










引用
preempt
softirq
tasklet
workqueue
timer
一. 为什么要有上下半部
中断分成上下半部处理可以提高中断的响应能力,在上半部处理完成后便将cpu中断打开(通常上半部处理越快越好),这样就可以响应其他中断了,等到中断退出的时候再进行下半部的处理。

二. preempt_count

task_struct结构体中的thread_info.preempt_count用于记录当前任务所处的context状态;
PREEMPT_BITS
用于记录禁止抢占的次数,禁止抢占一次该值就加1,使能抢占该值就减1;
SOFTIRQ_BITS
用于同步处理,关掉下半部的时候加1,打开下半部的时候减1;
HARDIRQ_BITS
用于表示处于硬件中断上下文中;
in_softirq和in_serving_softirq都表示处于softirq上下文,但并不意味着程序正在执行软中断,区别是:
in_serving_softirq表示 当前一定有软中断处于执行状态。(bit8 - SOFTIRQ_OFFSET)
in_softirq 除了可以表示当前有软中断处于执行状态,还有可能表示当前的context只是disable软中断的thread上下文。(例如:local_bh_disable()下的context)
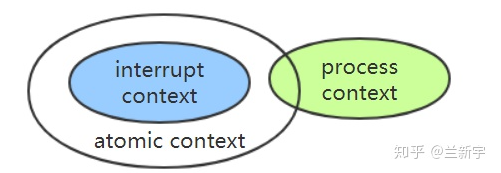
中断上下文 - interrupt context
我们将 NMI, HARDIRQ, SOFTIRQ 上下文 统称为中断上下文。
可用 in_interrupt() 判断
进程上下文 - process context
与中断上下文相对应。
可用 in_task() 判断
原子上下文 - atomic context
不能发生进程睡眠或者调度的上下文。
处于中断上下文,或者显示地禁止了调度,preempt_count()的值都不为0,都不允许睡眠/调度的发生,这两种场景被统称为atomic上下文。
可用 in_atomic() 来判断当前cpu是否处于atomic上下文。
也就是非 preempt_count 非 0 时,都属于 atomic 上下文,其中包括中断、软中断等中断上下文,还包括进程或者内核线程运行时关中断或者关抢占。
由于该接口在有些场景下不能精确检测,所以 不推荐在driver中使用。
三种上下文的关系
三. softirq
softirq是静态的,不支持动态分配。
相关数据结构
/* 支持的软中断类型,可以认为是软中断号, 其中从上到下优先级递减 */
enum
{
HI_SOFTIRQ=0, /* 最高优先级软中断 */
TIMER_SOFTIRQ, /* Timer定时器软中断 */
NET_TX_SOFTIRQ, /* 发送网络数据包软中断 */
NET_RX_SOFTIRQ, /* 接收网络数据包软中断 */
BLOCK_SOFTIRQ, /* 块设备软中断 */
IRQ_POLL_SOFTIRQ, /* 块设备软中断 */
TASKLET_SOFTIRQ, /* tasklet软中断 */
SCHED_SOFTIRQ, /* 进程调度及负载均衡的软中断 */
HRTIMER_SOFTIRQ, /* Unused, but kept as tools rely on thenumbering. Sigh! */
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq, RCU相关的软中断 */
NR_SOFTIRQS
};
/* 软件中断描述符,只包含一个handler函数指针 */
struct softirq_action {
void (*action)(struct softirq_action *);
};
/* 软中断描述符表,实际上就是一个全局的数组 */
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;
/* CPU软中断状态描述,当某个软中断触发时,__softirq_pending会置位对应的bit */
typedef struct {
unsigned int __softirq_pending;
unsigned int ipi_irqs[NR_IPI];
} ____cacheline_aligned irq_cpustat_t;
/* 每个CPU都会维护一个状态信息结构 */
irq_cpustat_t irq_stat[NR_CPUS] ____cacheline_aligned;
/* 内核为每个CPU都创建了一个软中断处理内核线程 */
DEFINE_PER_CPU(struct task_struct *, ksoftirqd);数据结构关系图
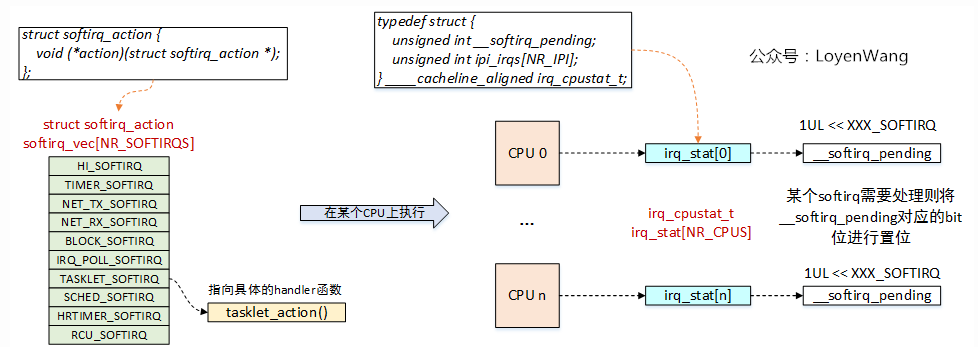
softirq_vec[]数组,类比硬件中断描述符表irq_desc[],通过软中断号可以找到对应的handler进行处理,比如图中的tasklet_action就是一个实际的handler函数;
软中断可以在不同的CPU上并行运行,在同一个CPU上只能串行执行;(即软中断不保证重入问题)
每个CPU维护irq_cpustat_t状态结构,当某个软中断需要进行处理时,会将该结构体中的__softirq_pending字段或上1UL << XXX_SOFTIRQ;
软中断的触发点
raise_softirq()/raise_softirq_irqoff() 会设置当前本地cpu的irq_stat中的 __softirq_pending字段,并将相应的软中断号置位,即表明该软中断有处理请求。
软中断执行点
中断处理后;
bottom-half enable后;
思考
为什么在使能Bottom-half时要进行软中断处理呢?
==》
在并发处理时,可能已经把Bottom-half进行关闭了,如果此时中断来了后,软中断不会被处理,在进程上下文中打开Bottom-half时,这时候就会检查是否有软中断处理请求了;
四. tasklet
tasklet是软中断的一种类型,那么两者有啥区别呢?
软中断类型内核中都是静态分配,不支持动态分配,而tasklet支持动态和静态分配,也就是驱动程序中能比较方便的进行扩展;
软中断可以在多个CPU上并行运行,因此需要考虑可重入问题,而tasklet会绑定在某个CPU上运行,运行完后再解绑,不要求重入问题,当然它的性能也就会下降一些;
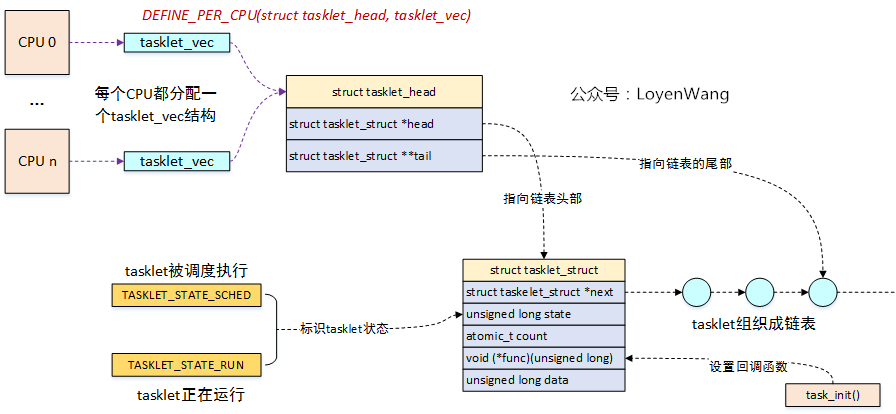
DEFINE_PER_CPU(struct tasklet_head, tasklet_vec)为每个CPU都分配了tasklet_head结构,该结构用来维护struct tasklet_struct链表,需要放到该CPU上运行的tasklet将会添加到该结构的链表中,内核中为每个CPU维护了两个链表tasklet_vec和tasklet_vec_hi,对应两个不同的优先级,本文以tasklet_vec为例;
struct tasklet_struct为tasklet的抽象,几个关键字段如图所示,通过next来链接成链表,通过state字段来标识不同的状态以确保能在CPU上串行执行,func函数指针在调用task_init()接口时进行初始化,并在最终触发软中断时执行;
接口
/* 静态分配tasklet */
DECLARE_TASKLET(name, func, data)
/* 动态分配tasklet */
void tasklet_init(struct tasklet_struct *t, void (*func)(unsigned long), unsigned long data);
/* 禁止tasklet被执行,本质上是增加tasklet_struct->count值,以便在调度时不满足执行条件 */
void tasklet_disable(struct tasklet_struct *t);
/* 使能tasklet,与tasklet_diable对应 */
void tasklet_enable(struct tasklet_struct *t);
/* 调度tasklet,通常在设备驱动的中断函数里调用 */
void tasklet_schedule(struct tasklet_struct *t);
/* 杀死tasklet,确保不被调度和执行, 主要是设置state状态位 */
void tasklet_kill(struct tasklet_struct *t);五. workqueue/delay wrokqueue
CWMQ (concurrency-managed workqueues)解决了什么问题?
内核线程数量太多。虽然系统中默认有一套工作线程,但有很多工程师系统喜欢自行创建工作线程,对于CPU数量比较多的机器,系统启动完可能就耗尽了PID资源。
并发性比较差。Multi threaded的工作线程和CPU是一一绑定的,某个本地CPU上的工作任务是串行执行的。如某个线程上的工作任务发生了睡眠,之后的工作任务只能等待,前一个任务没有执行完成,则后一个任务永远无法得到执行,也不能迁移到其他空闲CPU上执行。
死锁问题。如果有很多的工作任务运行在系统默认的工作队列上,并且他们有一些数据依赖关系,那么很有可能产生死锁问题。
为了解决上述问题,Linux内核引入了concurrency-managed workqueues(CWMQ),和旧的workqueue接口兼容,明确划分了workqueue的前端接口和后端实现机制。CWMQ提出了工作线程池(worker_pool)概念,不和特定的工作队列关联。工作线程池有两种。一种和具体CPU绑定,为Per-CPU类型,有两个线程池,一个给高优先级的work使用,另一个给低优先级的work使用。另外一种不和具体CPU绑定,可以运行在任意CPU上,工作线程池中的线程是动态分配和管理,线程数量不固定,缺省情况下会创建一个线程来处理工作任务。用户在使用workqueue时,无需关心放在哪个CPU上执行,也无需再创建额外的线程,只需要设置相关flag和优先级,内核会将工作任务放在合适的线程池中执行。当某个工作任务阻塞时,CWMQ会唤醒或创建新的线程执行后续的工作任务,以提高并发效率。
linux workqueue机制有多个woker 线程?
内核的CMWQ有多个worker_pool,管理多个worker。
初始化时,会给每个CPU都有创建两个worker_pool,对应不同的优先级,nice值分别为0和-20 <==> 针对bound类型的workqueue,其提交的work会被派发到上面类型的worker_pool中被执行。
初始化时,会默认创建unbound workqueue属性(struct workqueue_attrs),主要描述内核线程的nice,cpumask,no_numa;默认有创建 unbound and ordered (unbound_std_wq_attrs, ordered_wq_attrs) 两种类型的wq attrs,且每种类型有两个实例,区别是nice值不一样,一个是0,一个是-20;<==> 当创建unbound workqueue时,会根据workqueue_attrs来判断是否已经有创建好的worker_pool,如果没有,则创建新的worker_pool并挂入到unbound_pool_hash 中。其中,可指定 __WQ_ORDERED来表明使用 ordered_wq_attrs,否则,使用 unbound_std_wq_attrs;(即相同属性的workqueue使用相同的worker_pool,不同属性的workqueue使用不同的worker_pool,如果woekqueue相关属性没有对应的worker_pool,则会动态创建一个, 即unbound的worker_pool会随着不同属性的workqueue的创建而动态创建。)
在初始化时workqueue_init(), 会为每个worker_pool中创建一个worker,后续会根据需要work的数量和worker的数量进行动态创建和销毁;
create_worker函数中,创建的内核线程名字为kworker/XX:YY, kworker/XX:YYH或者kworker/uXX:YY,
bound: XX表示cpu的编号,YY表示worker的编号,H表示是high prio的worker;
unbound: u表示unbound,XX表示worker_pool的编号,YY表示worker的编号;
bound和un-bound workqueue的区别?
bound:绑定处理器的工作队列,其会被bound的worker_pool服务,该worker_pool是绑定cpu的,即创建的worker内核线程会被绑定到特定的CPU上运行;
unbound:不绑定处理器的工作队列,其会被un-bound的worker_pool服务,创建的时候需要指定WQ_UNBOUND标志,内核线程可以在处理器间迁移;
何时创建更多的worker?
worker线程worker_thread() 运行时,如果没有空闲idle的worker,会调用manage_workers()接口来创建更多的worker来处理工作;
即一个worker_pool会保证至少有一个idle状态的worker存在,以保证worker_pool的并发能力。
何时销毁多余的worker?
一个worker被创建后,首先进入worker_enter_idle(),里面启动了pool->idle_timer,定时IDLE_WORKER_TIMEOUT即300HZ。如果一个worker进入idle超过300HZ,即会执行idle_worker_timeout(),会根据情况进行销毁多余的worker。
销毁策略 too_many_workers()
满足idle worker数量大于2;
除去两个idle worker线程外的idle worker不能超过busy worker的1/4。
所以每个worker_pool最少两个worker线程。例如,如果worker_pool中有4个worker(3idle+1busy),则3>2,并且(3-2)*4>1,即会选择一个idle销毁。
如何解决一个work阻塞或者死锁了,导致其他的work得不到执行,即各种work之间的互相影响?
在worker线程执行时,会尝试进行worker_pool管理工作 manage_workers() ,即会检查worker_pool中是否有至少一个idle状态的worker,如果没有,则创建一个新的worker。
启动一个100ms的定时器worker_pool->mayday_timer,检查当前worker_pool中是否存在allocation deadlock异常(即因为没有内存等资源,导致该workqueue对应的worker_pool创建新的worker失败),如果有异常,则如果该workqueue指定了WQ_MEM_RECLAIM,则会唤醒该workqueue对应rescuer_thread 进行处理,否则,什么也做不了。
管理worker_pool的内核线程池时,如果有PENDING状态的work,并且发现没有正在运行的工作线程(worker_pool->nr_running == 0),唤醒空闲状态的内核线程,或者动态创建内核线程;
如果work已经在同一个worker_pool的其他worker中执行,不再对该work进行处理(防重入处理);
__queue_owrk() 是如何工作的?
__queue_owrk() 的工作是将work添加到对应的woker_pool->worklist或者pool_workqueue->delayed_works, 如果没有runing的worker,则唤醒一个idle的worker,详细步骤:
确定pool_workqueue,一个pool_workqueue对应一个worker_pool,因此确定了pool_workqueue也就确定了worker_pool;
pool_workqueue分为三种情况:
bound类型的工作队列,直接根据CPU号获取(可指定cpu,如果没有指定,则用当前cpu。);
unbound类型的工作队列,根据cpu所在的node号获取,针对unbound类型工作队列,pool_workqueue的释放是异步执行的,需要判断refcnt的计数值,因此在获取pool_workqueue时可能要多次retry;
根据缓存热度,优先选择正在被执行的worker_pool(所以,指定了cpu也不一定生效);
判断pool_workqueue 中nr_active work数量,如果少于max_active,则将work加入到pool->worklist中,否则,加入到pwq->delayed_works链表中;
插入work到上面选择的list中,如果没有runing的worker,则唤醒一个idle的worker。
WORK_STRUCT_PENDING_BIT何时被设置以及被清0?
当一个work已经加入到workqueue队列中,schedule_work()->queue_work()->queue_work_on()时被设置。
当一个work在工作线程里马上要执行(即执行work之前),worker_thread()->process_on_work()->set_work_pool_and_clear_pend是清0。
上述设置和清0都是在关闭本地中断情况下执行的。
如何判断一个work是否已经全部执行完成?
在目标 work 的后面插入一个新的 work( wq_barrier ),如果 wq_barrier 执行完成,那么目标 work 肯定已经执行完成。
如何指定一个work跑到特定的cpu上?
queue_work_on()可以指定cpu id,但是,不一定能指定成功,策略如下:
如果一个work正在一个worker_pool中执行,则本次work也会被放到正在执行的worker_pool中,是为了利用缓存,提高效率。
如果该work此时没有被执行,则会被放到指定的worker_pool->worklist中,等待执行。
如果一个worker_pool中的worker要进入睡眠了,如何保证其余的work能够被执行?
worker会标志 该内核线程为workqueue worker。PF_WQ_WORKER
当一个worker线程要被调度器换出时,调度器 __schedule() 会调用wq_worker_sleeping()看看是否需要唤醒同一个线程池中的其它内核线程。
workqueue lockup机制是怎么样的?
会用一个timer 检查一个work执行了 30s都没有退出,就会打印warning log。
WQ_MEM_RECLAIM 标志表示什么意思?
创建工作队列workqueue时,如果设置了WQ_MEM_RECLAIM标志,则会新建rescuer worker,对应rescuer_thread内核线程。
目的是当内存紧张时,新创建worker可能会失败,这时候由rescuer来处理这种情况;
alloc_workqueue()中的max_active是什么意思,作用是什么?
决定该workqueue中,在每个cpu上最多有多少个不同work可以被挂入worker_pool->worklist中,多余的work将被挂入到对应pool_workqueue->delayed_works中,等待延迟处理;例如,在4核的cpu上,max_acitve=2,即表示该workqueue可以在每个cpu的worker_pool上最多挂2个work。
对于BOUND类型的工作队列,max_active最大可以是512,如果max_active被设置为0,则表示指定max_active为256.对于UNBOUND类型工作队列,max_active最大值为512和4*num_possible_cpus之间的最大值。
表示该workqueue中最多能有几个work被挂入到对应的 pwq->pool->worklist中,即能被对应worker_pool的worker同时服务。
当进行 queue_work_on()时,会根据 选择的 pool_workqueue的 pwq->nr_active和pwq->max_active大小来 选择将work挂入到pwq->delayed_works,还是挂入到pwq->pool->worklist中。
如果挂入到pwq->pool->worklist中,则意味着该work进入active状态,worker_pool 的worker就可以进行处理;
如果挂入到pwq->delayed_works,则该work还是pending状态(WORK_STRUCT_DELAYED),不会立即被worker执行;只有当一个 worker处理完一个work (process_one_work())时,会检查该work对应的pwq中 的nr_active和max_active,如果nr_active<max_active,则会激活pwq->delayed_works中的一个work (修改WORK_STRUCT_DELAYED,并移动到pwq->pool->worklist),即该work可以被worker执行;
如何实现order workqueue?
必须是unbound workqueue;
max_active设置为1;
怎样保证同一个work不被重复执行?
work会有一个 WORK_STRUCT_PENDING_BIT,该标志 会在queue_work_on()是被设定,在执行该work前被清除。所以,作用是 除了该work正在被执行,最多还允许该work被pending在queue中。
在 worker_thread() 执行work时,如果一个worker发现自己要处理的work正在被另外一个worker线程处理,那么本worker线程将不处理该work,只需要挂入正在执行该work的worker线程的scheduled work list即可。

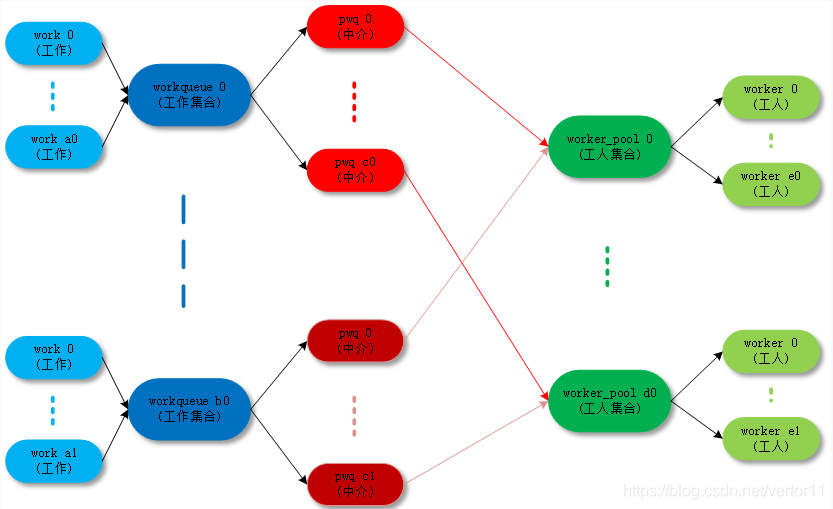

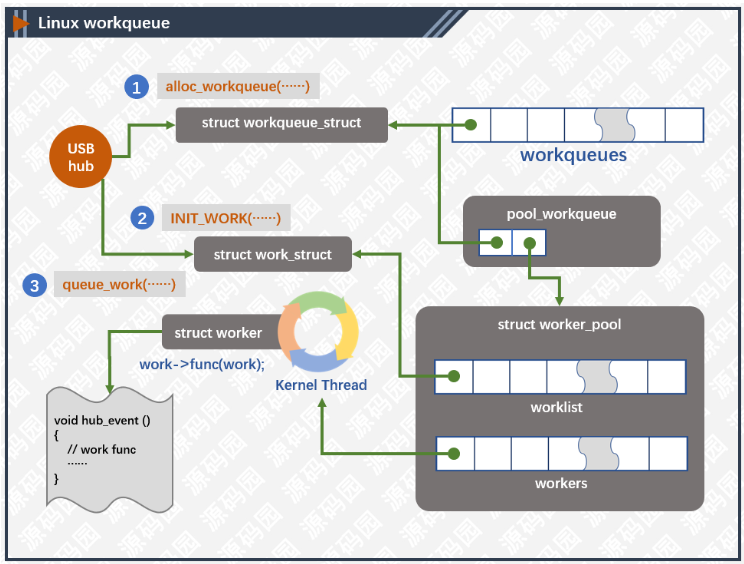
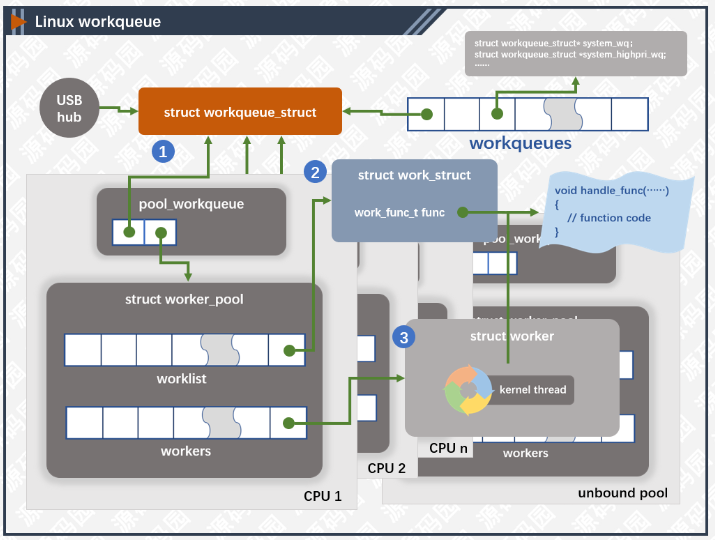
数据结构
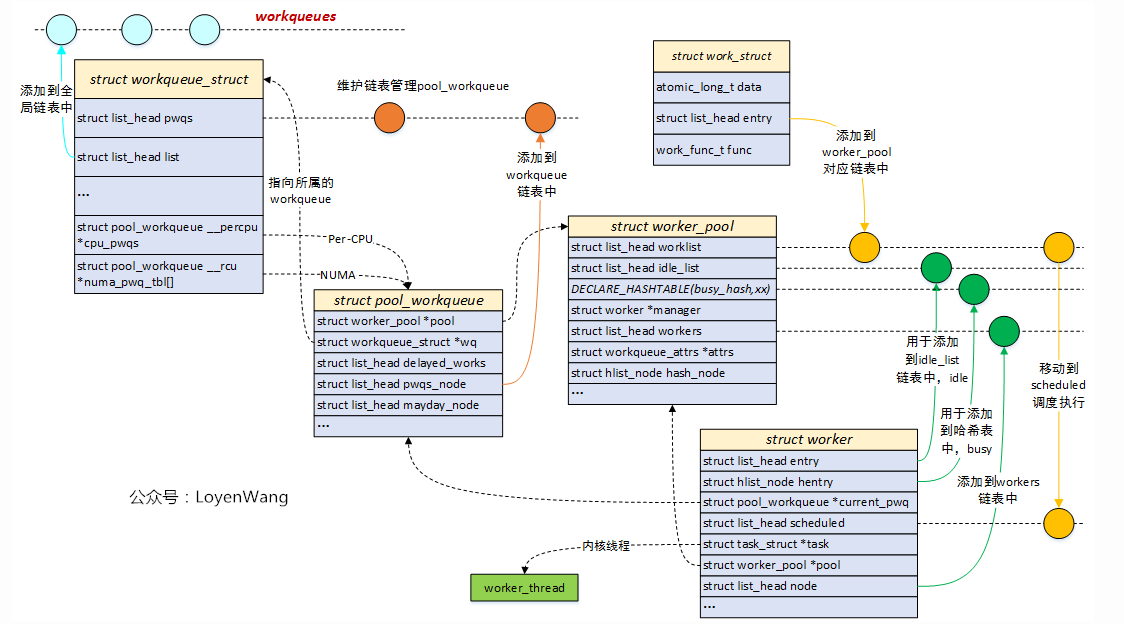
work_struct:工作队列调度的最小单位,work item;
workqueue_struct:工作队列,兼容之前的接口;
worker:work item的处理者,每个worker对应一个内核线程;
worker_pool:worker池(内核线程池),是一个共享资源池,提供不同的worker来对work item进行处理;
pool_workqueue:充当桥梁纽带的作用,用于连接workqueue和worker_pool,建立链接关系;
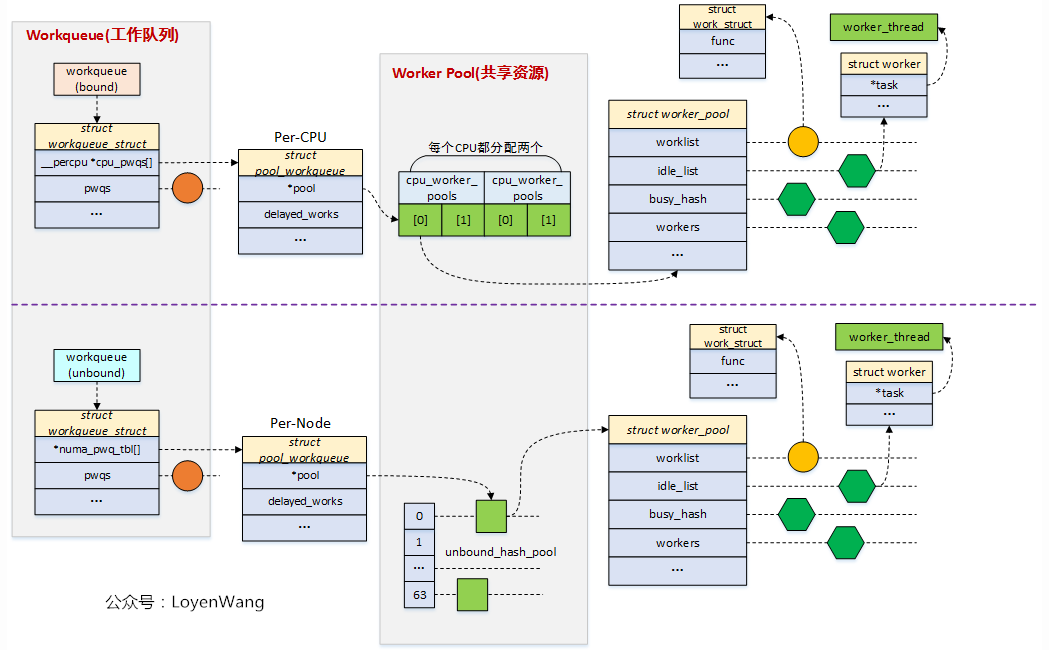
六. timer
6.1 overall

6.2 源码文件
linux kernel 时间子系统的源文件位于linux/kernel/time/目录下,我们整理如下:
文件名 | 描述 |
time.c timeconv.c | time.c文件是一个向用户空间提供时间接口的模块。具体包括:time, stime, gettimeofday, settimeofday,adjtime。除此之外,该文件还提供一些时间格式转换的接口函数(其他内核模块使用),例如jiffes和微秒之间的转换,日历时间(Gregorian date)和xtime时间的转换。xtime的时间格式就是到linux epoch的秒以及纳秒值。 timeconv.c中包含了从calendar time到broken-down time之间的转换函数接口。 |
timer.c | 传统的低精度timer模块,基本tick的。 |
time_list.c timer_status.c | 向用户空间提供的调试接口。在用户空间,可以通过/proc/timer_list接口可以获得内核中的时间子系统的相关信息。例如:系统中的当前正在使用的clock source设备、clock event设备和tick device的信息。通过/proc/timer_stats可以获取timer的统计信息。 |
hrtimer.c | 高精度timer模块 |
itimer.c | interval timer模块 |
posix-timers.c posix-cpu-timers.c posix-clock.c | POSIX timer模块和POSIX clock模块 |
alarmtimer.c | alarmtimer模块 |
clocksource.c jiffies.c | clocksource.c是通用clocksource driver。其实也可以把system tick也看成一个特定的clocksource,其代码在jiffies.c文件中 |
timekeeping.c timekeeping_debug.c | timekeeping模块 |
ntp.c | NTP模块 |
clockevent.c | clockevent模块 |
tick-common.c tick-oneshot.c tick-sched.c | 这三个文件属于tick device layer。 tick-common.c文件是periodic tick模块,用于管理周期性tick事件。 tick-oneshot.c文件是for高精度timer的,用于管理高精度tick时间。 tick-sched.c是用于dynamic tick的。 |
tick-broadcast.c tick-broadcast-hrtimer.c | broadcast tick模块。 |
sched_clock.c | 通用sched clock模块。这个模块主要是提供一个sched_clock的接口函数,调用该函数可以获取当前时间点到系统启动之间的纳秒值。 底层的HW counter其实是千差万别的,有些平台可以提供64-bit的HW counter,因此,在那样的平台中,我们可以不使用这个通用sched clock模块(不配置CONFIG_GENERIC_SCHED_CLOCK这个内核选项),而在自己的clock source chip driver中直接提供sched_clock接口。 使用通用sched clock模块的好处是:该模块扩展了64-bit的counter,即使底层的HW counter比特数目不足(有些平台HW counter只有32个bit)。 |
6.3 常用kernel API
timer.h - include/linux/timer.h - Linux source code (v6.2.5) - Bootlin
#define DEFINE_TIMER(_name, _function) \
struct timer_list _name = \
__TIMER_INITIALIZER(_function, 0)
#define timer_setup(timer, callback, flags) \
__init_timer((timer), (callback), (flags))
#define from_timer(var, callback_timer, timer_fieldname) \
container_of(callback_timer, typeof(*var), timer_fieldname)
#define timer_setup_on_stack(timer, callback, flags) \
__init_timer_on_stack((timer), (callback), (flags))
#define from_timer(var, callback_timer, timer_fieldname) \
container_of(callback_timer, typeof(*var), timer_fieldname)
static inline int timer_pending(const struct timer_list * timer);
extern void add_timer_on(struct timer_list *timer, int cpu);
extern int mod_timer(struct timer_list *timer, unsigned long expires);
extern int mod_timer_pending(struct timer_list *timer, unsigned long expires);
extern int timer_reduce(struct timer_list *timer, unsigned long expires);
extern void add_timer(struct timer_list *timer);
extern int try_to_del_timer_sync(struct timer_list *timer);
extern int timer_delete_sync(struct timer_list *timer);
extern int timer_delete(struct timer_list *timer);
extern int timer_shutdown_sync(struct timer_list *timer);
extern int timer_shutdown(struct timer_list *timer);














 1591
1591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









