







前言
成就本文有两个因素(首发于23年10月,修订于24年5月)
- 第一个因素是,我带长沙的LLM项目团队做论文审稿GPT这个项目时,遇到了不少工程方面的问题(LLM方面的项目做多了,你会逐步发现,现在模型没啥秘密 技术架构/方向选型也不是秘密,最终都是各种工程细节的不断优化),比如数据的问题,再比如大模型本身的上下文长度的问题
前者已经得到了解决,详见此文《七月论文审稿GPT第1版:通过3万多篇paper和10多万的review数据微调RWKV》的第三部分
但后者相对麻烦些,原因在于审稿语料中一万多篇论文的长度基本都在万词以上,而通过本博客内之前的文章可以得知大部分模型的上下文长度基本都没超过8K模型 对应的上下文长度 论文审稿表现(凡是8K以内的长度均不够) GPT3.5 4-16K(后11.7日统一到了16K) 16K效果待测
另,23年11.7日开放了3.5的16K微调接口GPT4 8K-32K(后11.7日升级到128K) 待测 LLaMA 2048 LLaMA2 4096 LLaMA2-long(其23年9.27发的论文) 32K 效果待测 基于LongLoRA技术的LongAlpaca-7B/13B/70B 32K以上 效果待测 Baichuan-7B/13B、Baichuan 2-7B/13B 4096 ChatGLM-6B 2000 ChatGLM2-6B 8-32K 32K效果如何待定
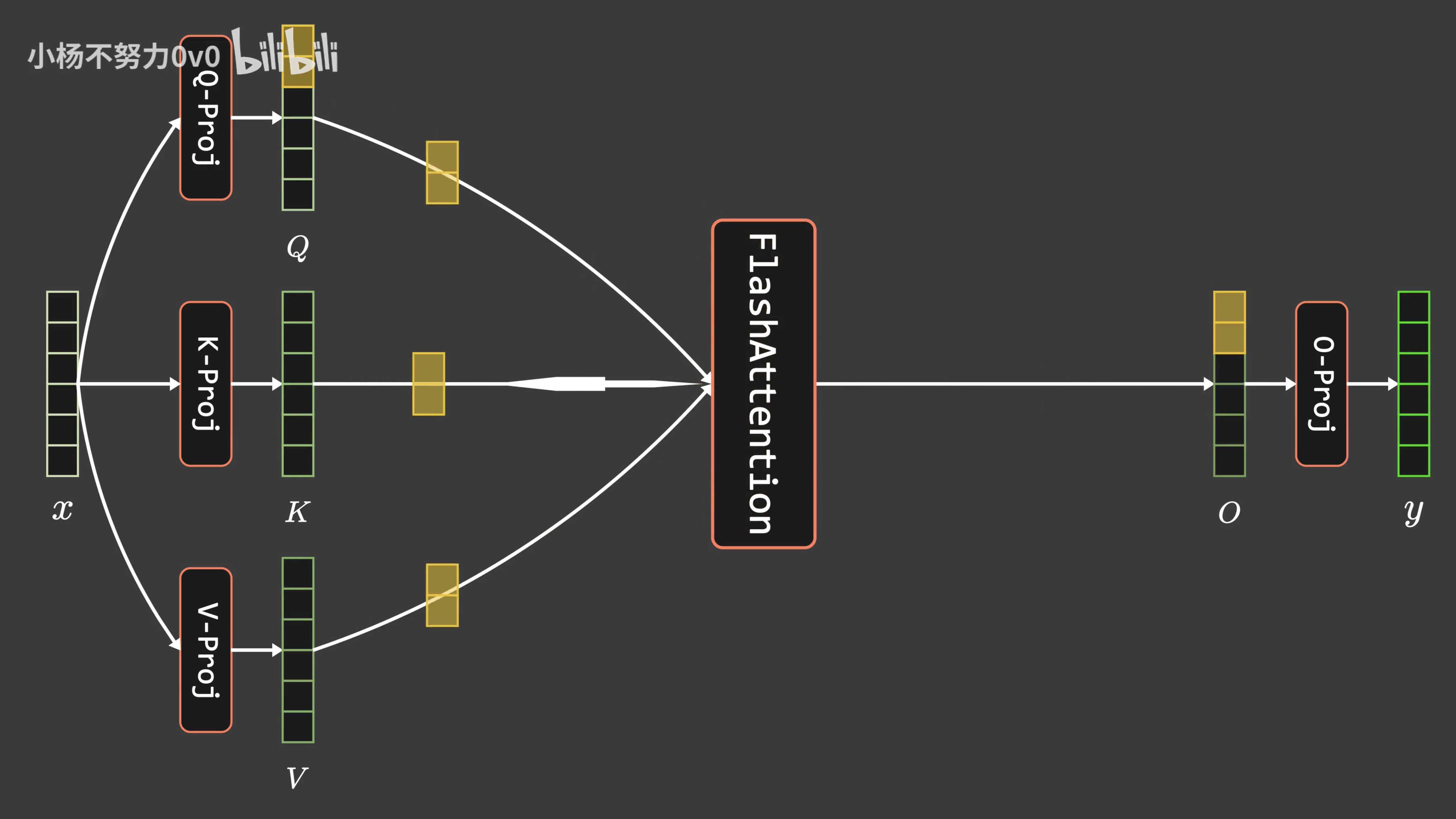
- 第二个因素是,本文最初是作为ChatGLM2-6B的部分内容之一和第一代ChatGLM-6B的内容汇总在一块,而ChatGLM2-6B有一个比较突出的特点是其支持32K的上下文,而ChatGLM2之所以能实现32K上下文的关键之一是得益于Flash Attention(某种意义上降低了 attention的计算量,所以在同样的资源下可以算更长长度的attention)
所以为了阐述清楚Flash Attention、Flash Attention2等相关的原理,导致之前那篇文章越写越长,故特把FlashAttention相关的内容独立抽取出来成本文
至于LLaMA2-long和基于LongLoRA技术的LongAlpaca-7B/13B/70B,则分别见:《一文通透位置编码:从标准位置编码、旋转位置编码RoPE到ALiBi、LLaMA 2 Long》的最后部分、《从LongLoRA到LongQLoRA(含源码剖析):超长上下文大模型的高效微调方法》
本文会和本博客内其他大模型相关的文章一样,极其注重可读性
- 比如为了不断提高可读性,本文近期会不断反复修改,细抠标题的层级、措辞,甚至排版、标点符号,如果不通俗易懂,宁愿不写
- 如果你对某一节的某一个内容或某一个公式没看明白,请随时于本文评论下留言,一定及时修订以让君明白(友情提醒,本文假定大家已经熟悉了transformer,如果对transformer还不熟悉的话,建议先阅读此文:Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT,特别是其中的第三部分)
第一部分 Transformer的时空复杂度与标准注意力的问题
FlashAttention是斯坦福联合纽约州立大学在22年6月份提出的一种具有 IO 感知,且兼具快速、内存高效的新型注意力算法「作者团队包括:Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré,其对应论文为:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,这是其GitHub地址」
它要解决一个什么样的问题呢?
- 首先,GPT3、LLaMA、ChatGLM、BLOOM等大语言模型输入输出的最大序列长度只有2048或4096,扩展到更长序列的难度在哪里呢?本质原因是,transformer模型的计算复杂度和空间复杂度都是
的,其中
为序列长度
- 如此,FlashAttention提出了一种加速计算、节省显存和IO感知的精确注意力,可以有效地缓解上述问题
Meta推出的开源大模型LLaMA,阿联酋推出的开源大模型Falcon都使用了Flash Attention来加速计算和节省显存。目前,Flash Attention已经集成到了pytorch2.0中,另外triton、xformer等开源框架也进行了整合实现
1.1 Transformer计算复杂度——Self-Attention层与MLP层
简单理解的话,计算复杂度和序列长度的平方成正比,可以看一个小例子,比如两个相乘的矩阵大小分别为(
) 和(
),矩阵乘法的一种计算方式是使用第一个矩阵的每一行与第二个矩阵的每一列做点乘

因为我们需要拿第一个矩阵的每一行去与第二个矩阵的每一列做点乘,所以总共就需要 次点乘。而每次点乘又需要
次乘法,所以总复杂度就为
精确理解的话,当输入批次大小为 ,序列长度为
时,
层transformer模型的计算量为
,
则代表词向量的维度或者隐藏层的维度(隐藏层维度通常等于词向量维度)
但这个结果是怎么一步一步计算得到的呢?下面,咱们来详细拆解这个计算过程
1.1.1 Self-Attention层的计算复杂度
首先,我们知道,transformer模型由 个相同的层组成,每个层分为两部分:self-attention块和MLP块
而self-attention层的模型参数有两部分,一部分是、
、
的权重矩阵
、
、
和偏置,另一部分是输出权重矩阵
和偏置,最终为:
具体怎么计算得来的呢?
- 第一步是计算
、
、
即
该矩阵乘法的输入和输出形状为
计算量为:
24年4月下旬更新:考虑在我主讲的七月官网的「大模型项目开发线上营」中,一学员对上述推导还有所疑问,故再解释说明下1,类似阿荀所说:“(b,N,d)看做b个(N,d),(b,N,d) × (d,d)看做b个(N,d) × (d,d),(N,d) × (d,d)的计算次数是2Ndd(乘法Ndd、加法再Ndd,当然也有的资料不看加法),b个(N,d) × (d,d)的计算次数就是b2Ndd,也就是
”
的形状是[d,d],Q的形状是[b,N,d],因为除了Q之外,还得再计算K、V,所以最后会再乘以个3,得到:
- 计算
该部分的输入和输出形状为
计算量为:
- 计算在
该部分矩阵乘法的输入和输出形状为
计算量为:- attention后的线性映射,矩阵乘法的输入和输出形状为
计算量为
最终自注意力层的输出结果为
1.1.2 MLP层的计算复杂度
MLP块由2个线性层组成,最终是
怎么计算得来的呢?
一般地,第一个线性层是将维度从
映射到
,第二个线性层再将维度从
- 第一个线性层的权重矩阵
的形状为
,相当于先将维度从
,计算量为
- 第二个线性层的权重矩阵
的形状为
,相当于再将维度从
,计算量为
将上述所有表粗所示的计算量相加,得到每个transformer层的计算量大约为
1.1.3 logits的计算量: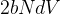
此外,另一个计算量的大头是logits的计算(毕竟词嵌入矩阵的参数量也较多),将隐藏向量映射为词表大小,说白了,词向量维度通常等于隐藏层维度 ,词嵌入矩阵的参数量为
,最后的输出层的权重矩阵通常与词嵌入矩阵是参数共享的「解释一下,如七月杜老师所说,这个是transformer中一个重要的点,参数共享可以减小参数量,词嵌入矩阵是[vocab_size,hidden_size],输出层矩阵是 [hidden_size,vocab_size],是可以共享的」
其矩阵乘法的输入和输出形状为,计算量为
因此,对于一个 层的transformer模型,输入数据形状为
的情况下,一次训练迭代的计算量为上述三个部分的综合,即:
1.2 Transformer的空间复杂度——Self-Attention层与MLP层
中间激活的显存大小为 ,其中
为注意力头数
大模型在训练过程中通常采用混合精度训练,中间激活值一般是float16或者bfloat16数据类型的。在分析中间激活的显存占用时,假设中间激活值是以float16或bfloat16数据格式来保存的,每个元素占了2个bytes。唯一例外的是,dropout操作的mask矩阵,每个元素只占1个bytes。在下面的分析中,单位是bytes,而不是元素个数。
每个transformer层包含了一个self-attention块和MLP块,并分别对应了一个layer normalization连接。
1.2.1 Self-Attention块的中间激活
self-attention块的计算公式如下:
最终,self-attention块的中间激活占用显存大小为:
具体怎么计算得来的呢?
- 对于
,需要保存它们共同的输入
,这就是中间激活。输入
,元素个数为
,占用显存大小为
- 对于
矩阵乘法,需要保存中间激活
,两个张量的形状都是
,占用显存大小合计为
- 对于
函数,需要保存函数的输入
,这里的
表示注意力头数
其中的形状为:
,元素个数为
,占用显存大小为
如我司论文100课的一学员“饭饭”所说:每一个token相对于其他token的注意力权重,所以每个token都有N个权重,那么所有token就是N²。 再,每个注意力头,都有这样一套注意力矩阵,所以是N²a,再乘以batch和fp16- 计算完
- 计算在
,需要保存
,大小为
,二者占用显存大小合计为
- 计算输出映射以及一个dropout操作。输入映射需要保存其输入,大小为
;dropout需要保存mask矩阵,大小为
,二者占用显存大小合计为
因此,将上述中间激活相加得到,self-attention块的中间激活占用显存大小为
1.2.2 MLP块的中间激活
MLP块的计算公式如下:,最终对于MLP块,需要保存的中间激活值为
具体怎么计算得来的呢?
- 第一个线性层需要保存其输入,占用显存大小为
- 激活函数需要保存其输入,占用显存大小为
- 第二个线性层需要保存其输入,占用显存大小为
- 最后有一个dropout操作,需要保存mask矩阵,占用显存大小为
1.2.3 两个layer norm需要保存的中间激活
另外,self-attention块和MLP块分别对应了一个layer normalization。每个layer norm需要保存其输入,大小为,2个layer norm需要保存的中间激活为
综上,每个transformer层需要保存的中间激活占用显存大小为
对于
层transformer模型,还有embedding层、最后的输出层。embedding层不需要中间激活。总的而言,当隐藏维度
比较大,层数
因此,对于
「更多分析见此文《分析transformer模型的参数量、计算量、中间激活、KV cache》」
通过上面两小节的内容,可以看到,transformer模型的计算量和储存复杂度随着序列长度 呈二次方增长。这限制了大语言模型的最大序列长度
的大小
其次,GPT4将最大序列长度 扩大到了32K,Claude更是将最大序列长度
扩大到了100K,这些工作一定采用了一些优化方法来降低原生transformer的复杂度,那具体怎么优化呢?
我们知道,每个transformer层分为两部分:self-attention块和MLP块,但上面计算量中的 项和中间激活中的
项都是self-attention块产生的,与MLP块无关
1.3 标准注意力Standard Attention的两个问题:显存占用多、HBM读写次数多
- 回顾一下,transformer中注意力机制的计算过程为 (再次提醒,如果对transformer相关细节有所遗忘,建议先看此:Transformer通俗笔记,如果忘了什么是softmax,则回顾下此文:如何通俗理解Word2Vec):
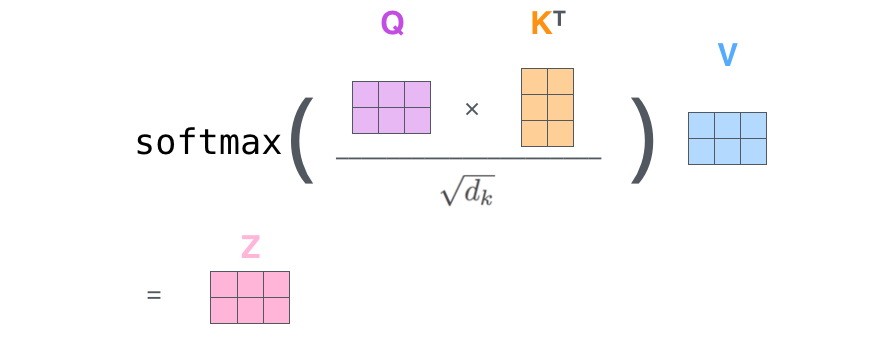
其中,,其中
- 上面的式子可以拆解为以下三步
在标准注意力实现中,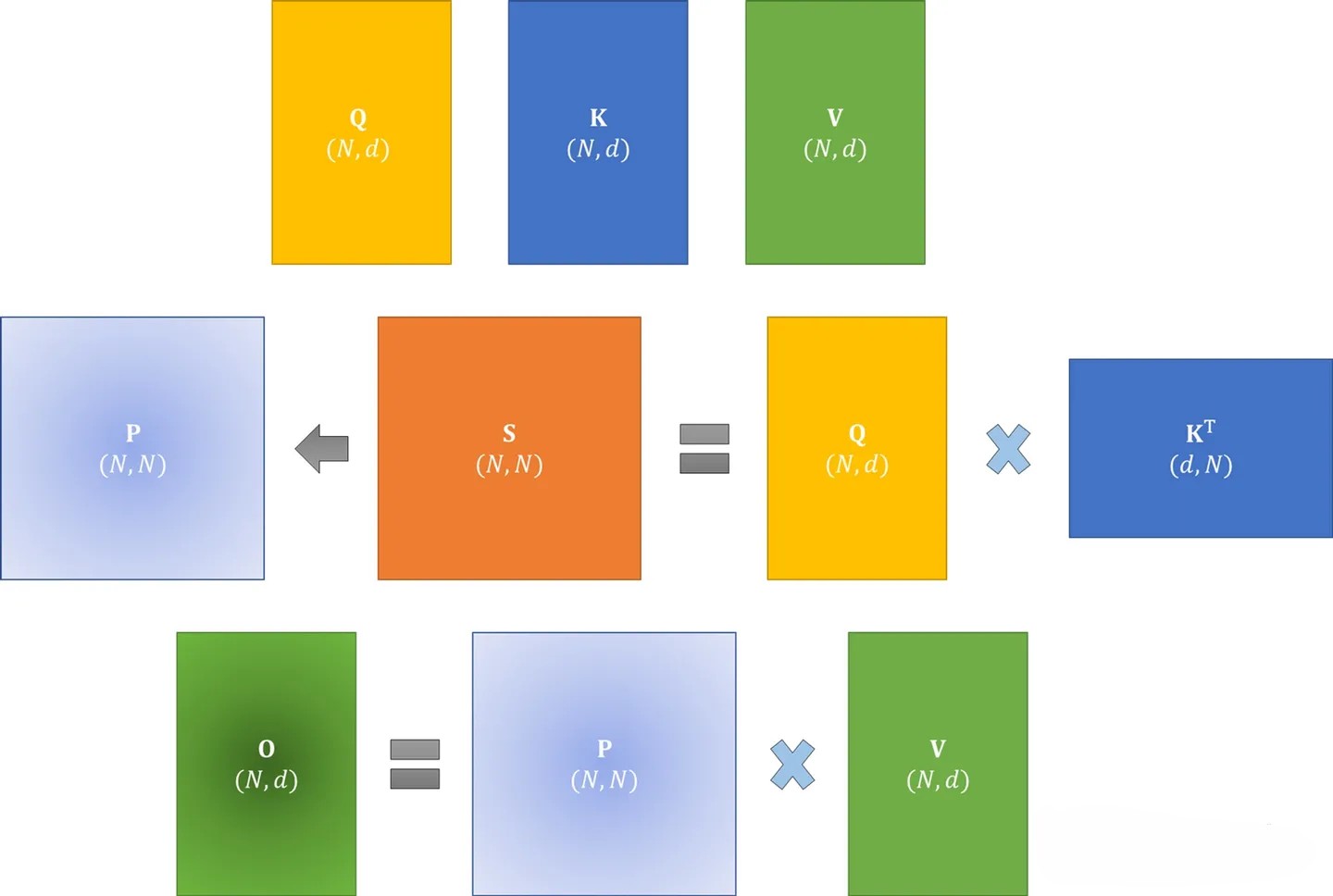
都要写回到HBM中(下文很快会解释这个HBM),占用了
的内存,通常
例如,对于GPT2,,
;对于GPT3,
,
总之,注意力矩阵 需要的内存
所需要的内存
-
下图展示了标准注意力的实现过程

其中,一共包含八次HBM的矩阵读写操作。这八次读写操作分别为:
第一行对的读 共两次,对
的写一次,读写操作总共三次
第二行对写一次,读写操作总共两次
第三行对的读 共两次,对
的写一次,读写操作总共三次
补充一下背景知识
- 尽管已经有许多近似注意力的方法尝试减少attention的计算和内存要求。例如,稀疏近似和低秩近似的方法,将计算复杂度降低到了序列长度的线性或亚线性
- 但这些近似注意力方法方法并没有得到广泛应用。因为这些方法过于关注FLOPS(浮点数计算次数)的减少,而忽略了IO读写的内存访问开销,导致这并没有效减少运行时间(wall-clock time)
- 总之,在现代GPU中,计算速度已经远超过了显存访问速度,transformer中的大部分计算操作的瓶颈是显存访问。对于显存受限的操作,IO感知是非常重要的,因为显存读写占用了大部分的运行时间
GPU的内存由多个不同大小和不同读写速度的内存组成。内存越小,读写速度越快。对于A100-40GB来说,内存分级图如下所示
- SRAM内存分布在108个流式多处理器上,每个处理器的大小为192K,合计为
相当于计算块,但内存小- 高带宽内存HBM(High Bandwidth Memory),也就是我们常说的显存,大小为40GB。SRAM的读写速度为19TB/s,而HBM的读写速度只有1.5TB/s,不到SRAM的1/10
相当于计算慢,但内存大
总之,transformer的核心组件self-attention块的计算复杂度和空间复杂度是序列长度 的二次方
且对于self-attention块,除了两个大矩阵乘法是计算受限的(、
),其他都是内存受限的逐点运算( 例如对
的mask操作、
的softmax操作、对
的dropout操作,这些逐点操作的性能是受限于内存带宽的,会减慢运行时间)
即标准注意力实现存在两个问题:
- 显存占用多,过程中由于实例化了完整的注意力矩阵
,导致了
- HBM读写次数多,减慢了运行时间(wall-clock time)
接下来下文的Memory-efficient Attention、Flash Attention,便是要分别解决上述这两个问题
1.4 Memory-efficient Attention:把显存复杂度从平方降低到线性,但HBM访问次数仍是平方
在注意力计算过程中,节省显存的主要挑战是softmax与的列是耦合的,其方法是单独计算softmax的归一化因子,来实现解耦
- 为了简化分析,忽略计算softmax时“减去最大值”的步骤
记列为
,
列为
,有
定义softmax的归一化因子为: - 记
为
的第
为:
- 在计算得到归一化因子
后,就可以通过反复累加
来得到
如此,通过节省显存(memory-efficient)的注意力机制,改变了计算顺序,相比于Standard Attention,节省显存的注意力机制将显存复杂度从 降低到了
这种方法在《Online normalizer calculation for softmax》和《Self-attention Does Not Need Memory》中已经使用过,称其为“lazy softmax”,这种方法避免了实例化完整的注意力矩阵
,从而达到了节省显存的目的。然而HBM访问次数仍然是
的,因此运行时间并没有减少
第二部分 Flash Attention:通过kernel融合降低HBM读写次数,避免频繁地从HBM中读写数据
如上文说过的
- 在标准注意力实现中,注意力的性能主要受限于内存带宽,是内存受限的,频繁地从HBM中读写
的矩阵是影响性能的主要瓶颈
- 稀疏近似和低秩近似等近似注意力方法虽然减少了计算量FLOPs,但对于内存受限的操作,运行时间的瓶颈是从HBM中读写数据的耗时,减少计算量并不能有效地减少运行时间(wall-clock time)
- 针对内存受限的标准注意力,Flash Attention是IO感知的,目标是避免频繁地从HBM中读写数据
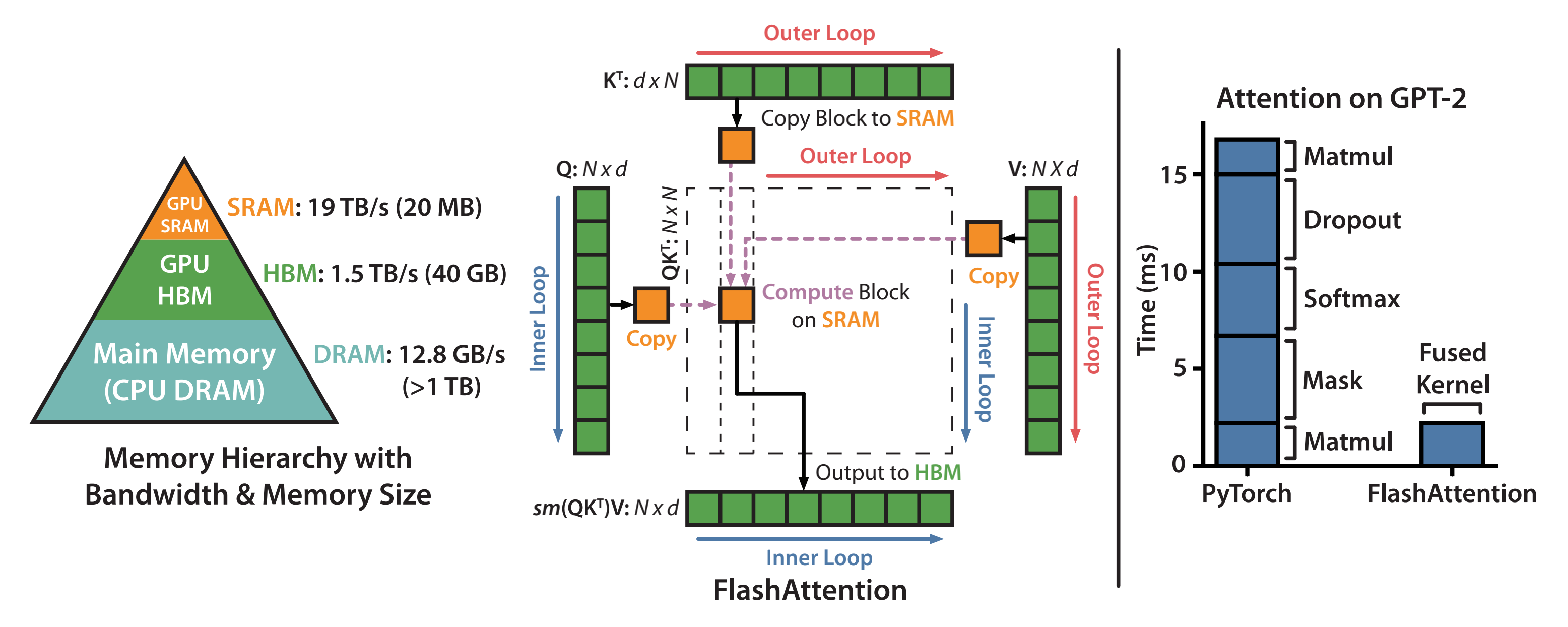
所以,减少对HBM的读写次数,有效利用更高速的SRAM来进行计算是非常重要的,而对于性能受限于内存带宽的操作,进行加速的常用方式就是kernel融合,该操作的典型方式分为三步:
- 每个kernel将输入数据从低速的HBM中加载到高速的SRAM中
- 在SRAM中,进行计算
- 计算完毕后,将计算结果从SRAM中写入到HBM中
如此,便可避免反复执行“从HBM中读取输入数据,SRAM执行计算,最后将计算结果写入到HBM中”,将多个操作融合成一个操作,减少读写HBM的次数
可能有的同学对上面的阐述不甚理解,其实原理很简单,即如下两句话
- 如果把SRAM写回HBM只是为了(重新)加载它来计算softmax
- 那么是可以将其保存在SRAM中,执行所有中间步骤,然后将最终结果写回HBM
前者如下图左侧所示,后者如下图右侧所示(下图图源)
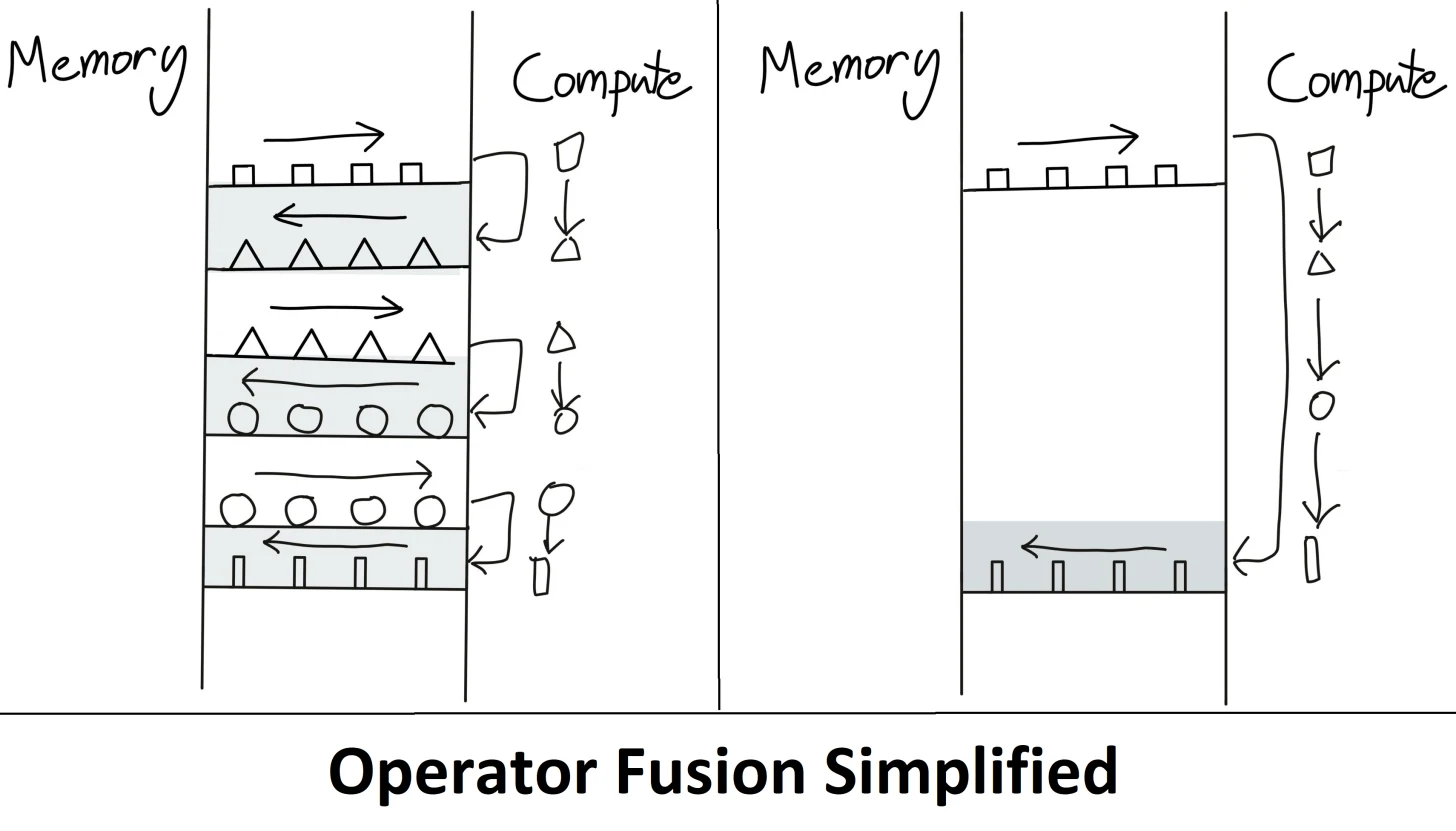
2.1 分块计算注意力tiling——kernel融合需满足SRAM的内存大小,但无奈SRAM内存太小
虽然通过kernel融合的方式,将多个操作融合为一个操作,利用高速的SRAM进行计算,可以减少读写HBM的次数,从而有效减少内存受限操作的运行时间。但有个问题是
- SRAM的内存大小有限,不可能一次性计算完整的注意力,因此必须进行分块计算,使得分块计算需要的内存不超过SRAM的大小
相当于,内存受限 --> 减少HBM读写次数 --> kernel融合 --> 满足SRAM的内存大小 --> 分块计算,因此分块大小block_size不能太大,否则会导致OOM
总之,tiling分块计算使得我们可以用一个CUDA kernel来执行注意力的所有操作。从HBM中加载输入数据,在SRAM中执行所有的计算操作(矩阵乘法、mask、softmax、dropout、矩阵乘法),再将计算结果写回到HBM中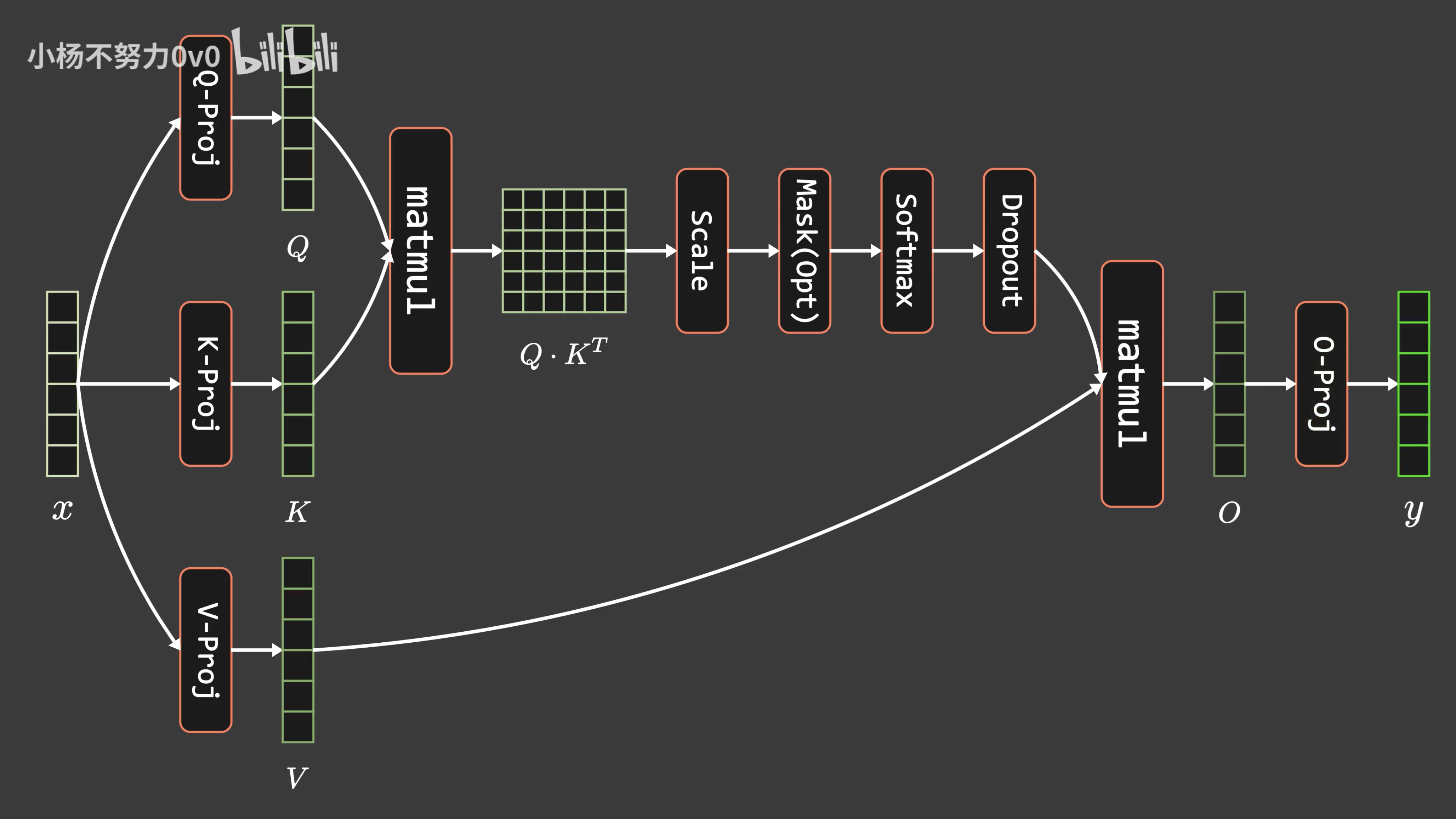
- 而分块计算的难点是什么呢?
注意力机制的计算过程是“矩阵乘法 --> scale --> mask --> softmax --> dropout --> 矩阵乘法”,矩阵乘法和逐点操作(scale,mask,dropout)的分块计算是容易实现的,难点在于softmax的分块计算。由于计算softmax的归一化因子(分母)时,需要获取到完整的输入数据,进行分块计算的难度比较大
怎么理解上文中的这句“由于计算softmax的归一化因子(分母)时,需要获取到完整的输入数据,进行分块计算的难度比较大”呢?
先回顾一下softmax的计算公式
- 考虑到向量
,原生softmax的计算过程如下:
- 在实际硬件中,浮点数表示的范围是有限的
对于float32和bfloat16来说,当 时,
就会变得很大甚至变成inf,发生数据上溢的问题
故为了避免发生数值溢出的问题,保证数值稳定性,计算时通常会“减去最大值”,称为“safe softmax”
而便被定义为
从而,现在所有的深度学习框架中都采用了“safe softmax”这种计算方式- 在训练语言模型时,通常会采用交叉熵损失函数。交叉熵损失函数等价于先执行log_softmax函数,再计算负对数似然函数
且在计算log_softmax时,同样会执行“减去最大值”,这不仅可以避免数值溢出,提高数值稳定性,还可以加快计算速度
总之,要计算输入序列中的特定第
表示),但是SRAM的容量是有限的,
会爆炸得很快
那到底怎么解决分块计算的难点——softmax的分块计算呢?考虑到softmax与 的列是耦合的,故可以通过引入了两个额外的统计量
来进行解耦(前者类似最大分数,后者类似exp分数总和),实现了分块计算
为何要弄这两个变量呢?
- 首先,模型训练会影响kernel融合的效果,原因在于在标准注意力实现中,为了后向传递计算
)写回到HBM中,这会产生额外的HBM读写次数,减慢运行时间。因此,Flash Attention要想办法避免为后向传递保存很大的中间结果矩阵
- 进一步,Flash Attention的办法是重计算,即不保存
,后向传递时在高速的SRAM上快速地重新计算Attention,通过分块的方式重新计算注意力矩阵
总的来说,Flash Attention通过调整注意力的计算顺序,引入两个额外的统计量进行分块计算,避免了实例化完整的
此外,对于内存受限的标准注意力,Flash Attention还通过kernel融合和分块计算,大量减少了HBM访问次数,尽管由于后向传递中的重计算增加了额外的计算量FLOPs,但总的来讲,最终还是减少了不少的运行时间,计算速度更快
2.1.1 通过23个公式全面理解分块计算注意力tiling
下面从头开始,全面梳理下(以下23个公式的阐述修改自此)
-
-
-
-
考虑到向量
其中
分子对向量
分母则是对向量
是一个新的向量,其中每一项相当于在「公式4的标准softmax的分子即
」的每一项的基础上,在其指数项
中减去了一个
是「变体softmax分母」中的求和项,为了方便后续的描述,下文将本公式7中的求和项称为“EXP求和项”
考虑一个大小为2d的向量,将其“一切为二”进行分块:
其中
换言之,子向量是原向量
是原向量
假设在分块计算中先处理
那就先使用公式5至公式8对子向量”,计算过程如下公式9-12所示
很明显,至此得到的并不能算是子向量
一者,公式10中的指数项减去的最大值应该是整个向量
二者,公式12中分母的EXP求和项应该是关于整个向量
正因上述计算得到的不是最终结果,所以将其称为“局部的”
接下来将介绍通过保存额外的一些变量值,在处理完
首先,在处理完子向量和
,相比于保存整个子向量
其次,还需要保存两个全局标量:和
表示全局EXP求和项。因为目前只处理完了
接着采用类似处理-
-
-
-
同样道理,此时公式16得到的softmax也是局部而非全局的
但在处理完)和
),如下公式17和18所示:
-
公式17的含义很简单:更新后的全局最大值就是「之前的最大值」中更大的那一个
-
公式18是更新的全局EXP求和项的方法
且慢,这是怎么来的呢?不应该是?
以为例, 我们说
把
稍微展开可得:
-
可知导致是“局部”而非“全局”的原因是它减去的max值是“局部的”,所以只需要将这个max值替换为全局的即可
为此可以将 - 即
此时的
这个公式说明,当需要把某个,其中
表示当前
表示当前最大值
回到公式18,可知其首先用了这种全局更新方法分别将
基于上述更新
根据公式16即,可知
由于当前的分子和分母都是局部的,所以都需要更新至全局
先看分子部分,
,可将其做下更新
-
即
当对比
再来看分母部分即可,这可以由如下公式办到:
-
其中的由公式18计算得到
好,问题来了
问题1 网上很多朋友也对此表达过疑惑,即为何公式22这里的分母是
答:原因很简单,考虑一下为什么我们使用softmax:它为向量的每一个元素分配一个介于0和1之间的概率值,使得这些概率的总和为1
当我们说"全局",是希望为整个数据集的每一个元素分配概率,而不仅仅是为数据集的一个子集分配
所以当你有一个数据流,分成了两部分:
接下来 问题 可能又来了,可能马上有同学问
问题2 公式20中的不说是全局的么?
答:公式20中的只是
问题3 公式20和公式19都只用到了
公式19:
这里的最大值是,即
公式20:
这里的最大值是
所以,他们主要的区别是它们使用的参考最大值不同:公式19使用的是局部最大值,而公式20使用的是更全局的最大值。这种变换是为了数值稳定性,确保当我们计算e的指数时不会遇到数值上溢的问题
最后,结合公式21和公式22,的更新可由如下实现:
-
仔细看公式23,我们在更新,来自公式16
全局最大值
全局EXP求和项
同理,可以将上面前三项中的
这就是Flash Attention中对
上述其实是一个增量计算的过程
- 我们首先计算一个分块的局部softmax值,然后存储起来
- 当处理完下一个分块时,可以根据此时的新的全局最大值和全局EXP求和项来更新旧的softmax值,接着再处理下一个分块,然后再更新
- 当处理完所有分块后,此时的所有分块的softmax值都是“全局的”
2.1.2 对分块计算注意力tiling的简单总结
可能你的CPU已经干烧了,为缓解烧脑,咱们最后再通过一个简单的例子把上述过程总结一下
对于两个向量 ,解耦拼接向量
的softmax计算:
通过保持两个额外的统计量 ,可以实现softmax的分块计算。需要注意的是,可以利用GPU多线程同时并行计算多个block的softmax。为了充分利用硬件性能,多个block的计算不是串行(sequential)的, 而是并行的
我貌似看到了你脸上隐约有点焦虑的情绪,没事 不急 July懂,单纯的公式毕竟相对晦涩,下面通过一个例子来形象的说明到底是如何分块计算softmax的
对向量 [1,2,3,4] 计算softmax,分成两块 [1,2] 和 [3,4] 进行计算
计算block 1:
计算block 2:
合并得到完整的softmax结果:
2.2 Flash Attention算法的前向计算算法(可能是全网最通俗易懂的解读)
2.2.1 在忽略mask和dropout的情况下Flash Attention算法的前向计算过程分析
在忽略mask和dropout的情况下,简化分析,Flash Attention算法的前向计算过程如下所示

从上图可以看到,该算法在的维度上做外循环,在
的维度上做内循环(而在triton的代码实现中,则采用了在
的维度上做外循环,在
的维度上做内循环)
为本着细致起见,还是针对上述16行代码一行一行解释下,为方便大家理解,再引用知乎上marsggbo画的一个流程图,大家可以对照这个流程图增进对相关代码的理解
首先,有基本条件:
其中,的大小为
设置块大小
,
计算行/列块大小。为什么ceil() ?因为查询、键和值向量是
以GPT2和A100为例:
A100的SRAM大小为
GPT2中,
,对应的
,中间结果
故
用全0初始化输出矩阵
按照步骤1中的块大小,将
具体来说,则是块,每一分块的大小为
沿着行方向分为
块,每一分块的大小为
而
将分割成块
其中,
至于向量
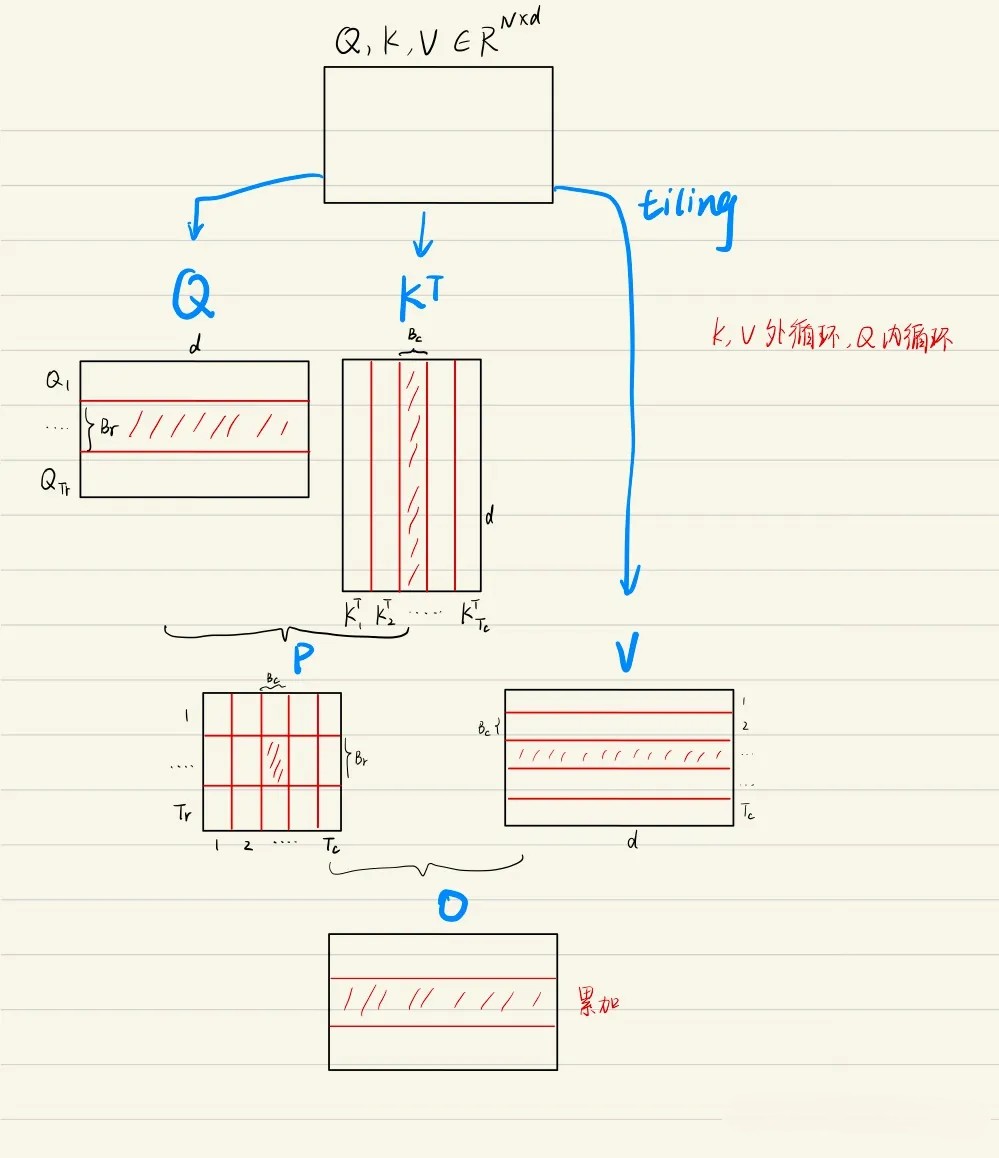
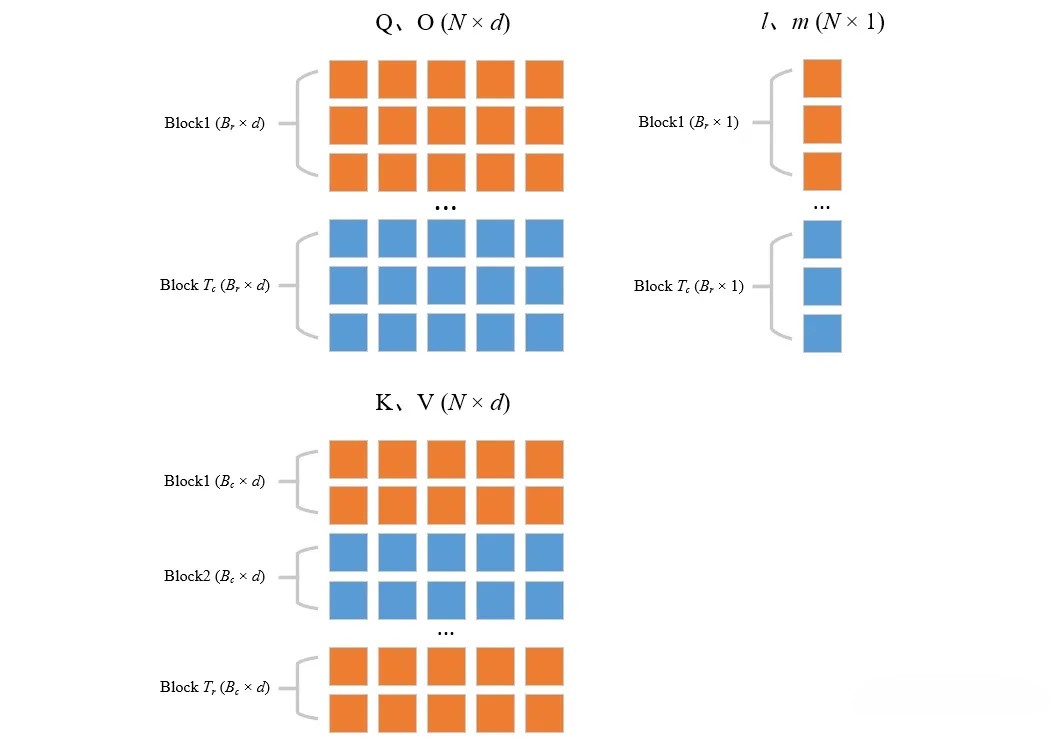
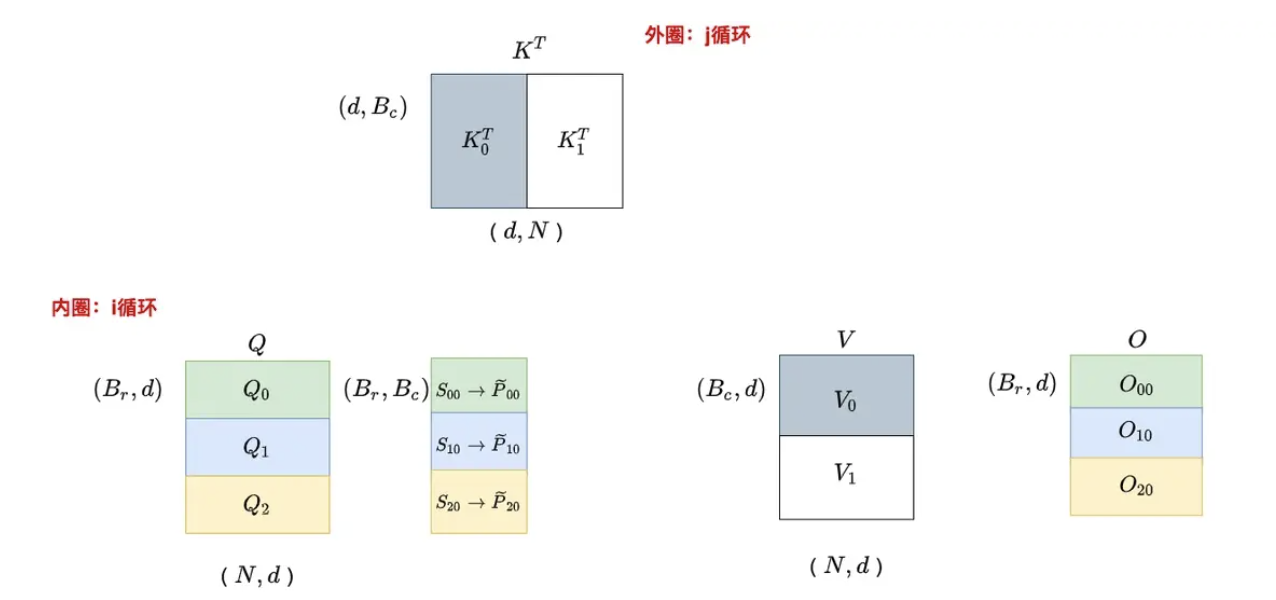
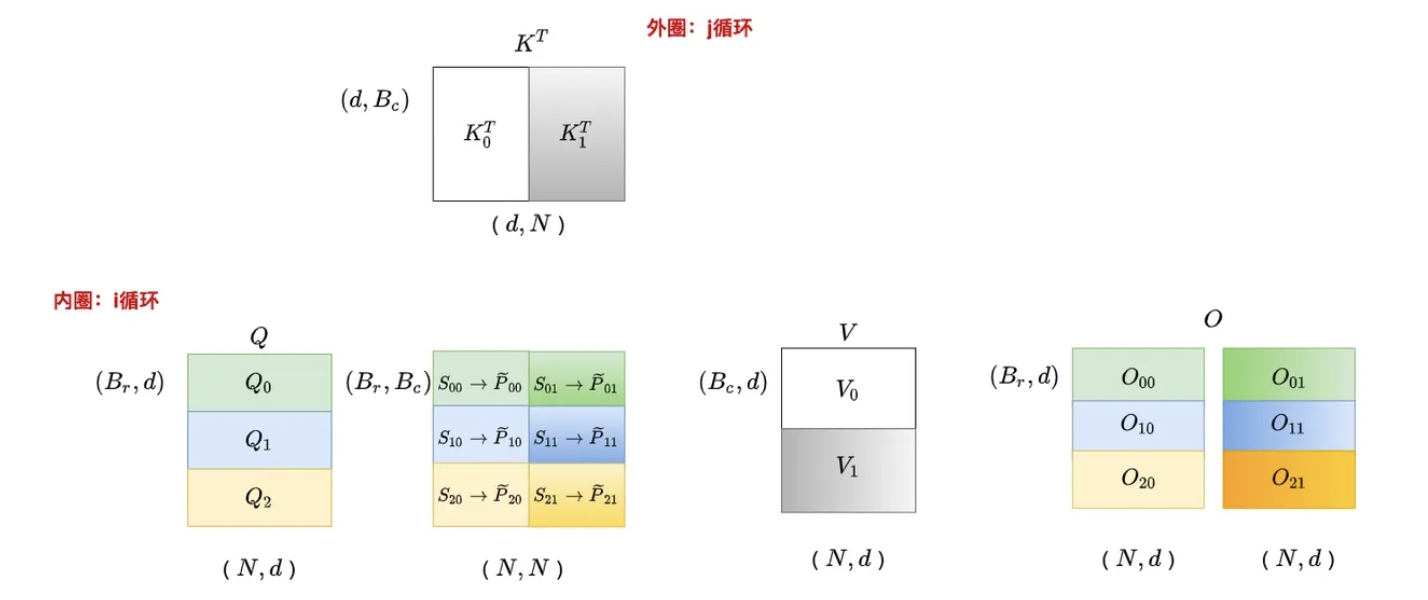
综合上述3、4两个步骤:先后切分Q、K、V、O、l、m(别看上面这么多内容,其实就干这点事),可以得到各个分块之间的关系如下
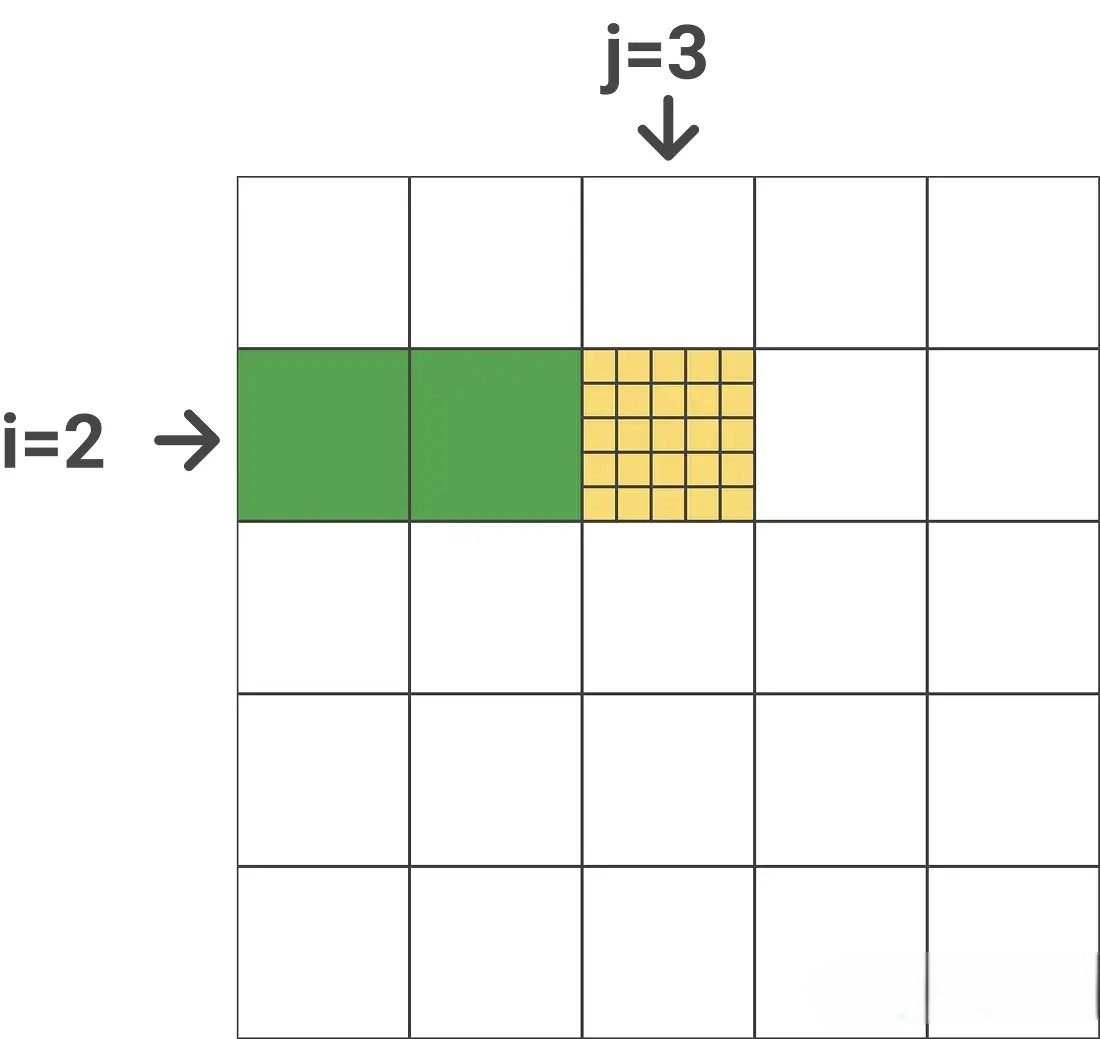
切分完之后,接下来开启两大循环,先外(列)循环 再内(行)循环for 1 ≤ j ≤ Tc do
开始跨列循环(即外部循环,由次。考虑到这块的逻辑比较绕,特上一图、一表,以让你一目了然
为更加一目了然,且如果不考虑缩放、softmax等因素,那么这一系列的计算过程可以简化为(下述表格中带下划线的:q4k2 v2,便对应上图中虚线框里的那个块,够直白了吧,哈哈)
q1k1 v1 q1k2 v2 q1k3 v3 q1k4 v4 q1k5 v5 q1k6 v6 q1k7 v7 q1k8 v8 q2k1 v1 q2k2 v2 q2k3 v3 q2k4 v4 q2k5 v5 q2k6 v6 q2k7 v7 q2k8 v8 q3k1 v1 q3k2 v2 q3k3 v3 q3k4 v4 q3k5 v5 q36 v6 q3k7 v7 q3k8 v8 q4k1 v1 q4k2 v2
q4k3 v3 q4k4 v4 q4k5 v5 q46 v6 q4k7 v7 q4k8 v8 q5k1 v1 q5k2 v2 q5k3 v3 q5k4 v4 q5k5 v5 q56 v6 q5k7 v7 q5k8 v8 q6k1 v1 q6k2 v2 q6k3 v3 q6k4 v4 q6k5 v5 q66 v6 q6k7 v7 q6k8 v8 q7k1 v1 q7k2 v2 q7k3 v3 q7k4 v4 q7k5 v5 q76 v6 q7k7 v7 q7k8 v8 q8k1 v1 q8k2 v2 q8k3 v3 q8k4 v4 q8k5 v5 q86 v6 q8k7 v7 q8k8 v8 Load Kj , Vj from 慢速HBM to on-chip 快速SRAM.
将和
块从HBM加载到SRAM(它们的大小为
)。在这个时间点上我们仍然有50%的SRAM未被占用(专用于
for 1 ≤ i ≤ Tr do
开始跨行内部循环(从上一行到下一行),即跨查询向量,一共循环次,可只在遍历
Load Qi , Oi, ℓi, mi from HBM to on-chip SRAM.
将(
)和
(
(
)和
(
这里需要保证
On chip, compute
,即为
这一步计算
)和
)之间的点积,得到分块的Attention Score
,
,
)
当,遍历
当,遍历
On chip, compute
,
,
使用上一步计算的分数计算
、
和
对分块的Attention Score,计算它每一行中的最大值
基于
,计算指数项(归一化-取行最大值并从行分数中减去它,然后EXP):
然后再基于
,计算EXP求和项(矩阵
的逐行和):
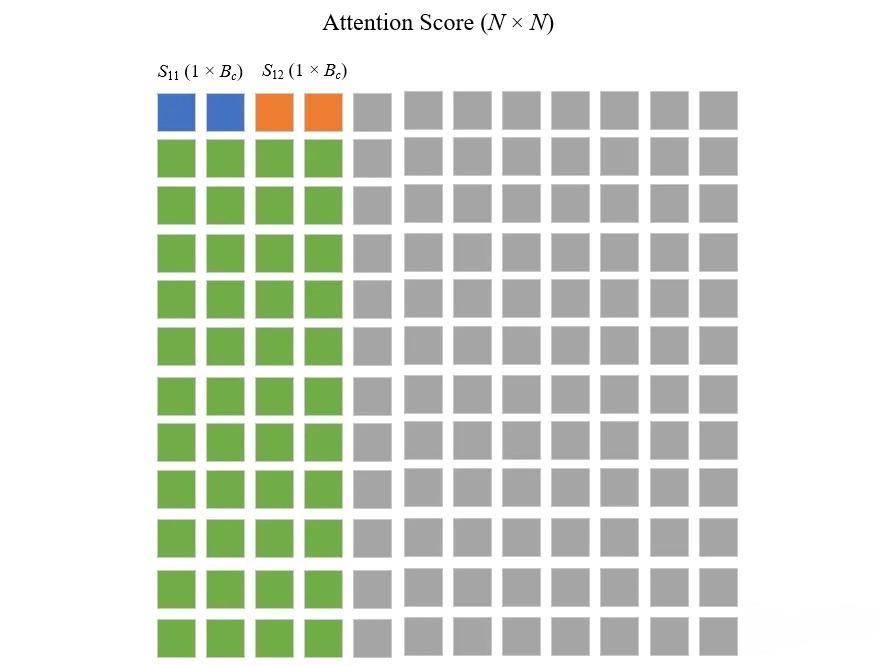
On chip, compute
、
这一步是计算和
,举个例子,如下图所说:
包含之前所有块的逐行最大值(j=1 & j=2,用绿色表示),
和上文利用公式17即和公式18即
分别更新
Write
为了更好地理解这一行的公式,首先得明白多行一起计算的目的是Batch计算
例如在上上图中,每一个小分块所以为了方便理解,可以想象为
的分块
基于上述的简化方法,接下来看整个softmax的更新过程。首先,用
来表示每一行的Attention Score,用
表示每一行的
因为现在不考虑Batch计算了,所以每一次处理的Attention Score都是一个向量,如上图中的
,我们首先用公式5至公式8计算它的局部
得到,此时
接着处理
,同理首先用公式5至公式8计算它的局部
对
(记为公式24)
其中
等价于公式6即
的结果
当处理到
时,继续套用公式24来更新即可:
(记为公式25)
下面再进一步,直接尝试来更新输出
,而不仅仅是
。方法其实很简单,只要在每次动态更新完
(记为公式26)
其中
对应的是
拿着公式26与上面的伪代码进行对比,可知伪代码中的公式仅仅是公式26的矩阵版本。到此,可以看到用公式26即可实现分块的Self-Attention计算
Write
更新end for
end for
Return O.


2.2.2 kernel融合中的mask和dropout操作细节
为了简化分析,上文介绍注意力时忽略了mask和dropout操作,下面补充介绍下Flash Attention前向传递中的这两个操作细节
给定输入,计算得到注意力输出
其中, 是softmax的缩放因子,典型的比如
。MASK操作将输入中的某些元素置为 −∞ ,计算softmax后就变成了0,其他元素保持不变
- causal-lm结构和prefix-lm结构的主要差别就是MASK矩阵不同
逐点作用在
的概率将该元素置为0,以
的概率将元素置为
第三部分 Flash Attention2:比Flash Attention快2倍
2023年7月,Tri Dao通过此篇论文《FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning》提出了Flash Attention2(这是该篇论文所对应的审稿意见),其在第一个版本的基础上做了一系列改进
那第一个版本存在什么问题或不足呢?Flash Attention仍然不如其他基本操作(比如矩阵乘法)高效
- 虽然Flash Attention已经比标准的注意力实现快2-4倍,但前向传播仅达到设备理论最大FLOPs/s的30-50%,而反向传播更具挑战性,仅达到A100 GPU最大吞吐量的25-35%
- 相比之下,优化的矩阵乘法可以达到理论最大设备吞吐量的80-90%。 通过仔细的分析,观察到Flash Attention在GPU上不同线程块和线程束之间的工作划分仍然不够优化,导致低占用率或不必要的共享内存读写
因此,在Flash Attention的基础上,我们提出了Flash Attention2,具有更好的并行性和工作分区
- 调整算法以减少非矩阵乘法操作的浮点运算次数,同时保持输出不变(we tweak the algorithms to reduce the number of non-matmul FLOPs while not changing
the output)
以A100 GPU为例,其FP16/BF16矩阵乘法的最大理论吞吐量为312 TFLOPs/s,而非矩阵乘法的FP32吞吐量仅为19.5 TFLOPs/s。换言之,每个非矩阵乘法的FLOP比矩阵乘法的FLOP贵16倍
因此,减少非矩阵乘法操作的浮点运算次数并尽可能多地执行矩阵乘法操作非常重要
It is thus important to reduce non-matmul FLOPs and spend as much time as possible doing matmul FLOPs - 在序列长度维度上同时并行化前向传播和反向传播,除了批次和头数维度。 这样做可以提高GPU资源的利用率,特别是在序列较长(因此批次大小通常较小)的情况下。
- 即使在注意力计算的一个块内部,我们也将工作分配给不同的线程块以减少通信和共享内存的读写
最终,通过实验证明Flash Attention2相对于Flash Attention具有显著的加速效果,比如在不同设置的基准测试中(有无因果掩码,不同的头维度),Flash Attention2在前向传递中实现了约2×的加速(FlashAttention-2比FlashAttention快2倍,意味着同样的费用之前只能训练8k上下文的模型,而现在可以训练具有16k更长上下文的模型),达到了理论最大吞吐量的73%,且在反向传递中达到了理论最大吞吐量的63%。而当用于端到端训练GPT风格的模型时,每个A100 GPU的训练速度可达到225 TFLOPs/s
3.1 V2相对V1在前向传播层面的改进
3.1.1 Flash Attention的前向传播算法
先回顾一下Flash Attention的前向传播算法
- 为了简单起见,只考虑注意力矩阵 S 的一个行块,形式为:
- 对于矩阵
,其中 𝐵𝑟和 𝐵𝑐是行和列的块大小
我们想要计算这个行块的softmax并且与形式为的值相乘
- 对于矩阵
,标准的softmax会如下计算
- 而在线softmax计算每个块的“局部”softmax,并重新缩放以获得正确的输出
首先是第一个块
其次是第二个块
如下图所示,展示了当key K被分成两个块,值V也被分成两个块时,FlashAttention前向传递的过程
通过对每个块计算注意力并重新缩放输出,最终得到正确的答案,同时避免了中间矩阵S和P的昂贵内存读写(注意,图中省略了softmax中将每个元素减去行最大值的步骤)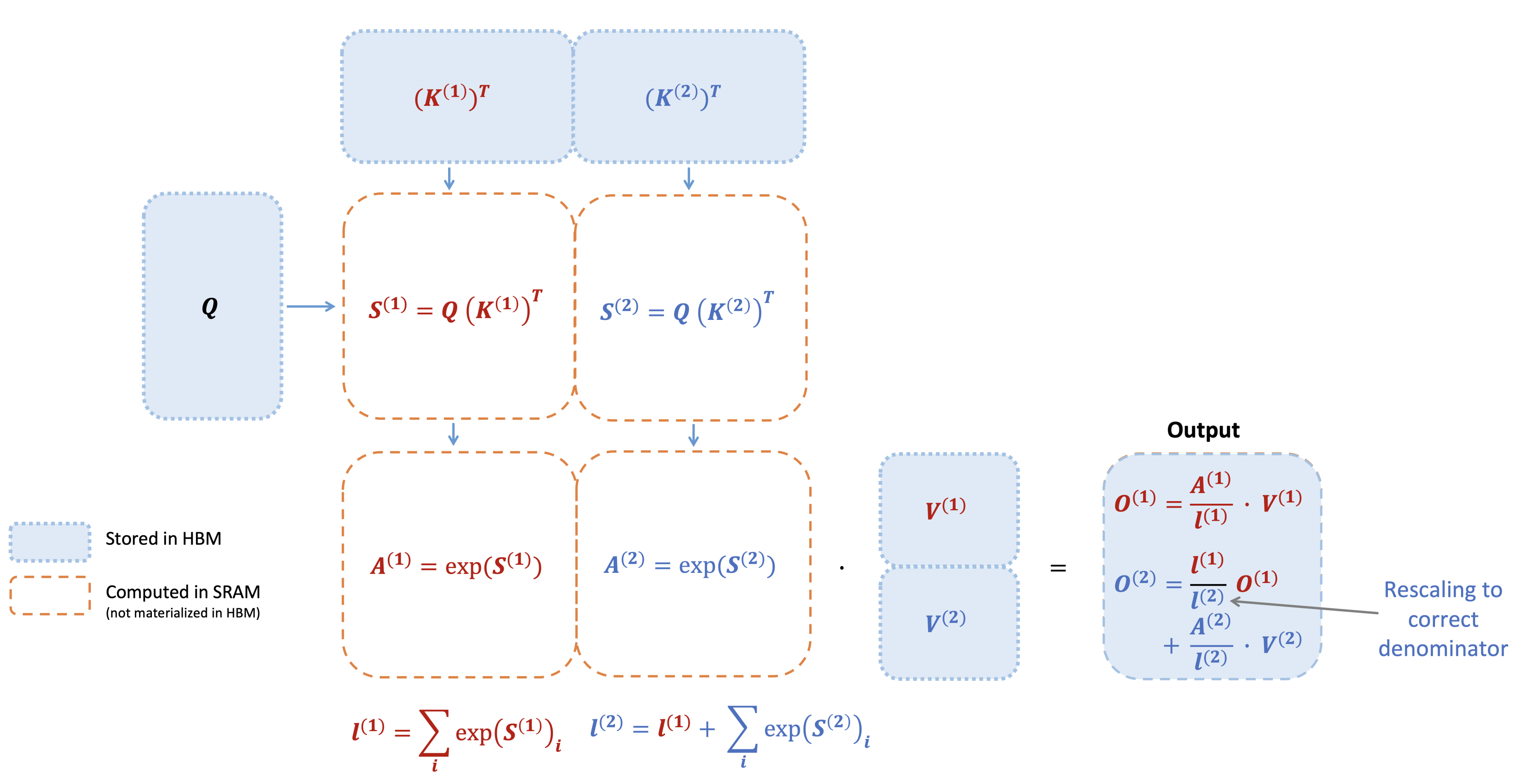
3.1.2 Flash Attention2的前向传播算法
V2相比V1,在前向传播层面进行了两个小的调整,以减少非矩阵乘法的FLOPs:
- 不需要同时重新调整输出更新的两个项
:
相反,我们可以保持一个“未调整”版本的并保留统计数据
:
只有在循环的最后,我们才将最终的按照
进行缩放,以获得正确的输出
- 不需要同时保存最大值
和指数之和
用于反向传播,只需要存储
- 在上一节中只有2个块的简单情况下,在线softmax技巧现在变为:
- 以下便是Flash Attention2完整的前向传递过程
//...
3.2 V2相对V1在反向传播层面的改进
3.2.1 V1的反向传播
在反向传播中,当输入块Q,K,V已经加载到SRAM时,通过重新计算注意力矩阵S和P的值,Flash Attention避免了存储大型中间值。 通过不需要保存大小为通过×通过的大型矩阵S和P,Flash Attention在序列长度上节省了10-20倍的内存(内存需求与序列长度20成线性关系,而不是二次关系)
由于减少了内存读写,反向传播还实现了2-4倍的wall-clock速度提升。尽管从概念上讲,反向传播比正向传播更简单(没有softmax重新缩放),但实现要复杂得多。 这是因为在反向传播中需要保留更多的值在SRAM中执行5个矩阵乘法,而在正向传播中只需要2个矩阵乘法
3.2.2 V2的反向传播
Flash Attention2的反向传播与Flash Attention几乎相同。 但对softmax中的行方向logsumexp 𝐿进行了微小的调整,而不是同时使用行方向的最大值和指数和
以下是FlashAttention2的反向传播完整流程(顺带说下,下图右侧对左侧的翻译结果来自24年5月份上线在七月官网的大模型翻译系统)

3.3 并行化与Work Partitioning Between Warps
3.3.1 并行化下的前向传播与反向传播
FlashAttention的第一个版本在批量大小和头数上进行了并行化。 我们使用1个线程块来处理一个注意力头,总共有「批量大小」× 「头数」个线程块(即batch size · number of heads thread block)。 每个线程块被调度在一个流多处理器(SM)上运行,总共有108个这样的SM
例如,一块A100 GPU。 当这个数字很大(比如 ≥ 80)时,这种调度是高效的,因为我们可以有效地利用GPU上的几乎所有计算资源
在长序列的情况下(通常意味着小批量大小或小头数),为了更好地利用GPU上的多处理器,现在
还在序列长度维度上进行并行化
- 前向传播
可以看到外部循环(序列长度)是粗硬地并行的,并且将它们安排在不需要相互通信的不同线程块上。我们还在批量维度和头数维度上进行并行化,就像FlashAttention一样。 在序列长度上增加并行性有助于提高占用率(使用的GPU资源的比例),当批量大小和头数较小时,这将导致加速
这些交换循环顺序的想法(在原始的FlashAttention论文中,外循环遍历行块,内循环遍历列块,而不是相反的方式),以及在序列长度维度上的并行化,是由Phil Tillet在Triton [Triton: an intermediate language and compiler for tiled neural network computations]实现中首次提出和实现的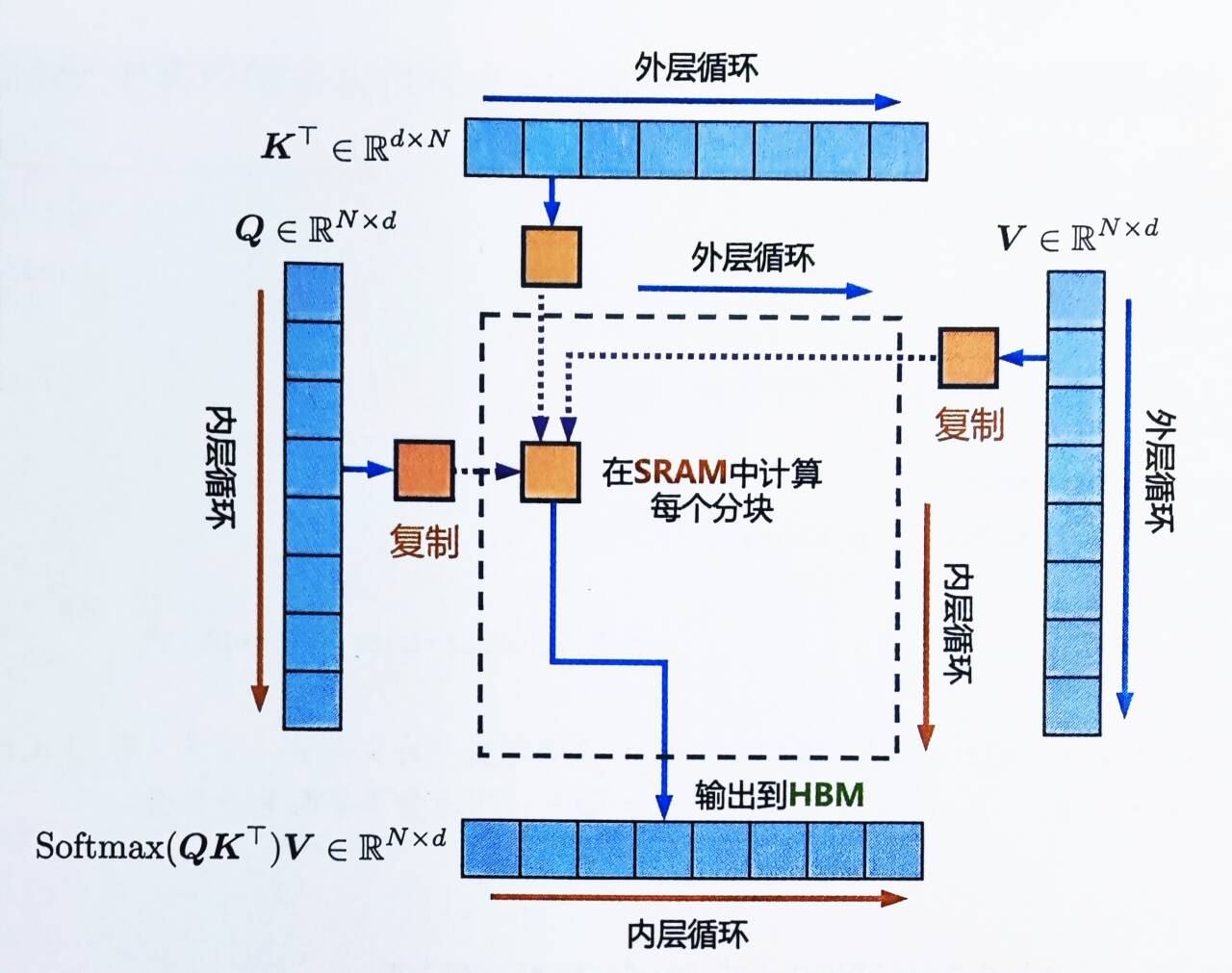
- 反向传播
注意,不同列块之间唯一的共享计算是在上节「Algorithm 2 FlashAttention-2 Backward Pass」中的更新中,我们需要将
并写回HBM
因此,我们也在序列长度维度上进行并行化,并为反向传播的每个列块安排1个线程块。且使用原子加法(atomic adds)来在不同的线程块之间进行通信以更新
最终,如下图所示
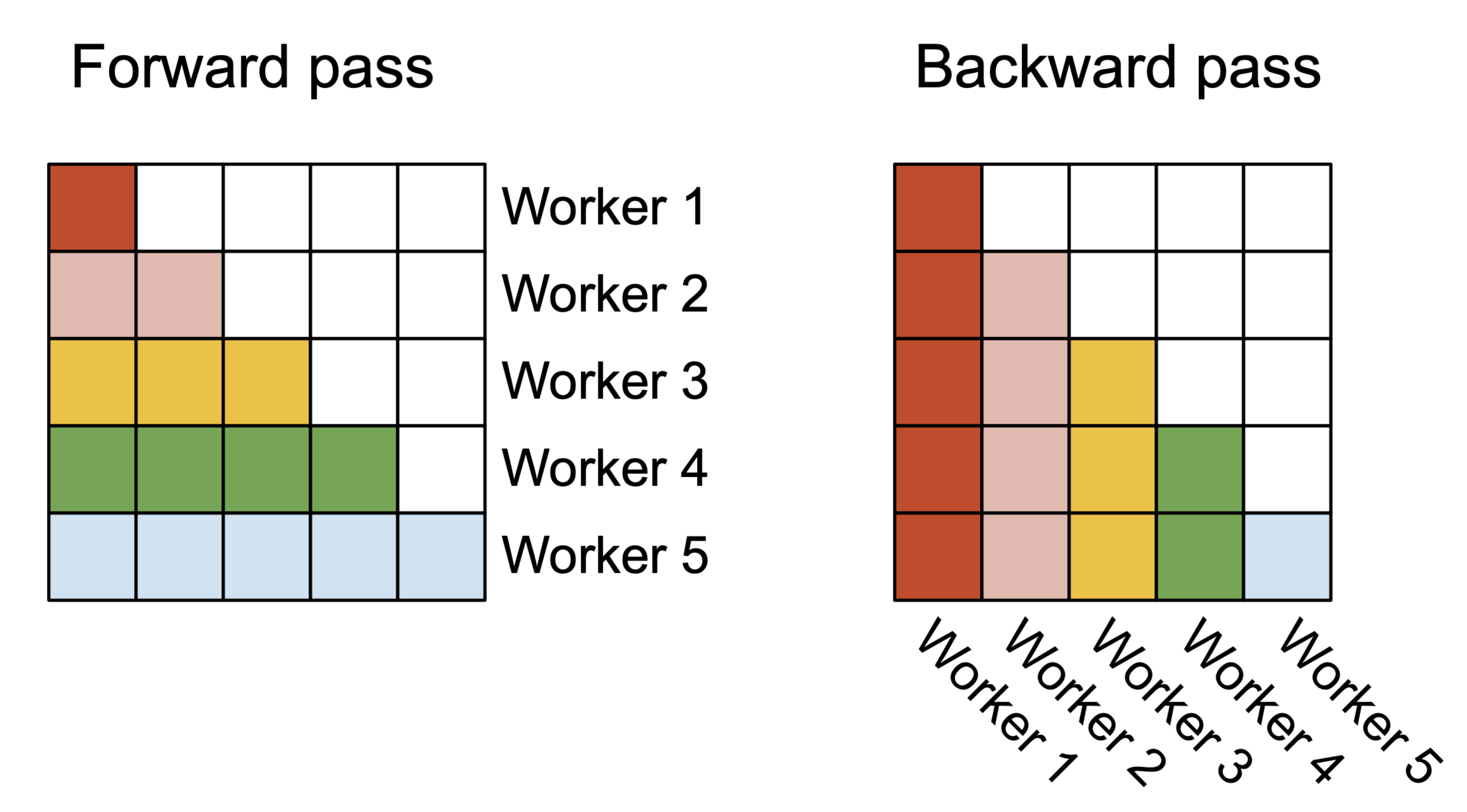
- 在前向传递(左侧)中,我们将工作线程(线程块)并行化,其中每个工作线程负责处理注意力矩阵的“行块”
- 在后向传递(右侧)中,每个工作线程负责处理注意力矩阵的“列块”
3.3.2 Work Partitioning Between Warps
正如上一节所描述的我们如何调度线程块,即使在每个线程块内部,we also have to decide
how to partition the work between different warps
通常在每个线程块中使用4或8个线程束,具体划分如下图所述
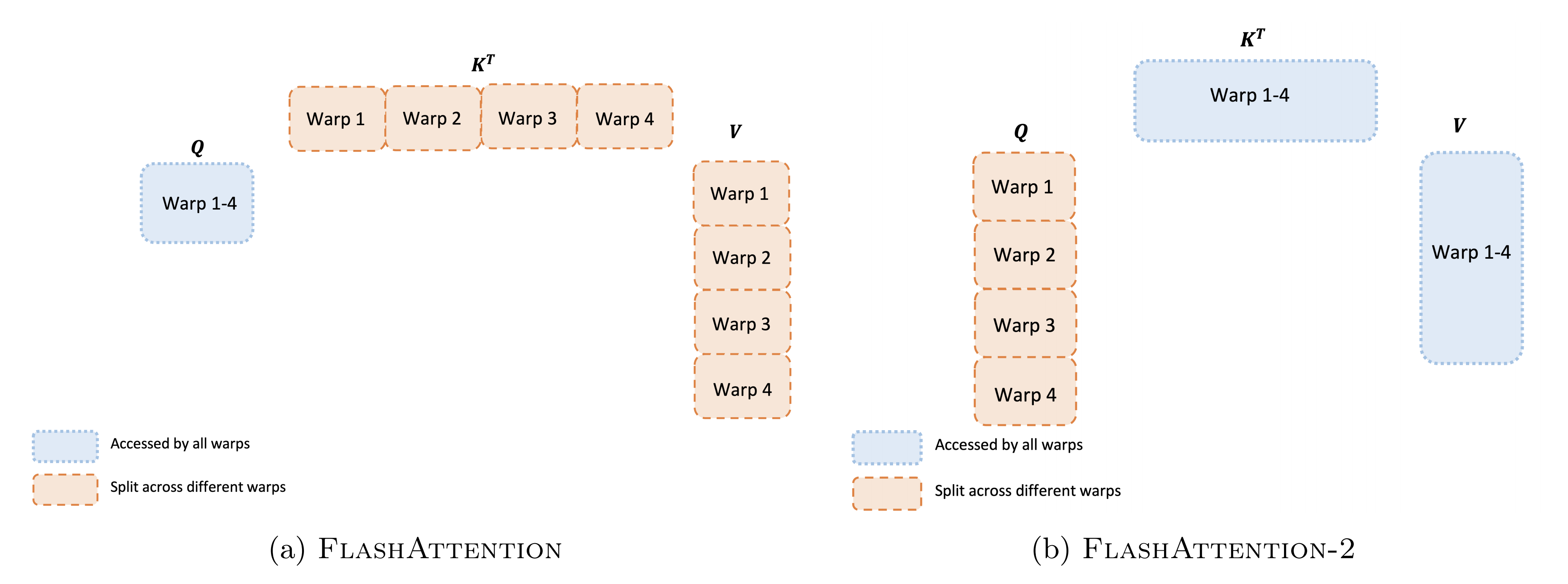
- 前向传播
对于每个块,Flash Attention在4个线程束之间分割K和V,同时保持Q对所有线程束可访问
每个线程束乘以的一个切片,然后需要与V的一个切片相乘并进行通信以累加结果。 这被称为““split-K”方案
然而,这是低效的,因为所有线程束都需要将其中间结果写入共享内存,进行同步,然后累加中间结果。这些共享内存的读/写会减慢Flash Attention中的前向传递
在Flash Attention2中,我们将Q分割成4个线程束,同时保持K和V对所有线程束可访问。在每个warp执行矩阵乘法以获取 - 反向传播
类似于前向传播,我们选择将warp分区以避免“split-K”方案。. 然而,由于所有不同的输入和梯度之间的复杂依赖关系,仍然需要一些同步。 尽管如此,避免“split-K”可以减少共享内存读写,并再次提高速度
- 调整块大小
增加块大小通常会减少共享内存的负载/存储,但会增加所需的寄存器数量和总共享内存量。 超过一定的块大小,寄存器溢出会导致显著的减速,或者所需的共享内存量大于GPU可用的量,无法运行内核。通常我们选择大小为 {64, 128} × {64, 128}的块,具体取决于头维度
我们手动调整每个头维度,因为基本上只有4种块大小可供选择,但这可能会受益于自动调整以避免这种手动劳动
// 待更,以上为初稿,待后续修订..
第四部分 Flash Attention3
自从Flash Attention2于23年7月份提出之后,没想到刚过去一年,Flash Attention3便出来了,其论文为:FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
FlashAttention通过最小化内存读写来加速GPU上的注意力机制。 然而,它尚未利用最近硬件中的新功能,FlashAttention-2在H100 GPU上的利用率仅为35%
故在Flash Attention3时,作者团队开发了三种主要技术来加速Hopper GPU上的注意力机制:利用张量核心和TMA的异步性来
- 通过warp-specialization重叠整体计算和数据移动
生产者-消费者异步:定义了一种专门针对 warp 的软件流水线方案,通过将数据的生产者和消费者分成不同的 warp,利用数据移动和张量核心的异步执行,从而扩展算法隐藏内存和指令发出延迟的能力 - 交错块状矩阵乘法和softmax操作
将 softmax 中涉及的相对低吞吐量的非 GEMM 操作(如浮点乘加和指数运算)与 GEMM 的异步 WGMMA 指令重叠
在此过程中,我们重新设计了FlashAttention-2算法,以规避 softmax 和 GEMM 之间的某些顺序依赖。例如,在算法的两阶段版本中,当 softmax 在分数矩阵的一个块上执行时,WGMMA 在异步代理中执行以计算下一个块 - 利用硬件支持FP8低精度的不一致处理
调整了前向传递算法,以便针对FP8张量核心进行GEMM,几乎使测量的TFLOPs/s翻倍。这需要在WGMMA的不同布局一致性要求之间架起桥梁,因为FP32累加器和FP8操作数矩阵的
内存布局假设不同。使用块量化和非相干处理技术来减轻转向FP8精度所导致的精度损失
最终,FlashAttention-3,在H100 GPU上实现了1.5-2.0×的加速,FP16达到最高740 TFLOPs/s(75%利用率),FP8接近1.2 PFLOPs/s
// 待更
后记:好的文章 三层标准
其实本文在24年五一之前的版本,离我心中的满意 差距还很大,但之前一直没时间写第三部分 Flash Attention2,更不用说去修订原来的第二部分 Flash Attention了,好在24年五一假期有五天,这才有时间来写第三部分以及修订第二部分
我一旦开弄某篇文章,那基本好几天都会弄那篇文章了,毕竟自己对好的文章有着孜孜不倦的追求,而好的文章有三层标准
- 逻辑清晰 通俗易懂,说白了,不卡壳
- 赏心悦目,阅读是一种享受
- 可以流传几十年甚至上百年
博客内200多篇,达到第一层标准的很多,但第二层标准的还不多,更希望这辈子多留几篇可以传百年的,至于本文,尽可能在24年年底达到上述的第二层标准
参考文献与推荐阅读
- Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT
- 分析transformer模型的参数量、计算量、中间激活、KV cache
- FlashAttention:加速计算,节省显存, IO感知的精确注意力
- FlashAttention 的速度优化原理是怎样的?,其中Civ、marsggbo回答的均不错
- FlashAttention图解(如何加速Attention)、FlashAttention算法详解
- 图解大模型计算加速系列:FlashAttention V1,从硬件到计算逻辑
- 图解大模型计算加速系列:Flash Attention V2,从原理到并行计算
- 《大规模语言模型:从理论到实战》
-
kernel融合的示意图:https://www.bilibili.com/video/BV1Zz4y1q7FX/
创作与修订记录
- 10.6,在《ChatGLM两代的部署/微调/实现》一文中阐述「FlashAttention的原理与结构:减少内存访问提升计算速度」时,感觉会越写越长,故把FlashAttention相关的内容放到本新一篇博客里
- 10.7,主要修订第一部分
- 10.8,主要修订第二部分的2.2节
- 10.9,反复修订2.2节,以最大程度的提高可读性
反复修订2.2.1.1节:通过23个公式全面理解分块计算注意力tiling
反复修订2.2.1.3节:Flash Attention算法的前向计算算法 - 12.27,在“1.2.1 Self-Attention块的中间激活”节中新增一个说明解释
- 12.28,在“Flash Attention算法的前向计算算法”节中补充一个对理解该算法外循环、内循环很重要的两张图
并把本文的标题改成最新的:《通透理解FlashAttention与FlashAttention2:全面降低显存读写、加快计算速度》 - 24年3.2,为此节:“2.2.1.3 Flash Attention算法的前向计算算法”增加一个图、一个表,以不断达到极致的一目了然
- 24年4.22,因为「大模型线上营」一学员针对1.1.1节提出了个问题,故马上就把其对应的说明解释 更新到了文中,我大部分文章 都是长久维护的,越久越能打
- 24年5.1~5.3,完成「第三部分 Flash Attention2:比Flash Attention快2倍」的初稿
由于Flash Attention在我司七月审稿项目组做论文审稿GPT时频繁用到(当然,默认用的2)
虽然本文介绍了其V1版本,但其V2版本有比较大的优化,所以总算开写这个Flash Attention2了
且5.3日晚上修订「第二部分 Flash Attention:通过kernel融合降低HBM读写次数,避免频繁地从HBM中读写数据」,以使该节的整体内容更精炼 - 5.4,再次修订「第二部分 Flash Attention」,以让行文更流畅、清晰,提高可读性
- 7.24,本文读者“银翼手刹”在本文评论区指出:
3.1.2 Flash Attention2的前向传播算法一节中,3.部分 到数第二个公式的diag不应该有-1次方,论文作者在他个人主页修复了,详见:https://tridao.me/publications/flash2/flash2.pdf
故而修正这个问题 - 8.6,开写本文的第四部分Flash Attention 3
- ..


















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











