







 本文介绍了一种名为AdvXL的高效对抗训练方法,针对大模型和大规模数据集,通过两阶段训练降低计算成本,实现在ImageNet-1K上的最强鲁棒性。研究还探讨了如何利用CLIP文本编码器处理弱标签数据,以及预训练和微调策略,显著提高了模型的鲁棒性和计算效率。
本文介绍了一种名为AdvXL的高效对抗训练方法,针对大模型和大规模数据集,通过两阶段训练降低计算成本,实现在ImageNet-1K上的最强鲁棒性。研究还探讨了如何利用CLIP文本编码器处理弱标签数据,以及预训练和微调策略,显著提高了模型的鲁棒性和计算效率。
论文: Revisiting Adversarial Training at Scale
代码: https://github.com/UCSC-VLAA/AdvXL
1. 前人缺点和本文贡献
先前的对抗训练仅针对小模型和小数据,比如说ResNet-50模型和CIFAR-10这样小并且低分别率的数据集,对抗训练针对大模型和大数据集的效果还不明朗。并且对抗训练是出了名的资源密集型,限制了它的可扩展性。为了应对这一挑战,研究人员一直在寻求更有效的对抗训练方法。例子包括Free Adversarial Training[51]和Fast Adversarial Training[58],两者都旨在降低训练成本,同时保持模型的鲁棒性对此作者提出以下贡献
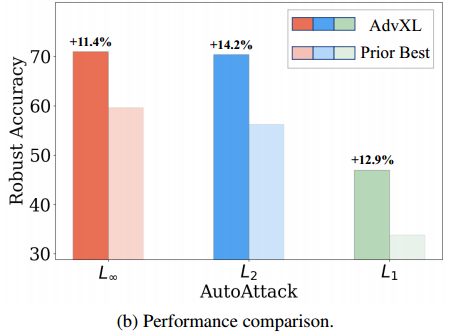
(1)引入一种高效的对抗训练方法advXL,使用两段对抗训练(twostage efficient adversarial training),以可承受的计算成本,针对大模型和大数据集(web-scale data)进行对抗性训练,实验表明advXL在ImageNet-1K+AutoAttack下建立了最强的鲁棒性,通过在DataComp-1B数据集上进行训练,我们的AdvXL使一个普通的ViT-g模型大大超过了之前对抗训练在l∞,l2-和L1 下的鲁棒精度记录,分别提高了11.4%,14.2%和12.9%。
(2)使用CLIP的text encoder作为工具让我们学习弱标签图片(web-crawled images),这种训练图片
对于规模化的对抗性训练,通常缺少精确的标签,但有相应的文本描述
2. 论文前置知识
参考笔记:https://blog.csdn.net/weixin_41712499/article/details/110878322
对抗训练基本思想——Min-Max公式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









