







SPP-Net是出自2015年发表在IEEE上的论文-《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》。
在此之前,所有的神经网络都是需要输入固定尺寸的图片,比如224*224(ImageNet)、32*32(LenNet)、96*96等。这样对于我们希望检测各种大小的图片的时候,需要经过crop,或者warp等一系列操作,这都在一定程度上导致图片信息的丢失和变形,限制了识别精确度。而且,从生理学角度出发,人眼看到一个图片时,大脑会首先认为这是一个整体,而不会进行crop和warp,所以更有可能的是,我们的大脑通过搜集一些浅层的信息,在更深层才识别出这些任意形状的目标。

为什么要固定输入图片的大小?
卷积层的参数和输入大小无关,它仅仅是一个卷积核在图像上滑动,不管输入图像多大都没关系,只是对不同大小的图片卷积出不同大小的特征图,但是全连接层的参数就和输入图像大小有关,因为它要把输入的所有像素点连接起来,需要指定输入层神经元个数和输出层神经元个数,所以需要规定输入的feature的大小。
因此,固定长度的约束仅限于全连接层。以下图为例说明:
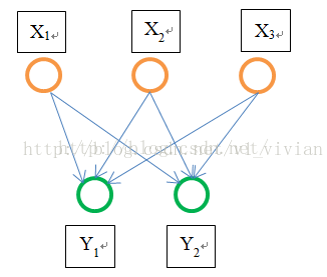
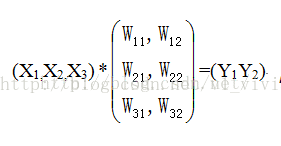
作为全连接层,如果输入的x维数不等,那么参数w肯定也会不同,因此,全连接层是必须确定输入,输出个数的。
SPP-Net是如何调整网络结构的?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









