







前言
4.19日凌晨正准备睡觉时,突然审稿项目组的文弱同学说:Meta发布Llama 3系列大语言模型了,一查,还真是
本文以大模型开发者的视角,基于Meta官方博客的介绍:Introducing Meta Llama 3: The most capable openly available LLM to date,帮你迅速梳理下LLama的关键特征,并对比上一个版本的LLama2,且本文后续,将更新用我司paper-review数据集微调llama3的训练过程
第一部分 Meta发布Llama 3:所有大模型开发者的福音
1.1 Llama 3的性能
1.1.1 在多个榜单上超越Google的gemma 7B、Mistral 7B
此次发布的Llama 3有两个版本:8B 和 70B。由于预训练和指令微调的加强,模型在推理、代码生成和指令跟踪等方面的能力得到比较大的提高,最终在多个榜单上超越Google的gemma 7B、Mistral 7B(当然了,我还是得说一句,榜单肯定能够说明一些东西,但不代表全部)

1.1.2 一套专门的评估数据集:1800个prompt 涵盖12类任务
为了更好的评估llama3的性能,Meta开发了一套新的高质量人类评估集。该评估集包含 1,800 个prompt,涵盖 12 个关键用例:寻求建议、头脑风暴、分类、封闭式问答、编码、创意写作、提取、塑造角色/角色、开放式问答、推理、重写和总结
且为了防止模型在此评估集上过度拟合,即使Meta的建模团队也无法访问它(说白了,保证评估数据集中的数据不被模型事先学到)
下图显示了Meta针对 Claude Sonnet、Mistral Medium 和 GPT-3.5 对这些类别和提示进行人工评估的汇总结果(compared to competing models of comparable size in real-world scenarios,即PK的开源模型也都是70B左右的大小)

且llama3的预训练模型这些榜单上PK同等规模的其他模型时,亦有着相对突出的表现

1.2 Llama 3:模型架构、预训练数据、扩大预训练和指令微调
1.2.1 模型架构:继续transformer解码器架构、分组查询注意力、8K上下文
和Llama 2一样,Llama 3 继续采用相对标准的decoder-only transformer架构,但做了如下几个关键的改进
- Llama 3 使用具有 128K tokens的tokenizer
相当于,一方面,分词器由 SentencePiece 换为了 Tiktoken,与 GPT4 保持一致,可以更有效地对语言进行编码
二方面,Token词表从LLAMA 2的32K拓展到了128K
基准测试显示,Tiktoken提高了token效率,与 Llama 2 相比,生成的token最多减少了 15%「正由于llama3具有更大的词表,比llama2的tokenizer具有更大的文本压缩率,所以你会看到在此文《从提升大模型数据质量的三大要素(含审稿GPT第4.6版、第4.8版、第5版)到Reviewer2的实现》中,我司七月审稿项目组发现,在统计同样的paper-review数据集时,llama3统计到的token数更少」 - 为了提高推理效率,Llama 3在 8B 和 70B 都采用了分组查询注意力(GQA),根据相关实验可以观察到,尽管与 Llama 2 7B 相比,模型的参数多了 1B,但改进的分词器效率和 GQA 有助于保持与 Llama 2 7B 相同的推理效率
值得指出的是,上一个版本的llama 2的34B和70B才用到了GQA「详见LLaMA的解读与其微调(含LLaMA 2):Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙的第3.2节LLaMA2之分组查询注意力——Grouped-Query Attention」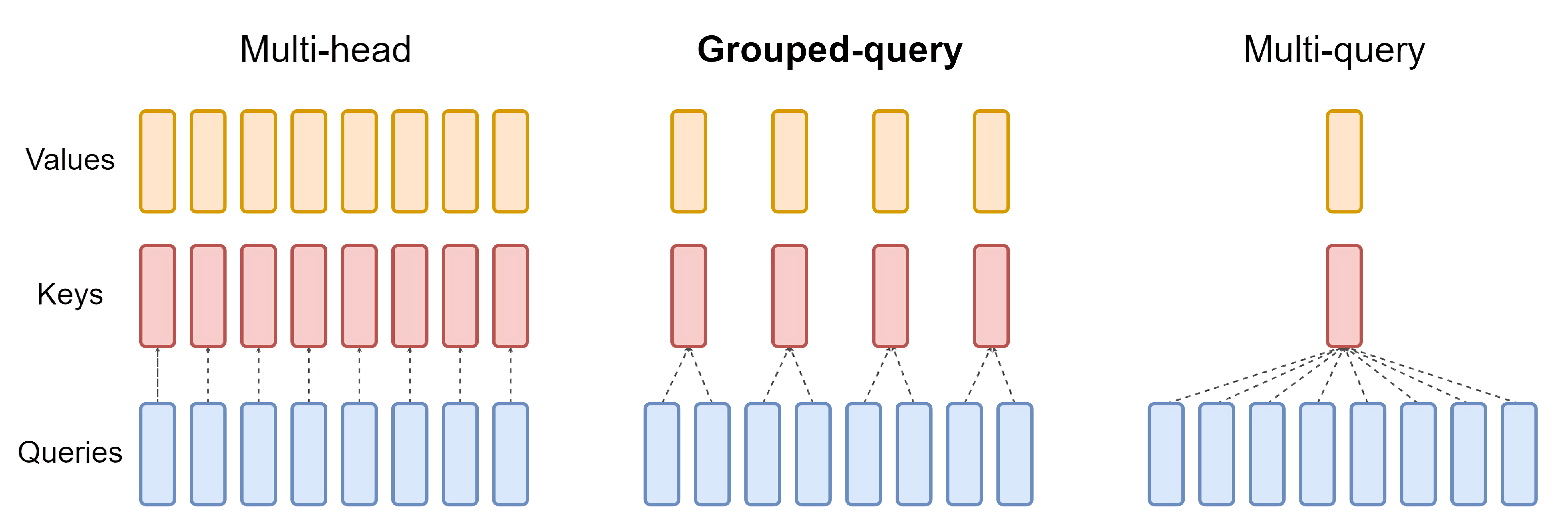

- 在 8,192 个token的序列上训练模型,且通过掩码操作以确保自注意力不会跨越文档边界
这点相比llama 2是一个进步,毕竟llama 2的上下文长度还只有4K,所以我司审稿项目组在用平均长度8.5K的paper-review数据集去微调llama2时,不得已必须用上longlora/longqlora这类扩展长度的技术(详见:七月论文审稿GPT第2版:用一万多条paper-review数据微调LLaMA2 7B最终反超GPT4)
于此,可以得到Llama3的模型架构图如下图的右侧所示(这里也有关于llama系列的解读,这则是llama系列的视频解读版)

1.2.2 训练数据:15T预训练数据
做大模型开发的都知道,数据的重要性不言而喻,为进一步提高模型的性能
- Llama 3 经过超过 15T token的预训练(比 Llama 2 使用的数据集大七倍,并且包含四倍多的代码,要知道,llama 2的训练数据才2T个token,即2万亿个token),这些数据全部从公开来源收集
- Llama 3 预训练数据集的中,其中有超过5%的部分由涵盖 30 多种语言的高质量非英语数据组成。当然,大概率上,这些语言的性能水平不会与英语相同(原因在于其只占5%罗)
- 为了确保 Llama 3 接受最高质量数据的训练,他们还开发了一系列数据过滤管道。这些管道包括使用启发式过滤器、NSFW 过滤器、语义重复数据删除方法和文本分类器来预测数据质量
且使用 Llama 2 作为文本质量分类器 为 Llama 3 生成训练数据 - 还进行了广泛的实验,以评估在最终预训练数据集中混合不同来源的数据的最佳方法。这些实验使能够选择一个数据组合,确保 Llama 3 在各种用例(包括琐事问题、STEM、编码、历史知识等)中表现良好
1.2.3 扩大预训练规模
为了有效利用 Llama 3 模型中的预训练数据,他们投入了大量精力来扩大预训练规模。具体来说
- 为下游基准评估制定了一系列详细的缩放法则。这些缩放法则使我们能够选择最佳的数据组合,且使我们能够在实际训练模型之前预测最大模型在关键任务上的性能(例如,在 HumanEval 基准上评估的代码生成 - 见上文)
比如在 Llama 3 的开发过程中,对缩放行为进行了一些新的观察。例如,虽然 8B 参数模型的 Chinchilla 最佳训练计算量对应于约 200B 个token,但发现即使在模型建立之后,模型性能仍在继续提高接受了两个数量级以上的数据训练
- 为了训练Llama 3的400B的版本,Meta结合了三种类型的并行化:数据并行化、模型并行化和管道并行化(关于这三种并行训练方法的介绍,可以参见此文:《大模型并行训练指南:通俗理解Megatron-DeepSpeed之模型并行与数据并行》)
当同时在 16K GPU 上进行训练时,可实现每个 GPU 超过 400 TFLOPS 的计算利用率,当然,最终在两个定制的24K GPU 集群上进行了训练
且
综合起来,这些改进使 Llama 3 的训练效率比 Llama 2 提高了约三倍
1.2.4 指令微调:SFT之外,组合了拒绝采样、PPO和DPO
为了充分释放预训练模型在聊天用例中的潜力,我们还对指令调整方法进行了创新。我们的后训练方法是:监督微调SFT、拒绝采样、近端策略优化PPO(关于PPO详见此文《强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO》的第4部分),和直接偏好优化DPO的组合(关于DOP则见此文:《RLHF的替代之DPO原理解析:从RLHF、Claude的RAILF到DPO、Zephyr》)
- SFT 中使用的prompt质量,以及 PPO 和 DPO 中使用的偏好排名对对齐模型的性能有着巨大的影响
最终,在模型质量方面的一些最大改进来自于仔细整理这些数据并对人类标注者提供的标注或注释进行多轮质量保证 - 通过 PPO 和 DPO 从偏好排名中学习也极大地提高了 Llama 3 在推理和编码任务上的性能。即如果你向模型提出一个它难以回答的推理问题,该模型有时会产生正确的推理轨迹:模型知道如何产生正确的答案,但不知道如何选择它,但对“偏好排名的训练”使模型能够学习如何选择它
1.3 其他:与相关开源库的兼容、LLama3的部署
1.3.1 与其他开源库的兼容:比如PyTorch 原生库之torchtune、LangChain等
- 提供了新的信任和安全工具,包括 Llama Guard 2 和 Cybersec Eval 2 的更新组件,并引入了 Code Shield——一种用于过滤 LLM 生成的不安全代码的推理时间防护栏
- 还与torchtune共同开发了 Llama 3
这个torchtune 是新的 PyTorch 原生库,可以轻松地使用 LLM 进行创作、微调和实验
且torchtune 提供完全用 PyTorch 编写的内存高效且可破解的训练方法,该库与 Hugging Face、Weights & Biases 和 EleutherAI 等流行平台集成,甚至支持 Executorch,以便在各种移动和边缘设备上运行高效推理 - 此外,作者团队还提供了关于「将 Llama 3 与 LangChain 结合使用」的全面入门指南
1.3.2 负责任地部署
为了方便让开发者负责任地部署llama3,他们采用了一种新的系统级方法

且指令微调模型已经通过内部和外部的努力进行了安全红队(测试)
红队方法利用人类专家和自动化方法来生成对抗性提示,试图引发有问题的响应。例如,我们应用全面的测试来评估与化学、生物、网络安全和其他风险领域相关的滥用风险
所有这些努力都是迭代的,并用于为正在发布的模型进行安全微调提供信息。可以在模型卡中详细了解我们的努力
- Llama Guard 模型旨在成为快速响应安全的基础,并且可以根据应用需求轻松进行微调以创建新的分类法。作为起点,新的 Llama Guard 2 使用最近宣布的MLCommons 分类法,努力支持这一重要领域行业标准的出现
- 此外,CyberSecEval 2 在其前身的基础上进行了扩展,添加了对 LLM 允许滥用其代码解释器的倾向、攻击性网络安全功能以及对提示注入攻击的敏感性的测量(在我们的技术论文中了解更多信息)
- 最后,我们引入了 Code Shield,它增加了对 LLM 生成的不安全代码的推理时过滤的支持。这可以缓解不安全代码建议、代码解释器滥用预防和安全命令执行方面的风险
更多参见负责任使用指南(RUG),且正如在 RUG 中概述的那样,Meta建议根据适合应用程序的内容指南检查和过滤所有输入和输出
Llama 3 很快将在所有主要平台上提供,包括云提供商、模型 API 提供商等等,更多见:Getting started with Meta Llama
有关如何利用所有这些功能的示例,请查看Llama Recipes,其中包含所有的开源代码,这些代码可用于从微调到部署再到模型评估的所有内容
1.3.3 Llama 3 的下一步是什么?
llama 3中最大的模型有超过 400B 个参数,不过这个模型仍在训练中(后续,Meta将发布多个具有新功能的模型,包括多模态、以多种语言交谈的能力、更长的上下文窗口和更强的整体功能。且后续还将发布一份详细的研究论文)

第二部分 Gradient AI:58行代码把Llama 3扩展到100万上下文
2.1 Gradient AI把LLama3的长度扩展到16K及其背后的原理
2.1.1 mattshumer/Llama-3-8B-16K:将 Llama-3-8B 的上下文长度扩展到16K
HyperWriteAI 的 CEO Matt Shumer在其推特主页(https://twitter.com/mattshumer_/status/1782576964118675565)上宣布,他自己将 Llama-3-8B 的上下文窗口翻了一番(8k→16K):mattshumer/Llama-3-8B-16K (不过可惜不是instruct模型)
以下是来自huggingface的简介
- This is an extended (16K) context version of LLaMA 3 8B (base, not instruct). Trained for five hours on 8x A6000 GPUs, using the Yukang/LongAlpaca-16k-length dataset(即longlora作者弄的16k 数据集:https://huggingface.co/datasets/Yukang/LongAlpaca-16k-length).
- rope_theta was set to 1000000.0. Trained with Axolotl(即一个开源的微调框架:GitHub - OpenAccess-AI-Collective/axolotl: Go ahead and axolotl questions)
我一开始还挺好奇,他到底用的啥技术,深入一了解,原来所用的技术来自国外的一家AI初创公司Gradient AI,且他们也在不断把LLama的长度拉长
- Llama-3-8B-Instruct-262k
- Llama-3-70B-Gradient-524k
- Llama-3 8B Gradient Instruct 1048k
- Llama-3 70B Gradient Instruct 1048k
2.1.2 扩展到16K:针对位置编码的base参数(rope_theta)从50万扩大到100万
把LLama3的长度扩展到16K的具体实现步骤如下
- 首先,微调得到一个加长版的模型
如本部分开头提到的,“mattshumer/Llama-3-8B-16K”的huggingface页面上有介绍到把rope_theta参数扩大到2倍(因为对于这个模型而言,长度从8K到16K扩展2倍,则对应参数扩大2倍,而Llama 3的rope_theta设置的50 0000,故rope_theta从50 0000扩大到100 0000)
而这个rope_theta参数其实指的是位置编码概念里的“base”,也就是以前大多模型设置为10000的那个参数,并不是旋转角度
“还记得RoPE的构造基础是Sinusoidal位置编码?可以改写为下面的公式「以下内容引用自此文的2.1.2节(注,dear friends,莫慌,如果不太理解是个啥意思,或者你想理解下述公式的来龙去脉,请详看此篇详解位置编码的文章 )

其中,
而对base做放大是ntk-aware插值的操作「如果对ntk-aware插值不太熟悉,建议先看下此文《大模型长度扩展综述:从直接外推ALiBi、插值PI、NTK-aware插值、YaRN到S2-Attention》的第三部分」, 故在当下这个把LLama 3的rope_theta从50 0000放大到100 0000的场景中,就是,而这个10000这就是上面说的'base' ”
的ntk-aware插值
- 有了扩展好上下文的微调模型之后,使用开源工具Mergekit比较微调模型和基础模型,提取参数的差异成为LoRA
- 同样使用Mergekit,即通过下述代码可以把提取好的LoRA合并到其他同架构模型中了(代码地址为:https://gist.github.com/ehartford/731e3f7079db234fa1b79a01e09859ac,作者为Eric Hartford,这段代码是一个Python脚本,用于将多个适配器模型合并到一个基础模型中,并且可以选择将合并后的模型推送到模型仓库或仅保存到本地目录。代码使用了`transformers`和`peft`库来处理模型和适配器,`torch`用于模型的加载和操作,`os`用于文件路径处理,`argparse`用于解析命令行参数)
# This supports merging as many adapters as you want. # python merge_adapters.py --base_model_name_or_path <base_model> --peft_model_paths <adapter1> <adapter2> <adapter3> --output_dir <merged_model> # 导入transformers库中的模型和分词器 from transformers import AutoModelForCausalLM, AutoTokenizer from peft import PeftModel # 导入PEFT模型类 import torch # 导入PyTorch库 import os # 导入操作系统接口库 import argparse # 导入命令行解析库 def get_args(): parser = argparse.ArgumentParser() # 创建命令行解析器 parser.add_argument("--base_model_name_or_path", type=str) # 添加命令行参数:基础模型路径或名称 parser.add_argument("--peft_model_paths", type=str, nargs='+', help="List of paths to PEFT models") # 添加命令行参数:PEFT模型的路径列表 parser.add_argument("--output_dir", type=str) # 添加命令行参数:输出目录 parser.add_argument("--device", type=str, default="cpu") # 添加命令行参数:设备类型,默认为CPU parser.add_argument("--push_to_hub", action="store_true") # 添加命令行参数:是否推送到Hugging Face模型中心 parser.add_argument("--trust_remote_code", action="store_true") # 添加命令行参数:是否信任远程代码 return parser.parse_args() # 解析命令行输入的参数 def main(): args = get_args() # 获取命令行参数 if args.device == 'auto': # 自动设备映射 device_arg = {'device_map': 'auto'} else: device_arg = {'device_map': {"": args.device}} # 指定设备映射 print(f"Loading base model: {args.base_model_name_or_path}") # 打印加载基础模型的信息 base_model = AutoModelForCausalLM.from_pretrained( args.base_model_name_or_path, return_dict=True, torch_dtype=torch.float16, trust_remote_code=args.trust_remote_code, **device_arg ) # 加载基础模型 model = base_model # 将基础模型赋值给model变量 for peft_model_path in args.peft_model_paths: # 遍历所有PEFT模型路径 print(f"Loading PEFT: {peft_model_path}") # 打印加载PEFT模型的信息 model = PeftModel.from_pretrained(model, peft_model_path, **device_arg) # 加载PEFT模型 print(f"Running merge_and_unload for {peft_model_path}") # 打印正在合并和卸载模型的信息 model = model.merge_and_unload() # 合并并卸载模型 tokenizer = AutoTokenizer.from_pretrained(args.base_model_name_or_path) # 加载分词器 if args.push_to_hub: # 如果指定推送到模型中心 print(f"Saving to hub ...") # 打印保存到模型中心的信息 model.push_to_hub(f"{args.output_dir}", use_temp_dir=False) # 推送模型到模型中心 tokenizer.push_to_hub(f"{args.output_dir}", use_temp_dir=False) # 推送分词器到模型中心 else: model.save_pretrained(f"{args.output_dir}") # 保存模型到指定目录 tokenizer.save_pretrained(f"{args.output_dir}") # 保存分词器到指定目录 print(f"Model saved to {args.output_dir}") # 打印模型保存的路径 if __name__ == "__main__": main()
值得强调的是,「把 b 设置成50万」的这个做法大有来头
-
我在23年7月份时看TTT论文的过程中(附录C,page 31页),提到了llama long,而llama long中提到:其为了减少每个维度的旋转角度(which essentially reduces the rotation angles of each dimension),而将超参数“基频(base frequency)b”从10000增加到500000(increasing the “base frequency b” of ROPE from 10, 000 to 500, 000)

-
继续溯源下去,发现其实在llama long之前,最早是由一Reddit网友bloc97发现的这个NTK-aware方法
2.1.3 针对“位置编码的base参数(rope_theta)扩大”背后溯源的过程
刚开始阿荀因为rope_theta这个取名
- 误把这个参数曲解为RoPE概念中的“旋转角度theta”,而如果是按照位置插值的思路,要扩展长度理当是缩小旋转角度而不是放大才对,所以就去看这个参数具体在代码中是负责什么部分

- 发现是参数赋值进去以后,是RoPE概念中的“base”(而非RoPE概念中的旋转角度theta),从而也就顺理成章的得把base扩大到2倍,对应到具体的方法中,就是ntk-aware插值(对base做放大)
class LlamaRotaryEmbedding(nn.Module): def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0): super().__init__() # 调用父类的初始化函数 self.scaling_factor = scaling_factor # 缩放因子,用于调整位置编码的尺度 self.dim = dim # 嵌入的维度 self.max_position_embeddings = max_position_embeddings # 最大位置嵌入数量 self.base = base # 计算频率的基数 # 计算逆频率,用于生成位置嵌入的频率部分 inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(device) / self.dim)) self.register_buffer("inv_freq", inv_freq, persistent=False) # 将逆频率注册为模型的一个缓冲区 # 为了向后兼容,注册余弦和正弦的缓存值 self.max_seq_len_cached = max_position_embeddings # 缓存的最大序列长度 t = torch.arange(self.max_seq_len_cached, device=device, dtype=torch.int64).type_as(self.inv_freq) # 生成位置序列 t = t / self.scaling_factor # 应用缩放因子 freqs = torch.outer(t, self.inv_freq) # 计算每个位置的频率 # 与原始论文不同,这里使用了不同的排列方式以获得相同的计算结果 emb = torch.cat((freqs, freqs), dim=-1) # 拼接频率以创建嵌入 # 注册余弦和正弦值的缓存,将它们转换为默认数据类型 self.register_buffer("_cos_cached", emb.cos().to(torch.get_default_dtype()), persistent=False) self.register_buffer("_sin_cached", emb.sin().to(torch.get_default_dtype()), persistent=False)而对于上面的这行代码
# 计算逆频率,用于生成位置嵌入的频率部分 inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(device) / self.dim))其所对应的公式表达则是
其中
base 是一个基数常数,例如10000 (而上面说了,LLama 3设置的50万)
dim 是嵌入的维度总数
torch.arange(0,dim,2)则代表生成一个从0开始,步长为2,到 dim(但不包括dim)的序列
2.2 把LLama3长度扩展到100万背后的原理:NTK-aware插值
再后来,Gradient AI再通过类似的方式把rope_theta继续放大,使得其长度可以达到100万,具体实现方法是
- 调整位置编码:用NTK-aware插值初始化RoPE theta的最佳调度,进行优化,防止扩展长度后丢失高频信息
相当于原来llama 3的长度为8000,然后rope_theta这个参数是50万
那要把长度扩展到100万的话,则应该是把rope_theta这个参数扩大:从50万扩大“100万/8000 = 125倍”,毕竟长度扩展多少倍则对应的这个rope_theta扩大多少倍 - 渐进式训练:使用UC伯克利Pieter Abbeel团队提出的Blockwise RingAttention方法扩展模型的上下文长度
且团队通过自定义网络拓扑在Ring Attention之上分层并行化,更好地利用大型GPU集群来应对设备之间传递许多KV blocks带来的网络瓶颈,最终使模型的训练速度提高了33倍
至于llama3的微调见:七月论文审稿GPT第5版:拿我司七月的早期paper-7方面review数据集微调LLama 3


















 1501
1501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











