







1.摘要,介绍,相关工作
论文:DiffAttack: Evasion Attacks Against Diffusion-Based Adversarial Purification
代码:GitHub - kangmintong/DiffAttack
基于笔记:[论文总结] DiffAttack: Evasion Attacks Against Diffusion-Based Adversarial Purification - 知乎 (zhihu.com)
1.1 解决的问题
由于深度神经网络 (DNN) 容易受到对抗扰动动的影响,因此提高神经网络针对此类精心设计的扰动的鲁棒性变得非常重要,特别是在安全关键型应用中。 近年来,人们提出了许多防御措施,但它们再次受到更高级的自适应攻击的攻击。
最近的一种防御方法(diffusion-based purification,基于扩散的净化)利用扩散模型来净化输入图像并实现最先进的鲁棒性。根据防御使用的扩散模型的类型,基于扩散的净化可以分为基于分数的净化(使用基于分数的扩散模型)和基于DDPM的净化(去噪扩散概率模型(DDPM)).基于扩散的净化防御利用扩散模型首先用高斯噪声扩散对抗样本,然后进行采样以消除噪声。通过这种方式,由于扩散模型的训练分布是干净的,因此希望也可以消除精心设计的对抗扰动。
这篇论文提出了一种名为DiffAttack的攻击技术,旨在对抗基于扩散模型的净化防御方法。这些防御方法利用扩散模型来移除对抗样本中的精心设计的扰动,以实现最先进的鲁棒性。然而,攻击这些防御方法面临着梯度消失/爆炸、高内存成本和噪声随机性等挑战。DiffAttack通过在中间扩散步骤中引入偏差重构损失(deviated-reconstruction loss)来解决梯度问题,并提出了一种分段前向-后向算法(segment-wise forwarding-backwarding algorithm)以实现内存高效的梯度反向传播。
1.2论文的主要贡献
- 提出了DiffAttack,这是一种针对基于扩散的对抗样本净化防御的有效逃避攻击技术,包括基于分数的净化和基于DDPM的净化。
- 提出了偏差重构损失来解决梯度消失/爆炸的问题,并理论上分析了其与数据密度估计的联系。
- 提出了分段前向-后向算法来解决高内存成本的挑战,并首次对基于DDPM的净化防御进行了自适应攻击,这是由于高内存成本而难以攻击的。
- 在CIFAR-10和ImageNet上实证展示了DiffAttack相较于现有攻击方法在性能上的显著提升,特别是在大扰动半径下。
- 通过一系列消融研究,发现在均匀采样的时间步骤上添加偏差重构损失比仅在初始/最终步骤上添加更有效,以及适度的扩散长度有助于提高模型的鲁棒性。
1.3 论文前置知识
AutoAttack(APGD):Auto Attack&APGD:一种评估模型鲁棒性的弱参数攻击方法_autoattack csdn-CSDN博客
DDPM
2. 核心方法
2.1 Deviated-reconstruction loss
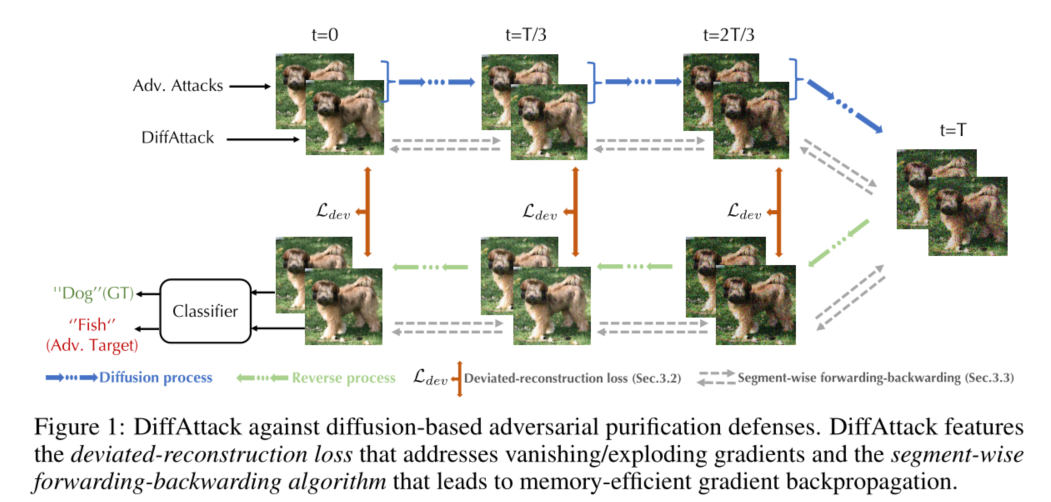
本质上,偏差重建损失在某些时间步将重建样本推离扩散样本(代码的实现是400个时间步每隔10个时间步选一个添加偏差重建损失)。 它被添加在多个中间时间步骤以缓解diffusion长采样导致的梯度消失/爆炸,噪声随机性的问题。 本文还从理论上分析了它与分数匹配损失之间的联系,并证明最大化偏差重建损失会导致扩散模型对数据分布的密度梯度的不准确估计,从而导致更高的攻击机会。
![]()
α(·)为随时间变化的权重系数,xt是第t步添加完噪声后的噪声图,x't是反向过程中相应的采样图像,d(xt, x 't)为这两张图之间的距离,代码中d的实现为mse均方损失
最大化等式8中的偏差重建损失会导致数据密度估计不准确,从而导致采样分布与干净训练分布之间的差异
2.2 Segment-wise forwarding-backwarding algorithm
测试防御方法的自适应攻击需要计算损失函数对原始样本x0的梯度,所以针对扩散净化的自适应攻击需要沿着前向传播的反方向(加噪去噪的反方向)进行反向传播,扩散长度(即总扩散时间步长)通常很大,并且在每个时间步长,深度神经网络用于估计数据分布的梯度。如果对损失函数直接调用backward这导致了一个非常深的计算图,消耗大量内存.为了克服内存消耗大的问题,本文提出了一种分段前向-后向算法,该算法基于用完就扔的思想.
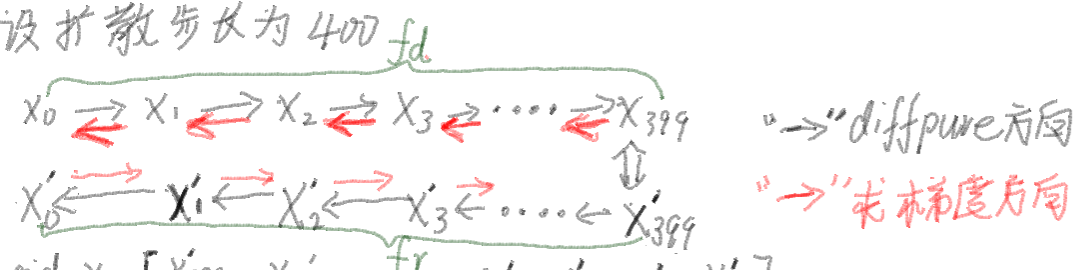
设前向传播中,加噪过程产生的图片分别是x0,x1,x2.....x399,去噪过程产生的图片分别是x'399,.....
x'1....x'0,并且我们设置![]() ,
,![]() ,当我们要求L对x't+1的梯度时,可以使用下面的等式
,当我们要求L对x't+1的梯度时,可以使用下面的等式
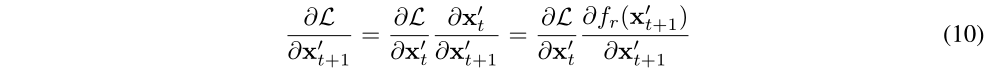
也就是说我们只需要存储L对x't的梯度,fr,x't+1就能够求出求出L对x't+1的梯度,到下一步计算L对x't+2的梯度时,L对x't的梯度和x't+1均可舍弃,即t+2时刻梯度的计算只需要t+1时刻计算图存储的梯度,存储t时刻梯度的计算图此时就可以舍弃,从而使得在整个反向传播求梯度的过程中,我们只需要存储一个梯度的计算图,从而节省了内存成本.忽略存储样本引起的内存成本(与计算图相比较小),DiffAttack实现了 O(1) 内存成本。

个人解读(不一定正确):整个从x0到x'0的加噪去噪过程如果让pytorch直接跟踪梯度,会产生庞大的计算图(因为x1,x2....x399 x'399 x'398....x'1 x'0等都会算进去),所以进行diffpure操作和把x'0放进分类器得到损失的整个过程都不能用进行梯度跟踪,但把x'0放进去分类器中求得的损失L此时和x0没有关系,没办法直接求L对x0的梯度,只能新开梯度跟中,x'1采样得到新x'0,然后新x'0对x'1求导得到L对x'1的导数(不能够直接使用iffpure过程的x'0,因为这个x'0的生成没有梯度跟踪),然后一直往回走到x0,才求得L对x0的导数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2007
2007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









