







1、概述
- 是生命周期至关重要的一步,模型运行的关键部分

- 监控的2个层面
- 资源层面
- 目的
- 确保模型在生产环境中正确运行
- 关键
- 系统是否还存在?
- CPU、GPU、RAM、网络使用率和磁盘空间是否符合预期?
- 请求是否以预期的速度得到处理?
- 目的
- 性能层面
- 目的
- 随时间监控模型的相关性
- 关键
- 模型是否仍然是新输入数据的准确表示?
- 它的性能和设计阶段一致吗?
- 目的
- 资源层面
2、模型再训练频率
2.1、取决于
2.1.1、领域
- 网路安全或实时交易领域需要实时更新
- 物理模型通常更稳定,更新频率无需实时
- 例如语音识别
2.1.2、成本
- 每次训练的成本和获得的收益进行对比,看是否值得
2.1.3、模型性能
- 是否有足够的新数据(训练示例)
2.1.4、一个上限
- 每年进行一次,确保模型可用
2.1.5、一个下限
- 不可能每天一次
2.2、在线学习
2.2.1、和标准算法再训练的不同
- 在线学习:迭代式自我训练
- 标准算法再训练:从头开始训练(深度学习算法除外)
2.2.2、优点
- 概念上有吸引力
- 在流式用例中适用
2.2.3、缺点
- 算法设计成本高
- 在测试数据集上测试模型性能
- 在数据改变时限定其行为
- 没有标准方法完成这个过程
- 算法是有状态的,因为每次运行都在学习,所以在相同的数据上运行会有不同的结果。
2.3、监控和通知
2.3.1、作用
- 可以诊断问题并进行下一步行动
2.3.2、实现
- 自动触发模型性能退化的检查
- 监控指标
- 警告阈值
- ...
- 理解模型退化至关重要
3、模型退化(性能退化)
3.1、基本事实评估
3.1.1、挑战与解决
- 基本事实并非立竿见影或迫在眉睫
- 具有长滞后的模型需要缓解措施
- 基本事实和预测分离
- 将基本事实和观测结果匹配
- 基本事实仅部分可用
- 选择有意义的样本,使系统避免偏差
- 标记的样本子集必须覆盖所有可能的未来预测
3.1.2、步骤
- 第一步:等待标签事件,收集新的基本事实
- 第二步:根据基本事实计算模型性能
- 第三步:训练时与指标进行比较,分析差异是否超过阈值来确定是否需要再训练
- 指标包含
- 统计指标(无关领域)
- 准确性
- ROC
- AUC
- 对数损失(log loss)
- ...
- 业务指标
- 作用
- 使行业专家能够更好地处理再训练的决策成本效益权衡
- 包括
- 成本效益评估
- 例如信用评分业务开发了自己特定指标
- ...
- 成本效益评估
- 作用
- 统计指标(无关领域)
- 指标包含
3.2、输入漂移检测
3.2.1、作用
- 是基本事实评估的补充
3.2.2、分类
- 漂移
- 用第一个数据集训练算法,用第二个数据集部署,由此产生的分布漂移
- 特征漂移
- 如果两个数据的分类标准是数据集中的特征之一,或与数据集中的特征相关联,则称为特征漂移
- 概念漂移
- 不是特征漂移,就是概念漂移
4、漂移检测实践
4.1、数据漂移的2个常见原因
- 样本选择偏差
- 由于数据的特征有可能是未知的、不可用的,所以有时候训练的数据不代表总体。
- 非平稳环境
- 通常发生在依赖时间的预测用例中,具有季节性,无法通过这个月的数据来推算下个月的样本。
4.2、检测漂移方法
4.2.1、方法1:单变量统计测试
- 场景
- 需要经过验证和可解释的方法的组织
- 要求
- 对每个特征的源分布和目标分布的数据进行统计测试,测试结果很重要的时候会发出警告
- 依赖
- 对于连续特征,Komogorov-Smirnov检验
- 是非数据假设检验
- 用于检查2个样本是否来自同一个分布
- 测量分布函数之间距离
- 对于分类特征,卡方检验
- 用于检查数据中分类特征的观察频率是否与原数据中预期频率相匹配
- 对于连续特征,Komogorov-Smirnov检验
- p值
- 优点
- 有助于尽快低检测漂移
- 缺点
- 可以检测到影响,但是不能量化影响程度
- 解决办法
- 业务开发数据量大的时候,需要用业务指标补充p值
- 优点
4.2.2、方法2:领域分类器
- 场景
- 同时涉及多个特征的复杂漂移是可以预期的
- 想要重用他们已知且假设组织不在乎黑盒效应
- 目的
- 预测数据来源
- 内容
- 将原始数据和开发数据集叠加并训练
- 模型的性能就是漂移水平
- 性能高,则高漂移
- 数据可以被区分,新数据漂移了
- 扩展
- 可以通过模型特征的重要性来识别造成漂移的特征有哪些。
4.2.3、分类
- 归因于目标的漂移
- 很重要,直接影响业务的底线
- 归因于特征的漂移
- 通过增加某特征的权重减轻漂移的影响
4.3、反馈回路
4.3.1、概念
- 来自生产环境的数据回流到开发环境模型,方便进一步改进模型
- 当模型性能下降
- 用新的标记数据再训练
- 开发具有附加特征的新模型
4.3.2、流程图
- 端到端机器学习过程的连续交付
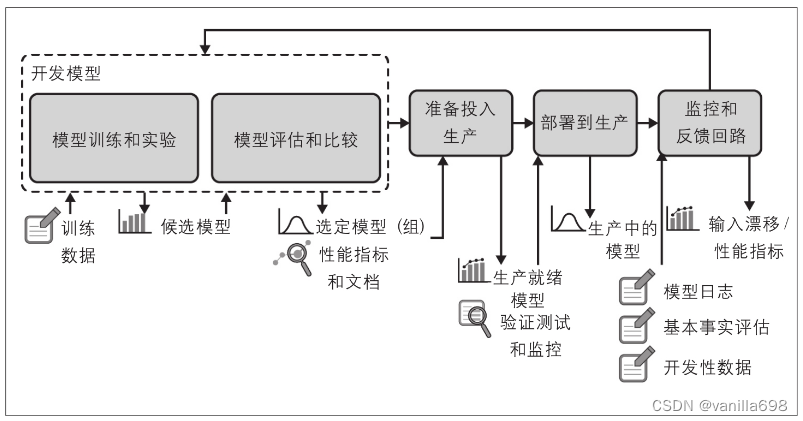
4.3.3、日志
- 时间戳
- 模型元数据
- 模型版本和标识
- 模型输入
- 新观测到的特征值来验证是否符合模型期待从而允许数据漂移
- 模型输出
- 给出生产环境模型性能的预测
- 系统行为
- 根据预测系统采取的行为,例如警告、通过等详细信息
- 模型解释
- 适用于高度监管领域,例如金融或医疗
- 一般通过夏普利值计算
- 包括
- 偏差情况
- 拟合情况
- ...
4.3.4、模型评估
4.3.4.1、场景
- 数据发生了偏移
- 性能下降
- 随着时间推移正常监测
4.3.4.2、方法
- 再训练模型与候选模型比较(在同一个数据集下)
- 更新新模型
- 通过A/B测试在线评估
- 通过影子测试在线评估
4.3.4.3、逻辑模型
- 背景
- 模型随着时间不断变化,动态的
- 概念
- 更高的抽象层来推理机器学习应用程序
- 目的
- 解决业务问题的模型版本及其版本集合
- 例如
- 模型的3个版本
- 第一个是基于原始数据的模型
- 第二个是基于原始模板,使用新数据进行训练
- 第三个是基于深度学习的模板和附加特征,数据与第二个版本一致进行训练
- 然后在同一个数据集中评估这3个版本
- 模型的3个版本
4.3.4.4、模型评估存储
- 概念
- 是集中与模型生命周期相关数据进行比较的结构
- 任务
- 对逻辑模型随时间变化的版本包含训练阶段的所有信息
- 所用的特征列表
- 每个特征的预处理技术
- 使用的算法
- 所选的超参
- 训练数据集以及版本
- 用于评估模型的测试数据集
- 评估指标
- 比较不同版本之间的性能必须在同一个数据集(同一版本)上评估
- 对逻辑模型随时间变化的版本包含训练阶段的所有信息
- 数据集的选择
- 有足够的新数据和标注
- 最接近生产环境数据
- 已部署模型的原始数据集来了解漂移情况
- 确认最佳模型后需要在生产环境面对真实数据给出真实反馈
4.3.5、在线评估
- 影子测试
- 可以预测哪些是挑战者、哪些是候选人
- A/B测试
- 无法对模型的基本事实产生评估
- 过程
- 在测试前
- 定义目标:量化的业务目标
- 定义统计协议:精度、相同值等
- 定义测试持续时间
- 在测试中
- 即使发生显著差异,也不要停止实验
- 在测试后
- 确保收集数据质量良好
- 在测试前















 511
511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











