







开源链接南瓜书PumpkinBook
第一章 .绪论
第二章 .模型评估 :个人觉得对需要写论文或实验报告,比较研究算法性能的同学帮助比较大,对注重做项目实践的同学只需了解即可。
1 误差与过拟合
即如果在m个样本中有a个样本分类错误,则错误率E=a/m;相应的1-a/m称为“精度”(accuracy),即“精度=1-错误率”,更一般地,我们把学习器的实际预测输出与样本的真实输出之间的差异称为“误差”(error)学习器在训练集上的误差称为“训练误差”(trainingerror)或“经验误差”(empirical error),在新样本上的误差称为“泛化误差”(generalization)
当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降,这种现象在机器学习中称为“过拟合”(overfitting).与“过拟合”相对的是“欠拟合”(underfitting ,这是指对训练样本的一般性质尚未学好
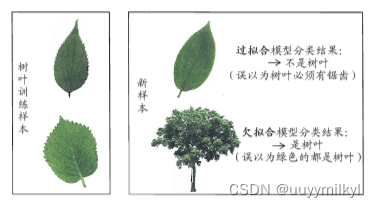
2 评估方法 个人理解更偏向是划分数据的方法
训练集: 放入模型中进行学习的数据。
测试集 : 使用一个“测试集”(testing set)来测试学习器对新样本的判别能力,然后以测试集上的“测试误差”(testingerror)作为泛化误差的近似,通常测试集应该尽可能与训练集互斥,即测试样本尽量不在训练集中出现、未在训练过程中使用过。
通常使用 留出法 。进行分层采样,例如通过采样得到70%训练集与30%测试集,需要注意的是,以2分类任务为例,若70%的数据里正例与假例为1:1,则30&的数据里正例:假例也最好接近1:1。
(拓展:目标识别中制作VOC数据集时用到的train和trainval和test,trainval是训练过程中的测试集,是为了让你在边训练边看到训练的结果,及时判断学习状态,test是训练结束后,测试训练结果的测试集。例如,训练0-500次迭代过程中,正常情况下train和trainval的loss是不断降低的,如果500-600过程中train的loss不断降低,而trainval的loss不降反升,那么就证明继续训练下去,模型只是对train dataset这部分拟合的特别好,但是泛化能力很差。与其选取600次的结果,不如选择500次的结果。而test数据集则是在训练结束后,用于推理使用的数据,检验模型识别的效果。)
此外还有 交叉验证法 自助法 。
3 性能度量 衡量模型泛化能力的标准
(这里由于需求着重看了与回归任务与南瓜书重要公式推导理解有关的部分)
3.1 回归任务中常用的性能度量是“均方误差”

3.2 ROC与AUC 可用于比较学习器性能
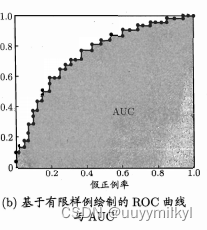
ROC曲线的具体绘制过程:
假设我们已经训练得到一个学习器f(s)f(s),现在用该学习器来对我们的8个测试样本(4个正例,4个反例,也即m^+=m^-=4m+=m−=4)进行预测,假设预测结果为:
(s1,0.77,+),(s2,0.62,−),(s3,0.58,+),(s4,0.47,+),(s5,0.47,−),(s6,0.33,−),(s7,0.23,+),(s8,0.15,−)
数字表示学习器f(s)f(s)预测该样本为正例的概率。
分类阈值设为一个不可能取到的最大值,显然这时候所有样本预测为正例的概率都一定小于分类阈值,那么预测为正例的样本个数为0,相应的真正例率和假正例率也都为0,所以此时我们可以在坐标(0,0)(0,0)处打一个点。接下来我们需要把分类阈值从大到小依次设为每个样本的预测值,也就是依次设为0.77、0.62、0.58、0.47、0.33、0.23、0.150.77、0.62、0.58、0.47、0.33、0.23、0.15,然后每次计算真正例率和假正例率,再在相应的坐标上打一个点,最后再将各个点用直线串连起来即可得到ROC曲线。
而AUC则是对ROC曲线下的面积求和,理解起来十分简单。
AUC的计算公式
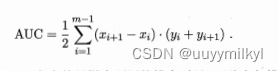
若一个学习器的ROC 曲线被另一个学习器的曲线完全 包住”,则可断言后者的性能优于前者:若两个学习器的ROC曲线发生交叉,则难以一般性地断言两者孰优孰劣,此时如果一定要进行比较,则较为合理的判据是比较ROC曲线下的面积,即AUC(AreaUnder ROC Curve)
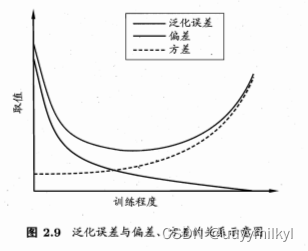
4 偏差与方差 :解释学习算法泛化能力的工具 泛化误差可分解为偏差、方差与噪声之和
对测试样本x,令y(d)为x在数据集中的标记,y为x的真实标记,f(x;D)为训练集 D上学得模型f在x上的预测输出.以回归任务为例,
期望预测为![]()


也就是说,泛化误差可分解为偏差、方差与噪声之和
第三章 .线性模型

把w替换成β b替换成u 用多元线性回归矩阵表示应该如下图(一些线性代数知识)

用一个判断好西瓜的例子理解,如书上所言
一、 线性回归
1. 理解回归 通俗的理解就是根据样本建模,使数学模型能较好地拟合出样本的变化趋势,
2. 线性代数基础运算方法 第二讲:线性代数(一)_哔哩哔哩_bilibili
3 .什么是均方误差(方差E),均方误差对应了几何中的欧氏距离
方差在之后用E(w,b)表示
因此欧式距离之和可以表示为 ![]()
2. 理解最小二乘法
·用数学求解的方式,使均方误差最小化,找到一条这样的直线,使所有样本到直线上的欧氏距离之和最小 用一张图理解它的作用,红色的线是用最小二乘法找到的直线,蓝色点是样本
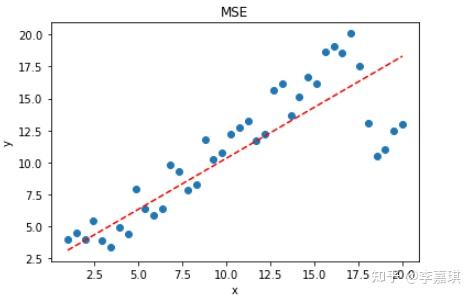
它的计算方式就是 用均方误差对w和b求偏导 ,再使其等于0

5. 线性判别
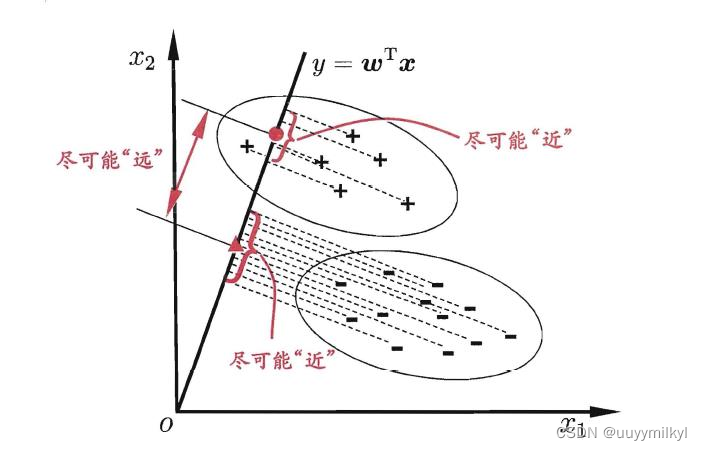
简单理解: 找到一条直线,使类别相同的样本到直线的映射尽可能相近,不通类别的中心距离尽可能相远
二、逻辑回归
逻辑回归的模型是一个非线性的函数 主要实现二分类任务
那么如果是二分类我们可以用一个这样的图是表示
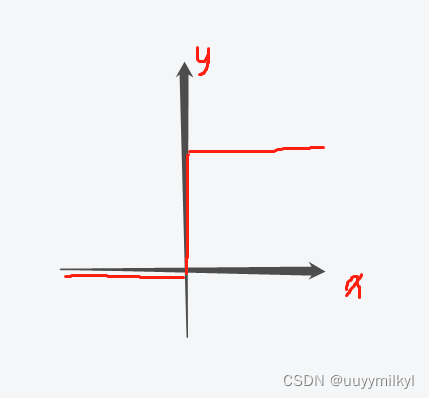
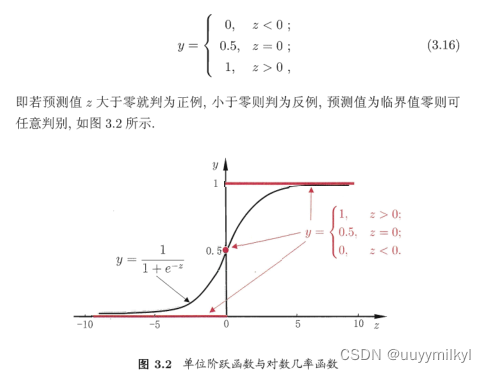
以0为界二分类,但这样的函数不可导,数学形性质较差,因此找到了sigmoid函数,用回归的思想解决分类问题
sigmoid函数既有线性函数的特点,又具有线性函数没有的特点—》能很好的处理分类问题
计算部分可以看这个视频 【机器学习 | 逻辑回归】20分钟搞懂逻辑回归 / 理论部分 / 机器学习分类问题(文刀出品)_哔哩哔哩_bilibili
三、多分类学习
第四章 .决策树














 2417
2417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









