






小组学习——Day5-数据结构
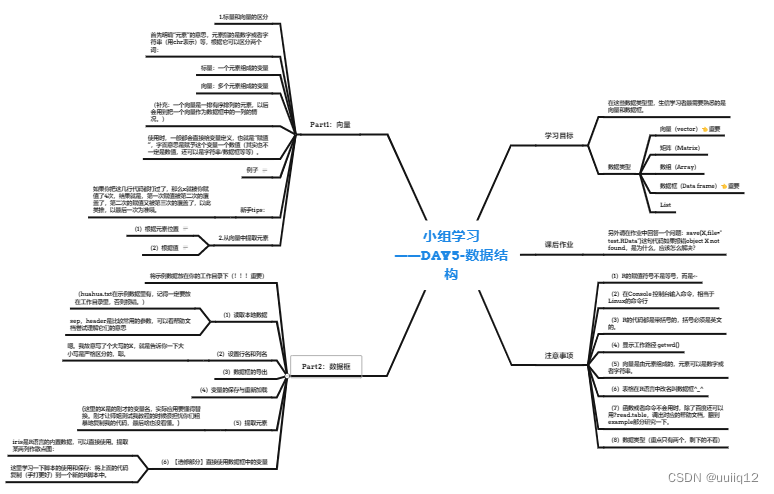
Part1:标量与向量
1. 标量和向量的区分
首先明确“元素”的意思,元素指的是数字或者字符串(用chr表示)等,根据它可以区分两个词:
标量:一个元素组成的变量
向量:多个元素组成的变量
赋值
x<- c(1,2,3) #常用的向量写法,意为将x定义为由元素1,2,3组成的向量。
x
x<- 1:10 #从1-10之间所有的整数
x
x<- seq(1,10,by = 0.5) #1-10之间每隔0.5取一个数(注意是逗号不是分号)
x
x<- rep(1:3,times=2) #1-3 重复2次
x
2. 从向量中提取元素
1)根据元素位置
#这里的x是你刚才赋值的变量名,根据自己的情况来修改
x[4] #x第4个元素
x[-4]#排除法,除了第4个元素之外剩余的元素
x[2:4]#第2到4个元素
x[-(2:4)]#除了第2-4个元素
x[c(1,5)] #第1个和第5个元素
(2)根据值
x[x==10]#等于10的元素
x[x<0]
x[x %in% c(1,2,5)]#存在于向量c(1,2,5)中的元素
tips:%in%函数的用法就是判断函数左边的向量是否在函数右边中,然后返回一个布尔值
2)根据值
x[x==10]#等于10的元素
x[x<0]
x[x %in% c(1,2,5)]#存在于向量c(1,2,5)中的元素
Part2:
(1)读取本地数据
read.table(file = "huahua.txt",sep = "\t".header =t)
a<-read.table(file = "huahua.txt",sep = "\t".header =t)
(2)设置行名和列名
X<-read.csv('doudou.txt') #在示例数据里有doudou.txt 注意这里的变量X是一个数据框
colnames(X) #查看列名
rownames(X) #查看行名,默认值的行名就是行号,1.2.3.4...
colnames(X)[1]<-"bioplanet"#有的公司返回数据,左上角第一格为空,R会自动补为x,用这个命令来修改
X<-read.csv(file = "huahua.txt",sep = " ",header =T,row.names=1)#最后row.names的意思是修改第一列为行名
课后作业
save(X,file=“test.RData”)这句代码如果报错object X not found,是为什么,应该怎么解决?
换小写x,是系统变量代称,X是特定变量















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









