CTC训练与LSTM模型相结合,提出了一种LSTM-CTC语音识别的声学模型。在该模型中,LSTM顶层输出的Softmax向量连接到CTC模型,并通过使用CTC解码方法减少整个序列的损失。
CTC TRAINING
引入CTC之后,仅使用单个网络模型来对语音从特征输入到文本输出的所有方面进行建模,或者可以直接使用WER的某个代理作为目标函数来训练神经网络。CTC的训练过程类似于传统的神经网络。它们都是先构造损失函数,然后根据BP算法进行训练。由声学模型训练的CTC损失函数定义如下,其中p(z| x)是条件概率:
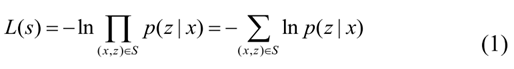
根据CTC损失函数的表达式,给定的 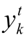 表示t次输出到K的概率:
表示t次输出到K的概率: 表示对应于softmax归一化之前的K值的t时间:
表示对应于softmax归一化之前的K值的t时间:
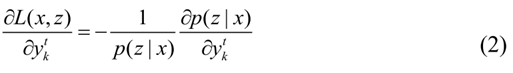
只需要考虑t在任意时刻通过K节点的路径:
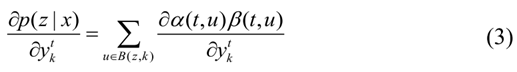
B(z,k)它将节点表示为K的集合,考虑到:
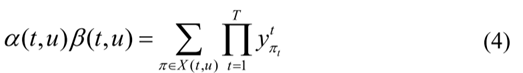
其中X(t,u)表示在t时刻通过节点u的所有路径。因此:
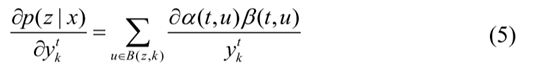
损失函数对 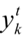 的偏导数可以得到:
的偏导数可以得到:

同时,我们可以得到 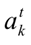
的损失函数的偏导数:
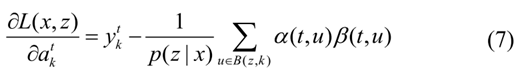
基于CTC的LSTM语音识别模型
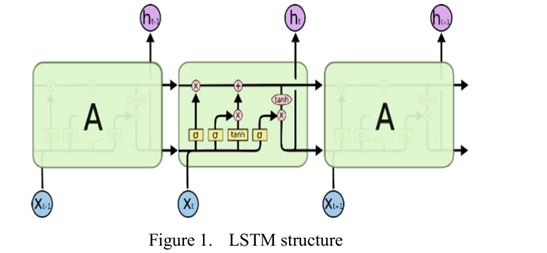
LSTM是一种改进的时间递归神经网络,可以有效地处理时间序列中的长期依赖问题。图一中重复的模块表示每次迭代中的隐藏层。每个隐藏层包含许多神经元。每个神经元对输入向量进行线性矩阵计算,然后在激活函数的非线性作用后输出相应的结果。在每次迭代中,前一次迭代的输出与文本的下一个词向量相互作用,确定信息的保留或放弃,以及当前状态的更新。
实验过程
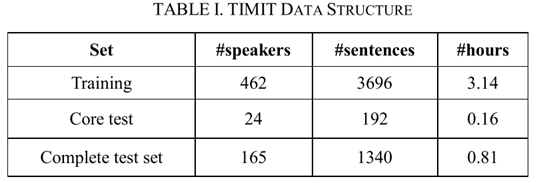
本文中的语音库是TIMIT语音库。TIMIT官方文件建议将语音库分为训练集(70)和测试集(30)。通常只有语音紧凑的句子和语音多样的句子。训练集和测试集的数据结构不一致。TIMIT如表I所示:
在训练DNN时,将输入层节点数设置为462,隐藏层设置为4层,每层包含1024个隐藏层单元,学习率为0.008,迭代次数设置为40。采用sigmoid函数作为网络的激励函数,在网络输出时用softmax对结果进行归一化。
在LSTM模型的训练过程中,使用梯度下降法训练和minibatch策略。批量大小设置为20,学习率设置为0.003。Softmax输出层设置为62,因为数据集包含61个因子类别,加上CTC空白标签。最后采用最佳路径译码。
实验结果
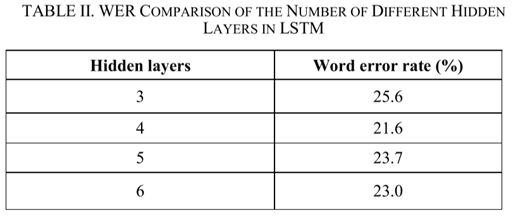
LSTM中不同隐藏层数量的比较:
LSTM中不同隐层单元的WER比较:

DNN-HMM与LSTM-CTC WER的比较:

本文的新模型不仅比DNN-HMM模型降低了1.4个百分点的单词错误率,而且将模型的训练时间缩短了近3/4。
深度学习LSTM
LSTM:LSTM(Long Short-Term Memory)是一种长短期记忆网络,是一种特殊的RNN(循环神经网络)。与传统的RNN相比,LSTM更加适用于处理和预测时间序列中间隔较长的重要事件。
传统的RNN结构可以看做是多个重复的神经元构成的“回路”,每个神经元都接受输入信息并产生输出,然后将输出再次作为下一个神经元的输入,依次传递下去。这种结构能够在序列数据上学习短时依赖关系,但是由于梯度消失和梯度爆炸问题,RNN在处理长序列时难以达到很好的性能。
而LSTM通过引入记忆细胞、输入门、输出门和遗忘门的概念,能够有效地解决长序列问题。记忆细胞负责保存重要信息,输入门决定要不要将当前输入信息写入记忆细胞,遗忘门决定要不要遗忘记忆细胞中的信息,输出门决定要不要将记忆细胞的信息作为当前的输出。这些门的控制能够有效地捕捉序列中重要的长时间依赖性,并且能够解决梯度问题。
LSTM长短期神经网络的主要用途包括:
• 文本生成:LSTM可以学习语言模型,在给定一些前缀的情况下生成合理的文本。
• 语音识别:LSTM可以用来识别语音,可以识别说话人的声音,也可以用来识别说话的语音。
• 机器翻译: LSTM可以用来翻译文本,可以把一种语言翻译成另一种语言。
• 时间序列预测: LSTM可以用来预测时间序列数据,比如股票价格,天气预报等。
除了文本生成,语音识别和机器翻译这些领域之外,LSTM也在其他领域有所应用。比如说在生物信息学领域,LSTM可以用来预测RNA结构,在金融领域,LSTM可以用来分析股票价格和货币汇率。
LSTM与传统RNN的区别:
- RNN在处理长时间依赖性问题时会出现梯度消失/爆炸问题,这是因为它在每一层之间都有相同的权重矩阵,而随着时间序列长度增加,这些权重矩阵的乘积会不断地增大或缩小。而 LSTM 的记忆细胞和门控机制就是为了解决这个问题而设计的。
- LSTM 结构中的门控机制,可以更好地控制信息的流动,有效地避免了无关信息的干扰和梯度消失问题。而 RNN 则缺乏这样的机制,信息的流动不够灵活。
- LSTM 更适用于处理长时间依赖性问题,因为其能够有效地保存和更新历史信息。而 RNN 更适用于处理短时间依赖性问题。
简单的LSTM文本生成示例,使用 Python 和 Keras 库实现 LSTM 文本生成:
- 首先将文本数据预处理,生成字典、输入序列和标签
- 使用 Keras 库构建 LSTM 模型,包括嵌入层、LSTM层、Dropout层、Dense层等
- 用处理好的数据训练模型
- 使用训练好的模型生成文本
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Embedding, LSTM, Dense, Dropout
from keras.preprocessing.text import Tokenizer
from keras.callbacks import EarlyStopping
from keras.models import Sequential
import keras.utils as ku
设置训练参数
tokenizer = Tokenizer()
数据集
data = "我喜欢学习神经网络和机器学习"
生成字典
def dataset_preparation(data):
# 对输入数据进行处理
corpus = data.lower().split("\n")
# 创建字典
tokenizer.fit_on_texts(corpus)
total_words = len(token)
把每句话转换为数字序列
input_sequences = []
for line in corpus:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
return input_sequences, total_words
inp_sequences, total_words = dataset_preparation(data)
用于 pad sequences
max_sequence_len = max([len(x) for x in inp_sequences])
inp_sequences = np.array(pad_sequences(inp_sequences, maxlen=max_sequence_len, padding='pre'))
创建predictors和label
predictors, label = inp_sequences[:,:-1],inp_sequences[:,-1]
label = ku.to_categorical(label, num_classes=total_words)
构建模型
model = Sequential()
model.add(Embedding(total_words, 10, input_length=max_sequence_len-1))
model.add(LSTM(150, return_sequences = True))
model.add(Dropout(0.2))
model.add(LSTM(100))
model.add(Dropout(0.2))
model.add(Dense(total_words, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
model.fit(predictors, label, epochs=100, verbose=2)
生成文本
model.fit(predictors, label, epochs=100, verbose=2)
生成文本
def generate_text(seed_text, next_words, model, max_sequence_len):
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predict_word = model.predict(token_list, verbose=0)
predict_word = predict_word.argmax()
word = tokenizer.index_word[predict_word]
seed_text += " " + word
return seed_text
print(generate_text("我是一个", 3, model, max_sequence_len))




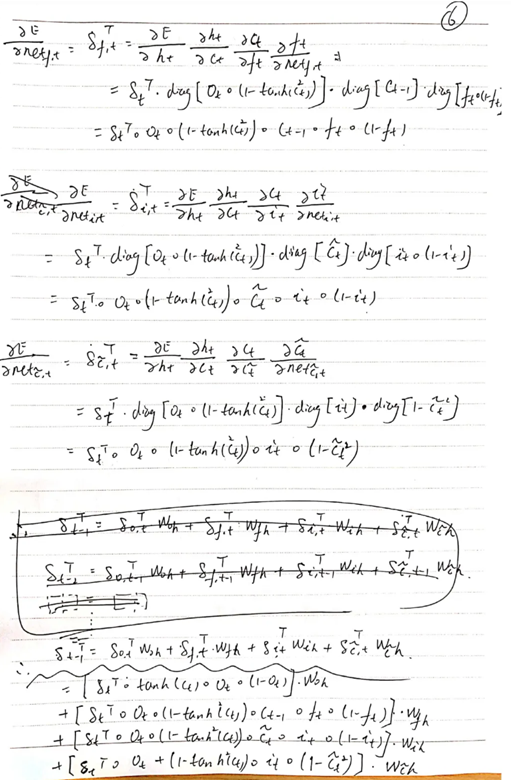




总结
本周学习了LSTM的一篇论文和相关理论知识,以及简单的代码实例,下周将进一步学习。















 3581
3581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









