







deepseek r1 推理模型最近非常火爆,以至于 服务一直不稳定,无法正常访问,这篇文章介绍了如何在本地部署 deepseek r1 模型,以及 如何在 pc 端、app 手机端离线使用本地部署的模型。

最后,介绍一种在手机端侧直接运行 deepseek 模型的方法,该方法直接将模型下载到手机端侧运行,完全不依赖任何环境。
-
下载安装ollama
来到 ollama.com/ 官网,下载 ollama 应用,下载后,直接安装即可。
下载完成后,来到 官网搜索需要下载的模型:
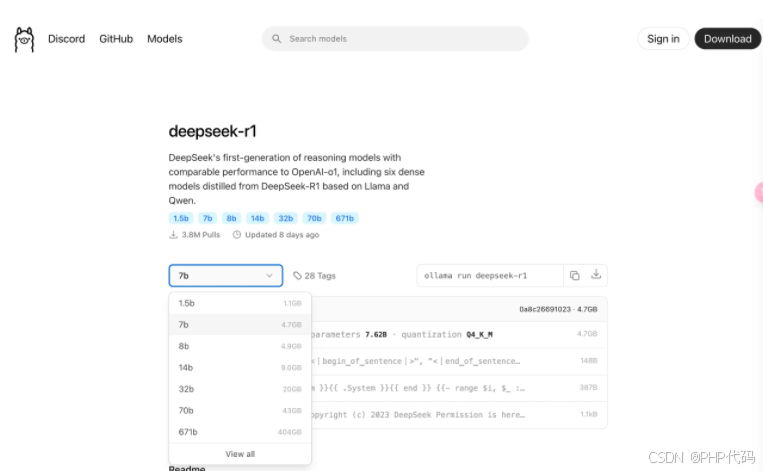
这里选择 7b模型,或者选择1.5b模型(模型越大,需要的内存越大),选择完成后,复制命令,如果是 mac 电脑,直接打开 terminal ,在命令行中输入命令:
ollama run deepseek-r1:7b等待模型下载完成后,就可以直接进行对话了。

但是这样只是命令行的交互,并不方便,而且也没有对话记忆等功能。所以我们还要进行下一步。
-
下载应用 chatbox
来到 官网:chatboxai.app/zh,直接下载安装。支持 windows、macos、ios、android 等多个平台。
下载完成之后,下面以 MacOS 和 Android 平台来介绍如何使用,其他平台的操作类似。
MacOS 平台:
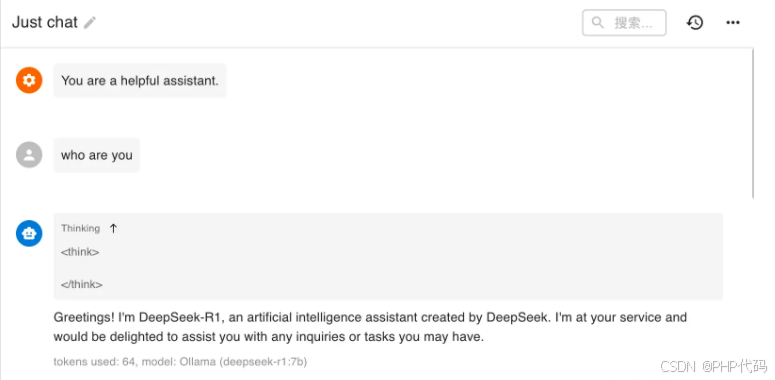
选择模型为deepseek:
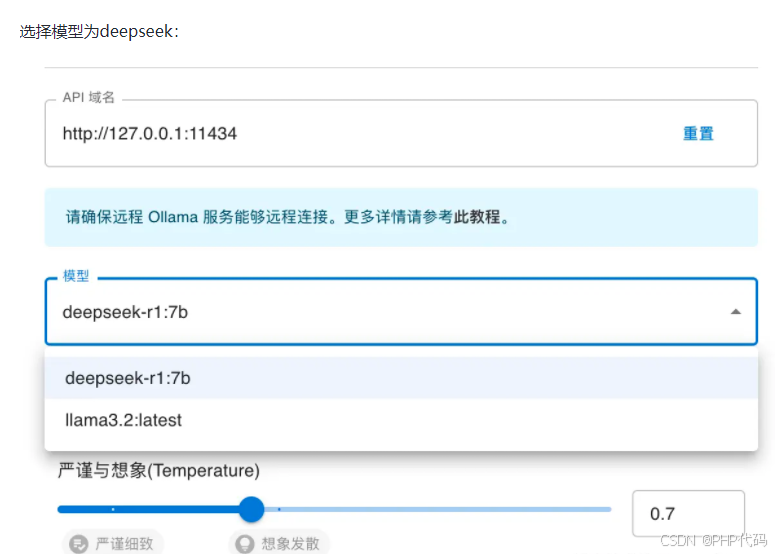
设置完成后,就可以直接对话啦。
Android 平台:
在手机上使用的原理就是将 PC 电脑上的本地部署环境通过暴露端口同步给手机进行连接。所以,
我们需要按照以上步骤在 PC 电脑上配置好本地部署的环境,然后通过 Ngrok 工具暴露私有端口到互联网。
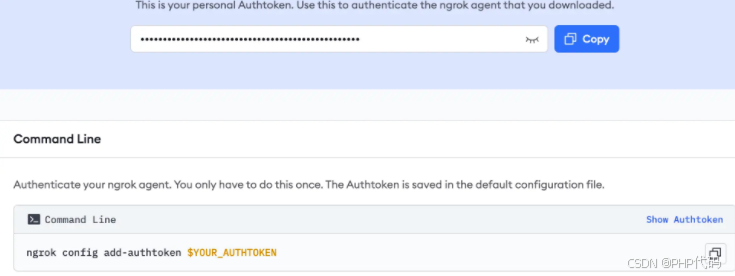
首先 注册一个 Ngrok 账号,在terminal中输入下面的命令,记得替换$your_authtoken部分为实际的token,配置好 auth token:
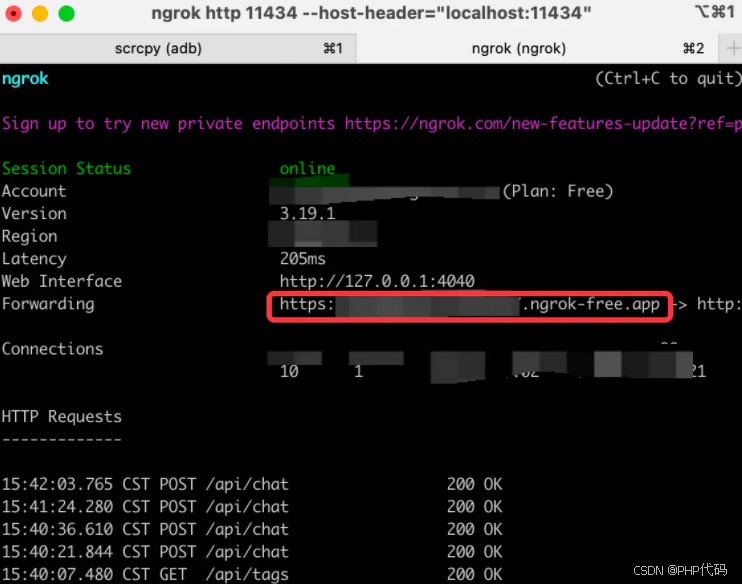
然后在 terminal 终端中输入:
brew install ngrok
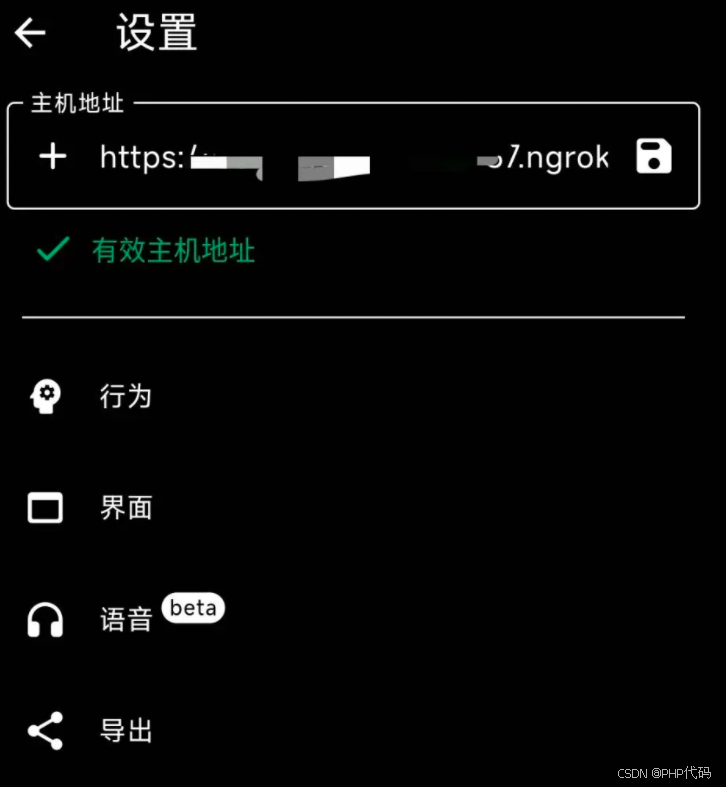
ngrok http 11434 --host-header="localhost:11434"brew install ngrok ngrok http 11434 --host-header="localhost:11434"运行成功之后,复制下面的链接,粘贴到手机的设置中去即可。
下载 安装 github.com/JHubi1/olla… ollama app 应用。填入复制的链接即可。这样,在手机上就可以访问到我们部署到 PC 本地的模型了。
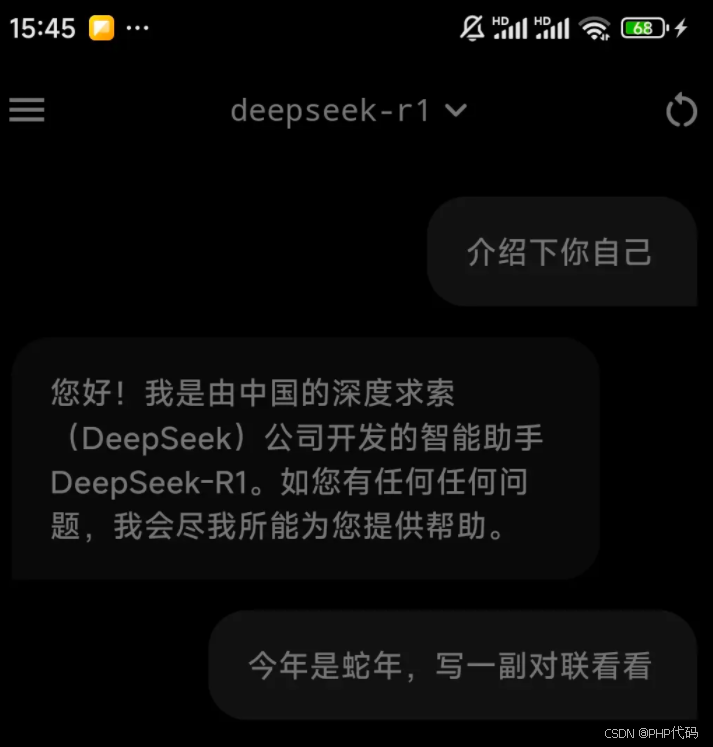
浏览器插件:
首先,在插件商店搜索 Page assist 浏览器插件添加到Chrome 或者是 edge 浏览器中,然后在设置中设置 ollama 配置,可以将最大令牌数设置大一点,这样就可以支持长对话了。
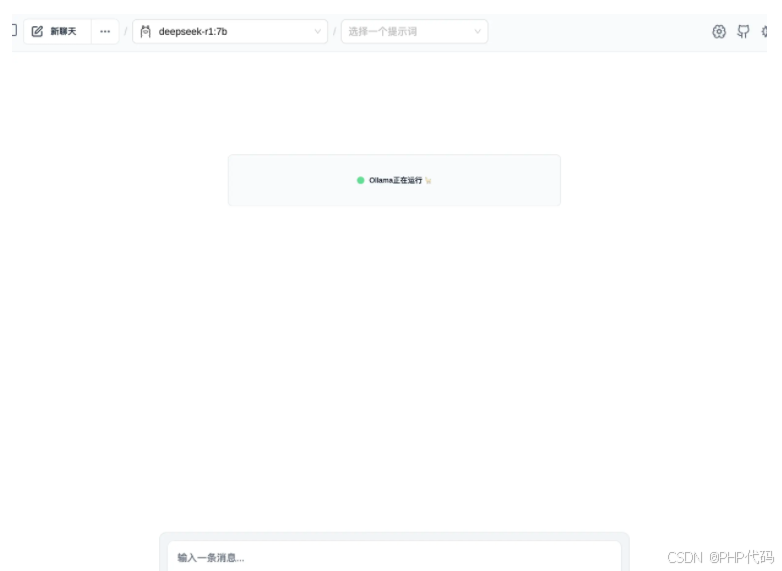
主页面上可以选择deepseek模型开始对话了。
以上,介绍了本地部署 deepseek模型的步骤,以及通过不同的终端(PC端、APP端、浏览器插件)来与本地部署模型交互的过程。
虽然本地部署的模型一般没有办法部署完全版本的大模型,但是本地部署模型也有诸多好处:
-
本地部署不依赖于第三方服务,因此不会因云服务的波动或故障而导致模型运行中断,例如现在 deepseek服务不稳定,经常性的无法访问,但是,通过本地部署就可以无限制的使用。
-
本地部署可以在内部网络中隔离模型运行环境,防止数据泄露或受到外部攻击影响。能够更好地保护个人隐私。
-
本地部署可以充分利用本地硬件(如GPU或TPU)的高性能计算能力,不需要依赖云端算力。
APP端完全离线运行:
最后,介绍一种完全离线,不依赖 PC端本地环境的纯 APP 端本地运行 Deepseek r1 模型的方案。
第一步:下载 Temux linux 环境模拟器。来到官网,下载 Android app 进行安装:termux.dev/en/。
Termux 是一个在 Android 系统上提供类似于 Linux 环境的开源应用程序。实际上就是在Android 设备上的 Linux虚拟环境,可以在这个沙盒环境中安装 llama.app 来本地运行模型。
llama.cpp 是一个开源项目,用于在设备上本地运行深度学习模型。项目中包含的工具和库可以让你轻松地在个人设备(例如电脑或手机)上加载和运行模型,而无需互联网连接或依赖外部服务。
以下是具体步骤:
使用 Termux,就可以像 Linux 环境一样安装和运行 llama.cpp。进入 Termux shell 后,安装必要依赖:
apt update && apt upgrade -y $ apt install git cmake获取 llama.cpp 以及 安装编译 llamacpp
git clone <https://github.com/ggerganov/llama.cpp> cd llama.cpp使用 Cmake 编译 llamacpp:
cmake -B build cmake --build build --config Release -j 8
编译完成后,下载deepseek r1 蒸馏后的1.5b的模型,模型格式 为 gguf:这里注意要复制正确的下载链接(红框中的按钮)
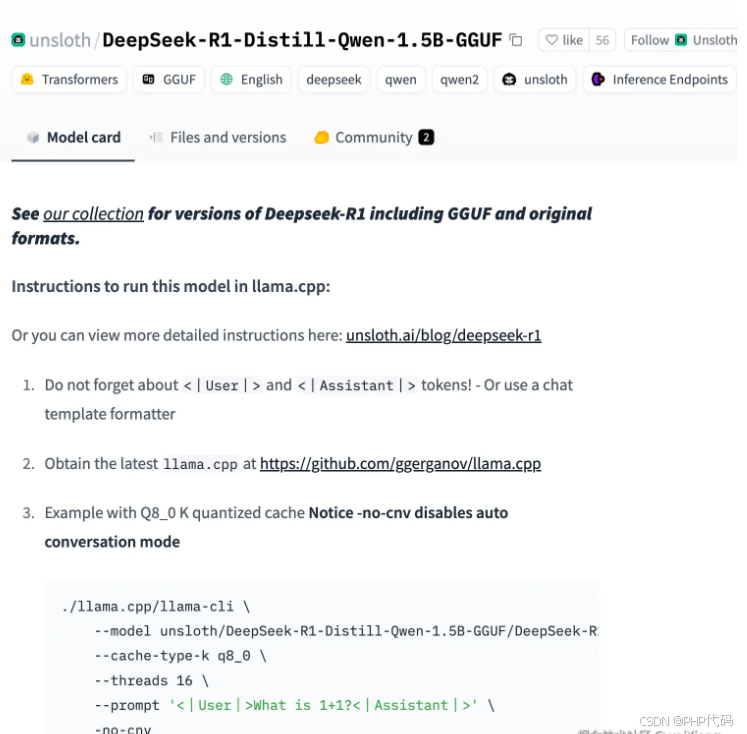
执行以下命令,下载 deepseek模型到 手机上。下载过程中可能无任何输出,等待即可(需要手机科学上网能访问 huggingface.co 网站才行)。
curl -fsSL https://huggingface.co/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF/resolve/main/DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf -o ~/deepseekr115bq4km.gguf确保当前目录为 llama.app/ 然后运行以下命令:

./build/bin/llama-cli -m ~/deepseekr115bq4km.gguf -c 4096 -p "You are a helpful assistant."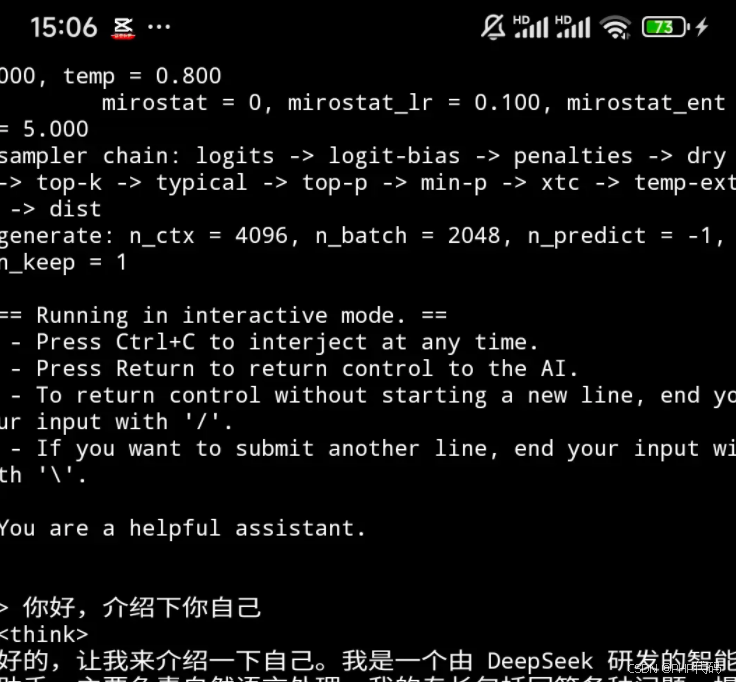
运行命令后,就可以开启对话啦,但是由于android 设备性能的限制,输出较慢,但是该方法可以完全离线执行,不依赖任何环境。通过该方法也可以感受一下我们距离真正在端侧部署大模型进行应用还有多远。以后有新的更小的模型,也可以通过该方法来验证下在手机端上的性能。
容器化 OLLAMA概念



















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











