







 本文详细介绍了维特比算法,一种用于寻找最有可能产生观测事件序列的隐含状态序列的动态规划方法,包括其核心思想、递推公式以及在机器学习中的应用实例。
本文详细介绍了维特比算法,一种用于寻找最有可能产生观测事件序列的隐含状态序列的动态规划方法,包括其核心思想、递推公式以及在机器学习中的应用实例。
章节目录
机器学习系列笔记,主要参考李航的《机器学习方法》,见参考资料。
第一章 机器学习简介
第二章 感知机
第三章 支持向量机
第四章 朴素贝叶斯分类器
第五章 Logistic回归
第六章 线性回归和岭回归
第七章 多层感知机与反向传播【Python实例】
第八章 主成分分析【PCA降维】
第九章 隐马尔可夫模型
第十章 奇异值分解
维特比算法是一种动态规划算法用于寻找最有可能产生观测事件序列的隐含状态序列.
一、维特比算法核心思想
viterbi维特比算法解决的是篱笆型的图的最短路径问题,图的节点按列组织,每列的节点数量可以不一样,每一列的节点只能和相邻列的节点相连,不能跨列相连.
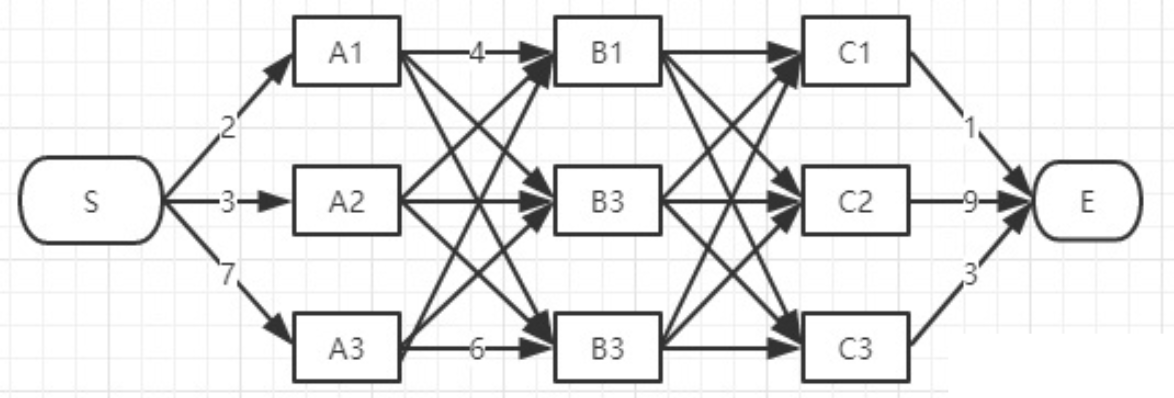
过程非常简单:
-
为了找出S到E之间的最短路径,我们先从S开始从左到右一列一列地来看。
-
首先起点是S,从S到A列的路径有三种可能:S-A1、S-A2、S-A3,如下图:

S-A1、S-A2、S-A3中的哪一段都有可能是全局最短路径的备选项,我们继续往右看,到了B列。按B列的B1、B2、B3逐个分析:
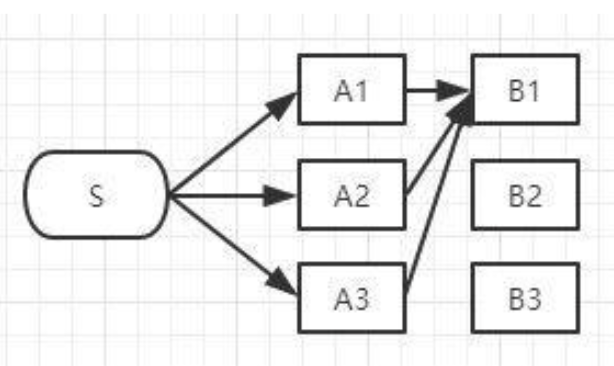
如上图,经过B1的所有路径只有3条:
- S-A1-B1
- S-A2-B1
- S-A3-B1
以上这三条路径,各节点距离加起来对比一下,我们就可以知道其中哪一条是最短的。假设S-A3-B1是最短的,那么我们就知道了经过B1的所有路径当中S-A3-B1是最短的,其它两条路径路径S-A1-B1和S-A2-B1都比S-A3-B1长,绝对不是目标答案,可以删掉了,删掉了不可能是答案的路径,就是viterbi算法(维特比算法)的重点,因为后面我们再也不用考虑这些被删掉的路径了,现在经过B1的所有路径只剩一条路径了,如下图:
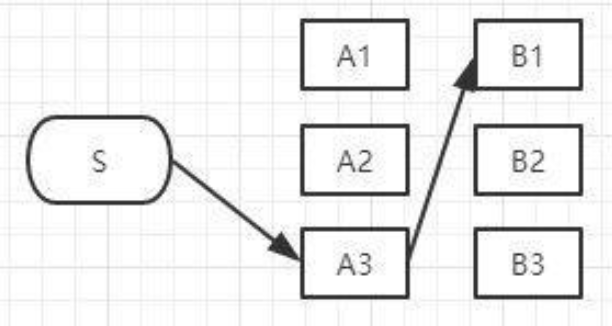
以此类推后面的结点……
二、viterbi算法
viterbi算法的核心主要是:
- 定义时刻t每个状态 s i s_i si的路径概率 δ t ( i ) \delta_t(i) δt(i).
- δ t ( i ) \delta_t(i) δt(i)的递推公式.
- 回溯每个时刻的最优状态.
给定 λ = ( A , B , π ) \lambda=(A,B,\pi) λ=(A,B,π)和长度为 T T T的观测序列
0 = { O 1 , O 2 , ⋯ , O T } , \mathbf{0}=\{O_1,O_2,\cdots,O_T\}, 0={O1,O2,⋯,OT},
求与观测序列O最匹配的状态序列
X = { X 1 , X 2 , ⋯ , X T } . \mathbf{X}=\{X_1,X_2,\cdots,X_T\}. X={X1,X2,⋯,XT}.
相当于找到使得 P ( X ∣ 0 , λ ) P(X|0,\lambda) P(X∣0,λ)最大的状态序列 X ∗ X^* X∗, 即
X
∗
=
argmax
X
P
(
X
∣
O
,
λ
)
,
\mathbf{X}^*=\underset{\mathbf{X}}{\operatorname*{argmax}}P(\mathbf{X}|\mathbf{O},\lambda),
X∗=XargmaxP(X∣O,λ),所求的最优状态序列$ X^*$也可以定义为
X
∗
=
argmax
X
P
(
X
,
O
∣
λ
)
.
\mathbf{X}^*=\underset{\mathbf{X}}{\operatorname*{argmax}}P(\mathbf{X},\mathbf{O}|\lambda).
X∗=XargmaxP(X,O∣λ).考虑时刻
t
≤
N
t\leq N
t≤N 状态为
s
i
(
1
≤
i
≤
N
)
s_i\quad(1\leq i\leq N)
si(1≤i≤N) 的所有单个路径
(
X
1
,
X
2
,
⋯
,
X
t
−
1
,
X
t
=
s
i
)
.
(X_1,X_2,\cdots,X_{t-1},X_t=s_i).
(X1,X2,⋯,Xt−1,Xt=si).所对应的概率的最大值为(也就是每个时刻每个状态对应观察序列的概率,可以递推):
δ
t
(
i
)
=
max
X
1
,
X
2
,
.
.
.
,
X
t
−
1
P
(
X
t
=
s
i
,
X
1
,
X
2
,
⋯
,
X
t
−
1
,
O
1
,
O
2
,
⋯
,
O
t
)
,
\delta_t(i)=\max\limits_{X_1,X_2,...,X_{t-1}}P(X_t=s_i,X_1,X_2,\cdots,X_{t-1},O_1,O_2,\cdots,O_t),
δt(i)=X1,X2,...,Xt−1maxP(Xt=si,X1,X2,⋯,Xt−1,O1,O2,⋯,Ot),
显然对最优路径
X
∗
X^*
X∗而言,
P
(
X
∗
,
O
∣
λ
)
=
max
1
≤
i
≤
N
δ
T
(
i
)
,
P(X^*,O|\lambda)=\max\limits_{1\leq i\leq N}\delta_T(i),
P(X∗,O∣λ)=1≤i≤NmaxδT(i),而且
X
T
∗
=
arg
max
s
i
,
1
≤
i
≤
N
δ
T
(
i
)
.
X_T^* = \arg\max\limits_{s_i,1\leq i\leq N} \delta_T( i) .
XT∗=argsi,1≤i≤NmaxδT(i).
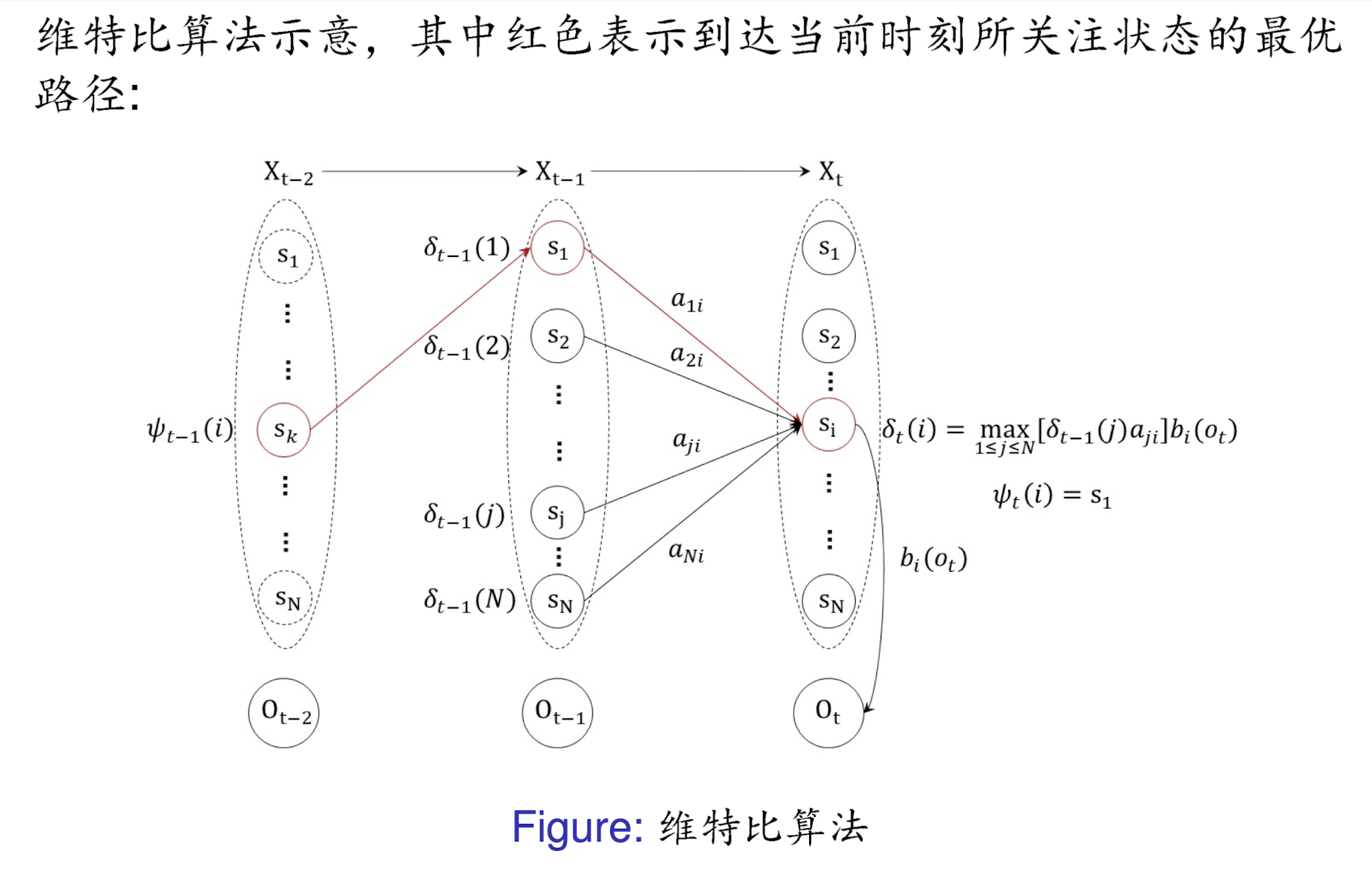
结合第一部分的动态规划思想,路径最大概率
δ
t
(
i
)
(
2
≤
t
≤
T
)
\delta_t(i)(2\leq t\leq T)
δt(i)(2≤t≤T)的递推公式如下:
δ
t
(
i
)
=
max
1
≤
j
≤
N
[
δ
t
−
1
(
j
)
a
j
i
]
b
i
(
O
t
)
,
i
=
1
,
2
,
⋯
,
N
.
\delta_t(i)=\max_{1\leq j\leq N}[\delta_{t-1}(j)a_{ji}]b_i(O_t),\mathrm{~}i=1,2,\cdots,N.
δt(i)=1≤j≤Nmax[δt−1(j)aji]bi(Ot), i=1,2,⋯,N.由此我们可以递推计算出
δ
T
(
i
)
,
i
=
1
,
2
,
⋯
,
N
.
\delta_T(i),\quad i=1,2,\cdots,N.
δT(i),i=1,2,⋯,N.完整算法框架如下:

参考资料
- 如何通俗的理解维特比算法
- 李航. 机器学习方法. 清华大学出版社, 2022.















 641
641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









