






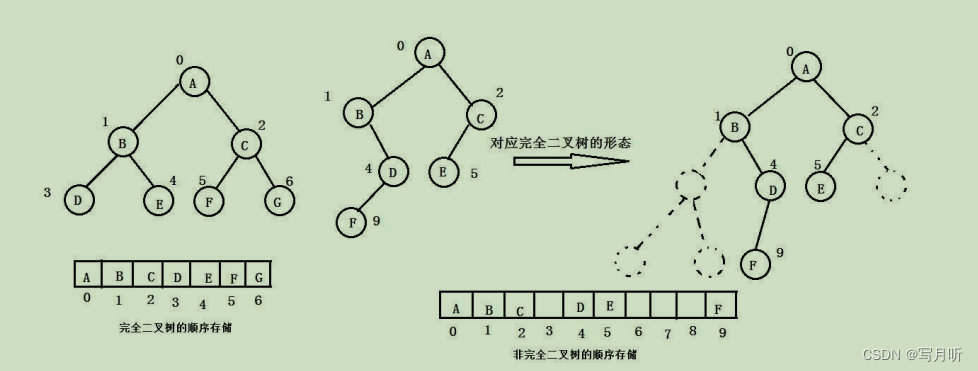
1.1二叉树的顺序结构
顺序结构, 也就是以顺序表的形式储存,但是普通的二叉树不会选择用顺序表实现,会有空间的浪费,而完全二叉树非常适合用顺序表实现。
1.2二叉树的链式结构
typedef int BinaryTreedatatype;
typedef struct BinaryTreenode
{
BinaryTreedatatype val;
struct Tree* leftchild;
struct Tree* rightchild;
}BN;链式结构也就是像链表的形式,二叉树决定了它的度不会高于2,所以在用链式结构实现的时候并没有一般的树那种问题,也就是不同的节点有不同的孩子个数。
我们统一的用上面的方式表示每一个节点。
下面我们介绍二叉树顺序结构的应用——堆
1.3堆与堆的实现
堆是一种完全二叉树,他用数组的方式存储。堆又分为小堆和大堆,小堆是指父亲结点的值总小于等于左右孩子的值,反之是大堆。
typedef int Heapdatatype;
struct Heap
{
Heapdatatype* a;
int size;
int capacity;
};堆的删除是从堆顶删除数据,也就是删除a[0],插入时只需要尾插就好。
但是我们每次插入和删除后并都能保证操作完还是一个堆。比如删除的时候,我们需要从头部删除一个数据,但是物理存储的时候只是一个数组,如果我们只是单纯删除掉一个头部的元素,那么顺序表中的结构会产生一些变化。
例如:
int a[] = {1,5,3,8,7,6};//删除前的数组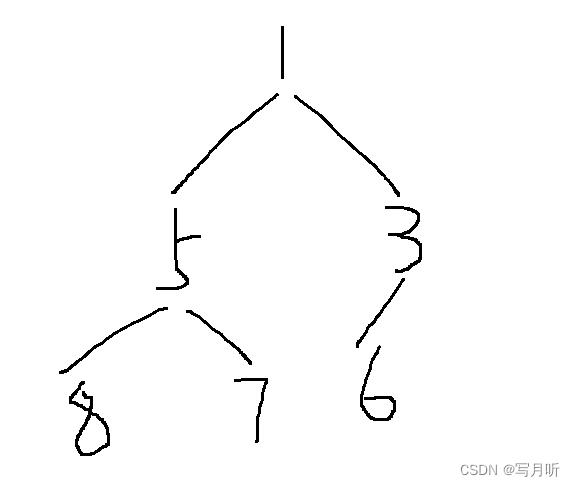
如果我们删除后只是把后面的元素前移,逻辑上的顺序就变成了。
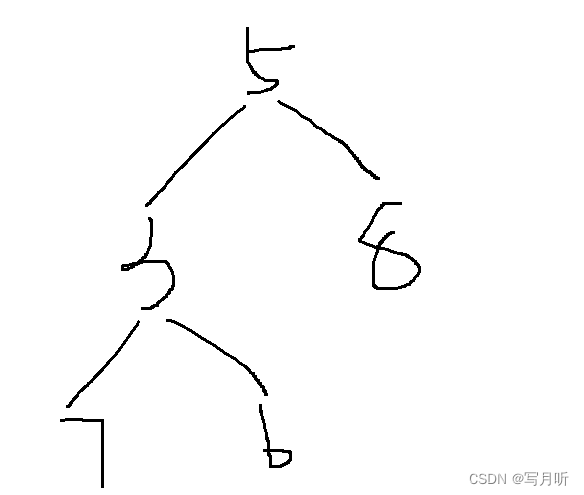
首先这个堆不再是一个小堆,其次结点之间的关系被打乱了,5和3原本是兄弟节点,现在变成了父子节点。为了使堆仍然保持之前的小堆(大堆),我们改变删除的思路,选择交换头尾两个元素,然后直接删除掉尾,再把头部的元素向下调整。
假设我们的堆是个小堆,我们要找到左右孩子中最小的,把父亲和孩子交换,然后把孩子的下标给父亲,继续计算新的孩子的下标。父亲比孩子小就结束循环。
void Swap(Heapdatatype* x, Heapdatatype* y)
{
Heapdatatype tmp = *x;
*x = *y;
*y = tmp;
}
void Adjustdown(Heapdatatype* a, int size, int parent)
{
int child = 2 * parent + 1;
while (child < size)
{
if (a[child] > a[child + 1])//选出左右孩子中最小的一个
{
child++;
}
if (a[child] < a[parent])//父亲比孩子大就交换
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent + 1;//计算新的孩子的下标
}
else//不满足条件就跳出循环
{
break;
}
}
}思路还是比较简单的,但是上面的代码还有一个小缺陷——就是我们并不能保证左右孩子都存在。所以第一个if条件需要修改。
void Adjustdown(Heapdatatype* a, int size, int parent)
{
int child = 2 * parent + 1;
while (child < size)
{
if (child+1 < size && a[child] > a[child + 1])
{
child++;
}
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}我们来测试一下,

结果是正确的。与此同时,我们的pop函数也就完成了。
void Heappop(Hp* p)
{
assert(p);
assert(!HeapEmpty(p));
Swap(&p->a[0], &p->a[p->size - 1]);
Adjustdown(p->a, p->size, 0);
}堆还有一个重要的接口函数就是push,每次我们push进去的时候都要保证堆仍然是一个小堆(大堆),所以如果push进去的元素比较小,我们就要把它向上调整,思路和上面基本一样,我直接给出代码。
void Adjustup(Heapdatatype* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[parent] > a[child])
{
Swap(&a[parent], &a[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}堆的push
void Heappush(Hp* p, Heapdatatype x)
{
assert(p);
//先考虑堆是不是为空
if (p->size == p->capacity)
{
int newcapacity = p->capacity == 0 ? 4 : 2 * p->capacity;
p->capacity = newcapacity;
p->a[p->size++] = x;
}
else
{
p->a[p->size++] = x;
}
Adjustup(p->a, p->size);
}堆还有几个接口函数,包括初始化,销毁,判空,堆的大小,取堆顶的数据,这些都比较简单,就不多赘述了。
1.4向上调整和向下调整算法的时间复杂度
下面我们考虑满二叉树的情况,计算最坏情况的时间复杂度。
向上调整时,每一层要最多有2^(i-1)个元素要调整,最多要向上调整i-1层,每一层要调整(i-1)*(2^(i-1))次,假设总共有k层,结点个数为n。
将每一层的情况求和,得到时间复杂度是O(n*logn)。
同理对向下调整进行计算,可以得到时间复杂度是O(n)。
接下来我们来讲如何对已有的数组进行建堆,目的为后面讲topK问题和堆排序打下基础。
1.5堆的创建
上面已经计算了调整算法的时间复杂度,自然我们建堆的时候应该选择向下调整算法,假设我们要建一个小堆,现在的问题是向下调整的前提是左右子树都应该是小堆。所以我们处理的方法是——从最后一个子树开始,逐个创建小堆。
void HeapCreate(Heapdatatype* a, int n)
{
//从最后一个非叶子节点开始每个树做调整。
for (int i = (n - 1 - 1) / 2;i >= 0;i--)
{
Adjustdown(a, n, i);
}
}找到最后一个非叶子节点,计算它的父亲结点,对这个父亲结点的树进行向下调整,遍历所有树,就可以调整完。
讲完堆的创建我们就可以开始讲堆的应用之一——堆排序了!
1.6堆排序
如果我们要建一个升序,那么我们要建大堆,每次都把堆顶的元素放到最后一个元素,然后不考虑最后一个元素,其余的元素视为一个新的堆,然后进行向下调整。
void Heapsort(Heapdatatype* a, int n)
{
for (int i = (n - 1 - 1) / 2;i >= 0;i--)
{
Adjustdown(a, n, i);
}
int End = n - 1;
while (End >= 0)
{
Swap(&a[0], &a[End]);//交换首尾的元素
Adjustdown(a, End, 0);//对前n-1个元素构成的堆进行向下调整的算法——目的是选出第二大的元素堆顶
End--;
}
}1.7TopK问题
生活中时常见到这些字眼——必打卡的TOP10网红景点,福建省TOP3美食..等等 这些都是TOPK算法的结果,但是实际中的算法比我们现在讲到的更复杂,需要考虑更多方面的问题。
TOPK算法的三种思路——1、堆排序 2、建立一个N个数的大堆, POP出K个元素。3、建立一个K个元素的堆(如果是升序就建大堆,降序建小堆),分别将后N-K个元素依次与堆顶的元素比较,如果比堆顶的数大就与堆顶元素交换,最后留在堆中的K个数就是前K个。
我们大概来看一下三个算法的时间复杂度和空间复杂度。
堆排序的建堆过程大概是O(N),第二个循环的复杂度是O(N*logN),所以总体的复杂度是O(N*logN)。空间复杂度是O(N)。
第二个思路的时间复杂度是O(N+K*logN)~O(N)。空间复杂度是O(N)。
第三个思路的时间复杂度O(K+(N-K)*logK) ~ O(N)。空间复杂度是O(1)。
可以看出来第三个思路虽然时间复杂度并不会比第二个优化很多,但是空间复杂度降低很多。所以我们选择第三种思路实现。
void TopK(int* a,int n,int k)
{
//先建一个K个数的小堆,再把剩下的N-K个数依次和堆顶的数比较,如果大于堆顶的数就进堆。
int* p = (int*)malloc(sizeof(int) * k);
for (int i = 0;i < k;i++)
{
p[i] = a[i];
}
for (int i = (k - 1 - 1) / 2;i >= 0;--i)
{
Adjustdown(p, k, i);
}
for (int i = k;i < n;i++)
{
if (a[i] > p[0])
{
p[0] = a[i];
Adjustdown(p, k, 0);
}
}
}














 3363
3363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









