







Iptables/Netfilter原理分析
Netfilter是Linux操作系统核心层内部的一个数据包处理模块,它具有如下功能:
1) 网络地址转换(Network Address Translate)
2) 数据包内容修改
3) 以及数据包过滤的防火墙功能
Netfilter平台中制定了五个数据包的挂载点(Hook Point,我们可以理解为回调函数点,数据包到达这些位置的时候会主动调用我们的函数,使我们有机会能在数据包路由的时候有机会改变它们的方向、内容),这5个挂载点分别是:
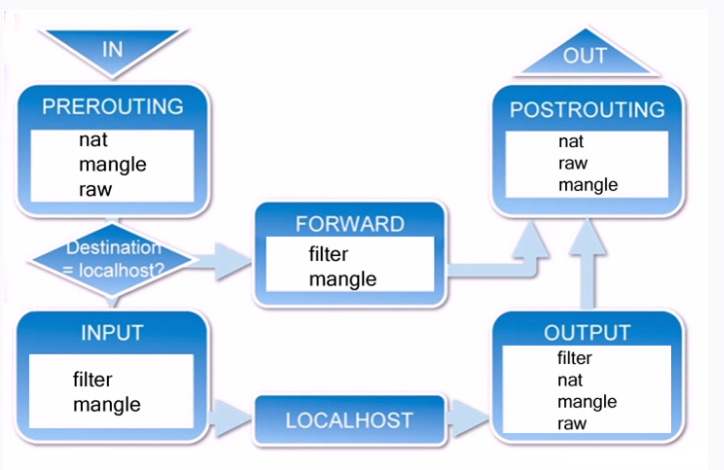
1) PRE_ROUTING
2) INPUT
3) OUTPUT
4) FORWARD
5) POST_ROUTING
iptables
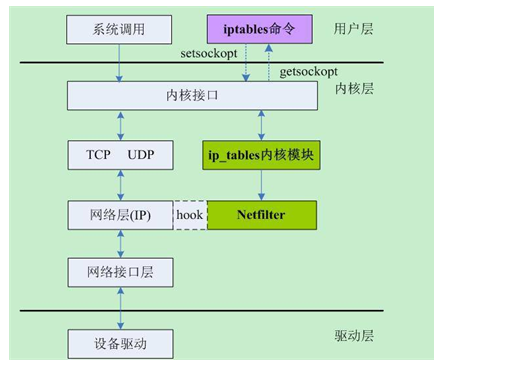
Netfilter所设置的规则是存放在内核内存中的,Iptables是一个应用层(Ring3)的应用程序,它通过Netfilter放出的接口来对存放在内核内存中的Xtables(Netfilter的配置表)进行修改
(这是一个典型的Ring3和Ring0配合的架构)
xtables
我们知道Netfilter是负责实际的数据流改变工作的内核模块,而Xtables就是它的规则配置文件,Netfilter依照Xtables的规则来运行,Iptables在应用层负责修改这个规则文件。
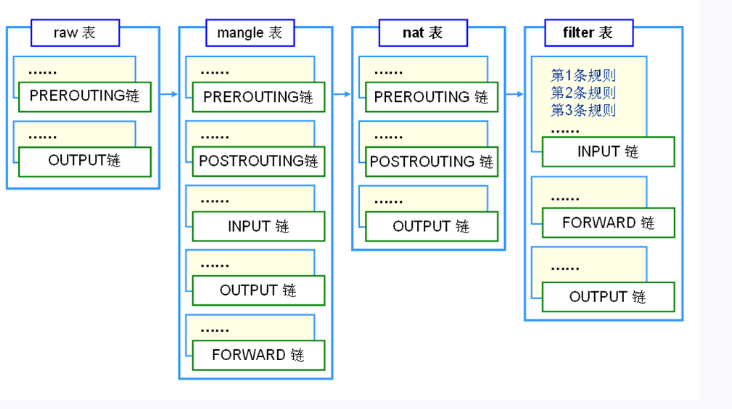
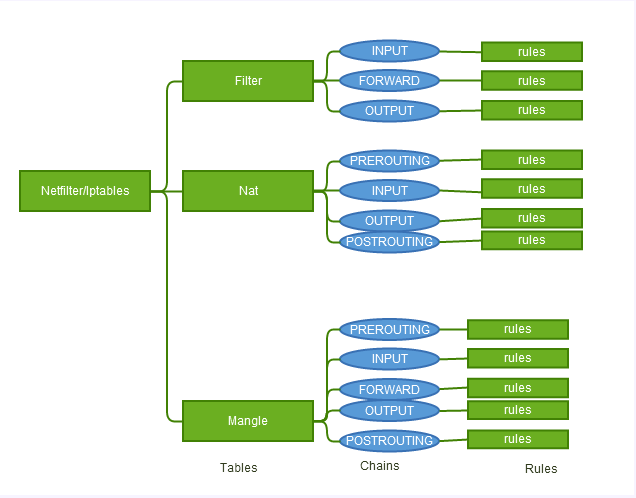
xtables由”表”、”链”、”规则rule”组成
- Filter(表)
filter表是专门过滤包的,内建三个链,可以毫无问题地对包进行DROP、LOG、ACCEPT和REJECT等操作
1) INPUT(链)
INPUT针对那些目的地是本地的包
1.1) 规则rule
..
2) FORWARD(链)
FORWARD链过滤所有不是本地产生的并且目的地不是本地(即本机只是负责转发)的包
2.1) 规则rule
..
3) OUTPUT(链)
OUTPUT是用来过滤所有本地生成的包
3.1) 规则rule
.. - Nat(表)
Nat表的主要用处是网络地址转换,即Network Address Translation,缩写为NAT。做过NAT操作的数据包的地址就被改变了,当然这种改变是根据我们的规则进行的。属于一个流的包(因为包
的大小限制导致数据可能会被分成多个数据包)只会经过这个表一次。如果第一个包被允许做NAT或Masqueraded,那么余下的包都会自动地被做相同的操作。也就是说,余下的包不会再通过这个表
,一个一个的被NAT,而是自动地完成
1) PREROUTING(链)
PREROUTING 链的作用是在包刚刚到达防火墙时改变它的目的地址
1.1) 规则rule
..
2) INPUT(链)
2.1) 规则rule
..
3) OUTPUT(链)
OUTPUT链改变本地产生的包的目的地址
3.1) 规则rule
..
4) POSTROUTING(链)
POSTROUTING链在包就要离开防火墙之前改变其源地址。
4.1) 规则rule
.. - Mangle(表)
这个表主要用来mangle数据包。我们可以改变不同的包及包 头的内容,比如 TTL,TOS或MARK。 注意MARK并没有真正地改动数据包,它只是在内核空间为包设了一个标记。防火墙内的其他的规
则或程序(如tc)可以使用这种标记对包进行过滤或高级路由。注意,mangle表不能做任何NAT,它只是改变数据包的TTL,TOS或MARK,而不是其源目地址。NAT必须在nat表中操作的。
1) PREROUTING(链)
PREROUTING在包进入防火墙之后、路由判断之前改变 包
1.1) 规则rule
..
2) INPUT(链)
INPUT在包被路由到本地之后,但在用户空间的程序看到它之前改变包
2.1) 规则rule
..
3) FORWARD(链)
FORWARD在最初的路由判断之后、最后一次更改包的目的之前mangle包
3.1) 规则rule
..
4) OUTPUT(链)
OUTPUT在确定包的目的之前更改数据包
4.1) 规则rule
..
5) POSTROUTING(链)
POSTROUTING是在所有路由判断之后
5.1) 规则rule
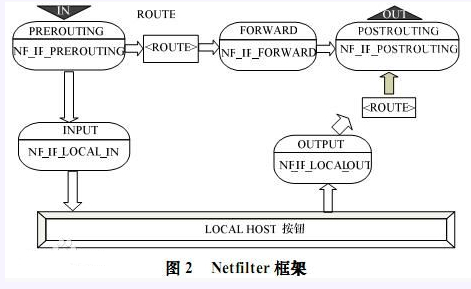
Netfilter的Hook点
Netfilter的架构就是在整个网络流程的若干位置放置了一些检测点(HOOK)(或者说是回调函数),而在每个检测点上登记(callback)了一些处理函数进行处理(如包过滤,NAT等,甚至可以是 用户自定义的功能)
NF_IP_PRE_ROUTING:
刚刚通过数据链路层解包,进入网络层的数据包通过此点(刚刚进行完版本号,校验
和等检测),目的地址转换在此点进行NF_IP_LOCAL_IN
经路由查找后,送往本机的通过此检查点,INPUT包过滤在此点进行NF_IP_FORWARD
要转发的包通过此检测点,FORWARD包过滤在此点进行NF_IP_POST_ROUTING
所有马上便要通过网络设备出去的包通过此检测点,内置的源地址转换功能(包括地址伪装)在此点进行NF_IP_LOCAL_OUT
本机进程发出的包通过此检测点,OUTPUT包过滤在此点进行
iptables/Netfilter的工作是针对网络的数据包进行修改的,所以,iptables/Netfilter在某种程度上可以算是一种网络层的路由器/防火墙
我们可以看到,通过”5个代表不同阶段的Hook点”、”表、链、规则”这种”松耦合”、”规则型”的结构,我们作为管理员可以获得最大程度的控制灵活性、可以有非常巨大的想象空间
Hooks
struct list_head nf_hooks[NFPROTO_NUMPROTO][NF_MAX_HOOKS]是其中核心的数据结构。nf_hooks的功能类似一个二维的函数指针数组。
nf_hooks数组的第一维是按照协议进行分类的,对于不同的协议有不同的hook点和hook函数,常见的协议包括ipv4,ipv6,arp,bridge等。
nf_hooks数组的第二维是按照hook点进行划分的,分为NF_INET_PRE_ROUTING,NF_INET_LOCAL_IN,NF_INET_FORWARD,NF_INET_LOCAL_OUT,NF_INET_POST_ROUTING等5个hook点,与iptables的5个链相对应。
nf_hooks数组中的每一个元素可以理解为一个函数指针链表的链表头。这个函数指针链表是一个有序链表,按照函数hook的优先级进行排序。iptables的4个表分别对应不同的优先级:NF_IP_PRI_RAW、NF_IP_PRI_MANGLE、NF_IP_PRI_NAT_DST /NF_IP_PRI_NAT_SRC、NF_IP_PRI_LAST等。iptables中的表的优先级就是通过有序链表的方式来实现的。
链表元素的实际的数据结构是struct nf_hook_ops,其核心的数据成员就是一个函数指针,还包含其他的一些属性。
struct nf_hook_ops
{
struct list_head list; //链表成员
/* User fills in from here down. */
nf_hookfn *hook; //钩子函数指针
struct module *owner;
int pf; //协议簇,对于ipv4而言,是PF_INET
int hooknum; //hook类型
int priority; //优先级
};Tabales
netfilter中提供了一系列的表(tables),每个表包含若干个链(chains),而每条链中包含由一条或若干条规则(rules),每一条规则都被用于数据包的检测。实际上netfilter是表的容器,表是链的容器,而链又是规则的容器。
相关的数据结构:
struct xt_table //表结构
{
struct list_head list;//表链
unsigned int valid_hooks;
struct xt_table_info *private;// iptable的数据区
struct module *me;
u_int8_t af; //协议簇
int priority; //优先级
const char name[XT_TABLE_MAXNAMELEN];// 表名,如"filter"、"nat"等,为了满足自动模块加载的设计,包含该表的模块应命名为iptable_'name'.o
};
struct ipt_table_info //表的实际数据结构
{
unsigned int size;//表大小
unsigned int number;//表中规则数
unsigned int initial_entries;//初识的规则数,用于模块计数
unsigned int hook_entry[NF_IP_NUMHOOKS];// 记录所影响的HOOK的规则入口相对于下面的entries变量的偏移量
unsigned int underflow[NF_IP_NUMHOOKS];//与hook_entry相对应的规则表上限偏移量,当无规则录入时,相应的hook_entry和underflow均为0
char entries[0] ____cacheline_aligned;//规则表入口
};下面的3种数据额结构是被填充到struct ipt_table_info的规则表(entries开始的)中的。
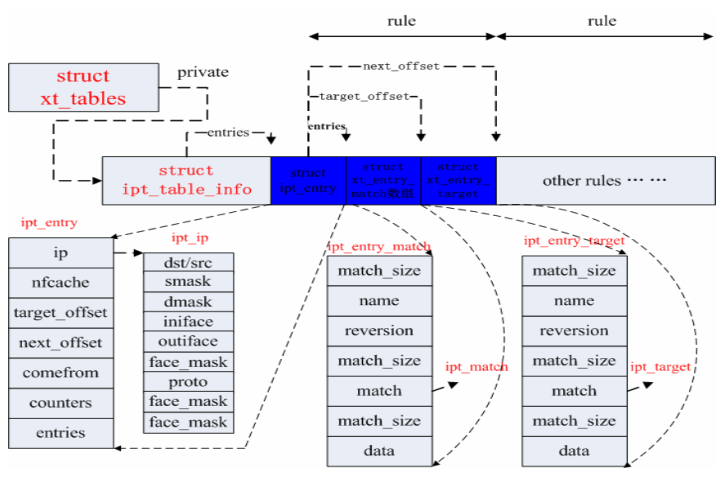
ipt_entry结构如下图所示,其成员ip指向结构ipt_ip,该结构主要保存规则中标准匹配的内容 (IP、mask、interface、proto等),target_offset的值等于ipt_entry的长度与 ipt_entry_matches的长度之和,next_offset的值等于规则中三个部分的长度之和。通过target_offset与 next_offset可以实现规则的遍历。
struct ipt_entry
{
struct ipt_ip ip;/* 所要匹配的报文的IP头信息 */
unsigned int nfcache;/* 位向量,标示本规则关心报文的什么部分,暂未使用 */
u_int16_t target_offset;/* target区的偏移,通常target区位于match区之后,而match区则在ipt_entry的末尾;初始化为sizeof(struct ipt_entry),即假定没有match */
u_int16_t next_offset;/* 下一条规则相对于本规则的偏移,也即本规则所用空间的总和,初始化为sizeof(struct ipt_entry)+sizeof(struct ipt_target),即没有match */
unsigned int comefrom;/* 规则返回点,标记调用本规则的HOOK号,可用于检查规则的有效性 */
struct ipt_counters counters;/* 记录该规则处理过的报文数和报文总字节数 */
unsigned char elems[0];/*target或者是match的起始位置 */
}ipt_entry_match主要保存规则中扩展匹配内容(tos、ttl、time等),其是 Netfilter中内核与用户态交互的关键数据结构,在其内核部分由一个函数指针指向一个ipt_match结构,该结构体中包含了对包做匹配的函数, 是真正对包做匹配的地方。ipt_entry_targe结构与ipt_entry_match结构很类似。
struct xt_entry_
union {
struct {
__u16 match_size;
char name[XT_EXTENSION_MAXNAMELEN];
__u8 revision;
} user;
struct {
__u16 match_size;
struct xt_match *match;
} kernel;
__u16 match_size;
} u;
unsigned char data[0];
};
struct xt_entry_target {
union {
struct {
__u16 target_size;
char name[XT_EXTENSION_MAXNAMELEN];
__u8 revision;
} user;
struct {
__u16 target_size;
struct xt_target *target;
} kernel;
__u16 target_size;
} u;
unsigned char data[0];
};上面各种数据结构是按照下图的形式进行关联的。这里被分成表、链、规则三级。
每个表(xt_tables)都有一个private指针指向一个ipt_table_info结构,在ipt_table_info结构之后紧接着的是是实际的规则。
从数据结构中看链结构不是很明显,但是规则是被封装在链中的。ipt_table_info结构中的hook_entry成员和underflow成员就是用于划分规则所在的链。
每个规则由一个ipt_entry结构,N个xt_entry_match结构和一个xt_entry_target结构组成。ipt_entry结构表示的是基本的匹配规则(协议、地址等),xt_entry_match结构表示的是扩展的匹配规则,xt_entry_target结构表示的是匹配之后的动作。
NetFilter的利用
由于netfilter在内核中预留了Hook点,因此可以通过加载模块的方式方便对其加以利用。下面代码可以在2.6.20上运行。
//nethook.c
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/netfilter.h>
#include <linux/netfilter_ipv4.h>
#include <linux/netdevice.h>
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/tcp.h>
static struct nf_hook_ops nfho;
unsigned int hook_func(unsigned int hooknum,
struct sk_buff **skb,
const struct net_device *in,
const struct net_device *out,
int (*okfn)(struct sk_buff *))
{
#ifdef BASE_TEST
return NF_DROP;
#endif
#ifdef INTF_TEST
if(strcmp(in->name,"eth0") == 0){
return NF_DROP;
}
#endif
#ifdef ADDR_TEST
static unsigned char *drop_ip = "/x0a/x08/x50/x6c";
struct sk_buff *sk = *skb;
if(sk->nh.iph->saddr == *(unsigned int *)drop_ip){
return NF_DROP;
}
#endif
#ifdef PORT_TEST
unsigned char *deny_port = "/x00/x19"; /* port 25 */
struct tcphdr *thead;
if (!skb )
return NF_ACCEPT;
if (!(skb->nh.iph))
return NF_ACCEPT;
if (skb->nh.iph->protocol != IPPROTO_TCP) {
return NF_ACCEPT;
}
thead = (struct tcphdr *)(skb->data +(skb->nh.iph->ihl * 4));
if ((thead->dest) == *(unsigned short *)deny_port) {
return NF_DROP;
}
#endif
return NF_ACCEPT;
}
static int __init init_nethook(void)
{
nfho.hook = hook_func;
nfho.hooknum = NF_IP_PRE_ROUTING;
nfho.pf = PF_INET;
nfho.priority = NF_IP_PRI_FIRST;
nf_register_hook(&nfho);
return 0;
}
static void __exit exit_nethook(void)
{
nf_unregister_hook(&nfho);
}
module_init(init_nethook);
module_exit(exit_nethook); Makefile:
obj-m = nethook.o
KVERSION = $(shell uname -r)
all:
make -C /lib/modules/$(KVERSION)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(KVERSION)/build M=$(PWD) clean
利用上述模块可以简单实现对地址、端口的过滤
Netfilter是由Rusty Russell提出的Linux 2.4内核防火墙框架,该框架既简洁又灵活,可实现安全策略应用中的许多功能,如数据包过滤、数据包处理、地址伪装、透明代理、动态网络地址转换(Network Address Translation,NAT),以及基于用户及媒体访问控制(Media Access Control,MAC)地址的过滤和基于状态的过滤、包速率限制等
Netfilter在内核中位置如下图所示:
Iptables/Netfilter的这些规则可以通过灵活组合,形成非常多的功能、涵盖各个方面,这一切都得益于它的优秀设计思想
Linux数据包路由原理
我们已经知道了Netfilter和Iptables的架构和作用,并且学习了控制Netfilter行为的Xtables表的结构,那么这个Xtables表是怎么在内核协议栈的数据包路由中起作用的呢?
网口数据包由底层的网卡NIC接收,通过数据链路层的解包之后(去除数据链路帧头),就进入了”TCP/IP协议栈(本质就是一个处理网络数据包的内核驱动)和Netfilter混合”的”数据包处理流程”中了。
数据包的接收、处理、转发流程构成一个有限状态向量机,经过一些列的内核处理函数、以及Netfilter Hook点,最后被转发、或者本次上层的应用程序消化掉
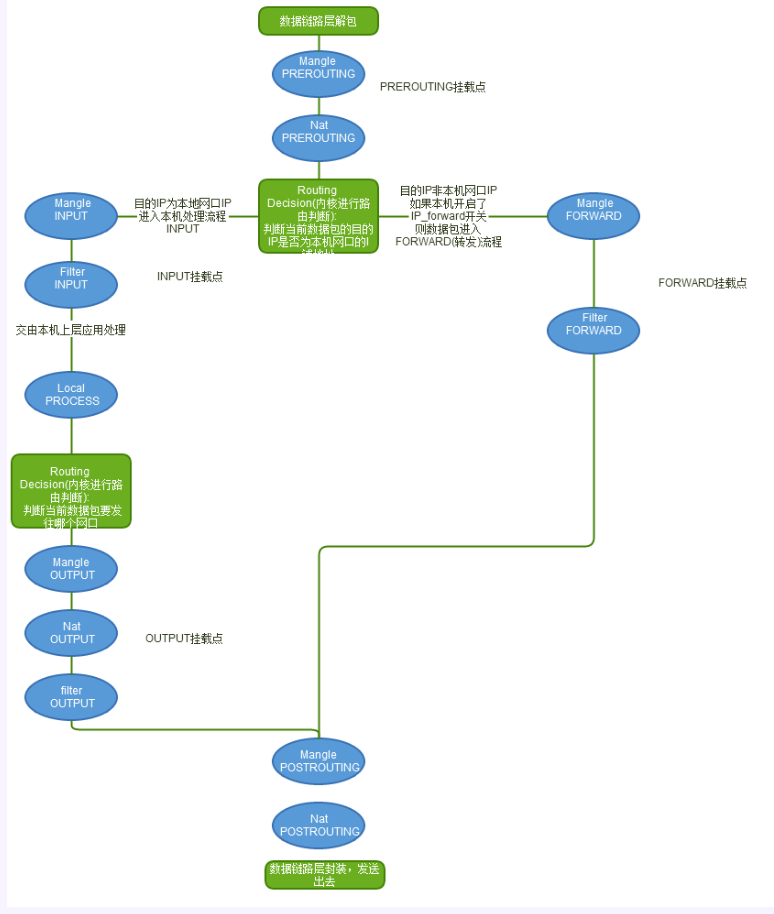
从这张图中,我们可以总结出以下规律:
- 当一个数据包进入网卡时,数据包首先进入PREROUTING链,在PREROUTING链中我们有机会修改数据包的DestIP(目的IP),然后内核的”路由模块”根据”数据包目的IP”以及”内核中的路由表”
判断是否需要转送出去(注意,这个时候数据包的DestIP有可能已经被我们修改过了) - 如果数据包就是进入本机的(即数据包的目的IP是本机的网口IP),数据包就会沿着图向下移动,到达INPUT链。数据包到达INPUT链后,任何进程都会收到它
- 本机上运行的程序也可以发送数据包,这些数据包经过OUTPUT链,然后到达POSTROTING链输出(注意,这个时候数据包的SrcIP有可能已经被我们修改过了)
- 如果数据包是要转发出去的(即目的IP地址不再当前子网中),且内核允许转发,数据包就会向右移动,经过FORWARD链,然后到达POSTROUTING链输出(选择对应子网的网口发送出去)
我们在写Iptables规则的时候,要时刻牢记这张路由次序图,根据所在Hook点的不同,灵活配置规则
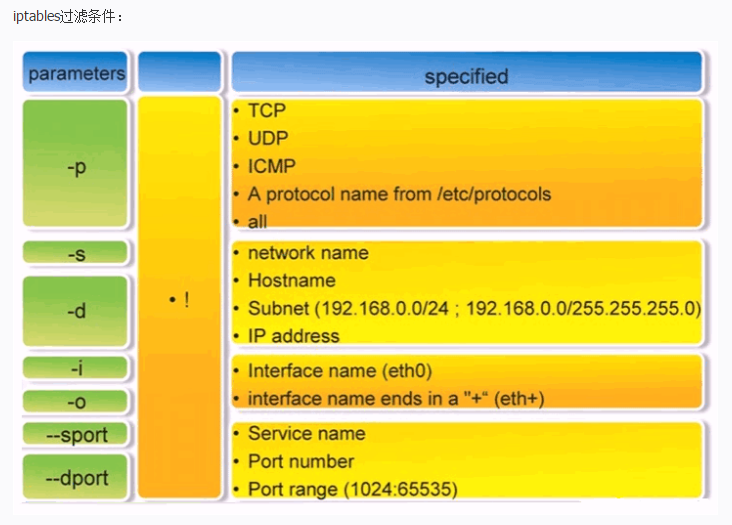
iptables规则编写原则
我们前面说过,使用Iptables是一个非常灵活的过程,我们在写规则的时候,一定要时刻牢记上面的这张”数据包路由图”,明白在5个Hook点,3种”表”分别所处的位置,以及结合在这个5个Hook点可以实现的功能,来理解规则。理解规则的原理比强记规则本身效果要好得多
1)提出需求
在正式编写Iptables规则之前,我们一定是有一个实现某个功能、目的的需求,我们必须先将它整理出来,为下一步抽象化作准备,这里我以我项目中的需求为例,大家在自己的实验中可以举一反三
1. 网口at0(10.0.0.1)是一个伪AP的网口,目标客户端连接到伪AP网口at0之后会发起DHCPDISCOVER过程,监听在at0上的DHCPD会进行回应,为客户端分配10.0.0.100的IP地址,并设置客户
端的默认网关为10.0.0.1(即at0的IP地址)、默认DNS服务器为10.0.0.1(即at0的IP地址)
2. 需要将网口at0(10.0.0.1)的入口流量牵引到真正连接外网的网卡接口eth0(192.168.159.254)上,做一个NAT服务
3. 对网口at0(10.0.0.1)的DHCP流量(目的端口67的广播数据包)予以放行,因为我们需要在伪AP所在的服务器上假设DHCP服务器
4. 对网口at0(10.0.0.1)的DNS流量(目的端口53)予以放行,因为我们需要在伪AP所在的服务器上假设DNS服务器
2) 逐步抽象化我们的需求
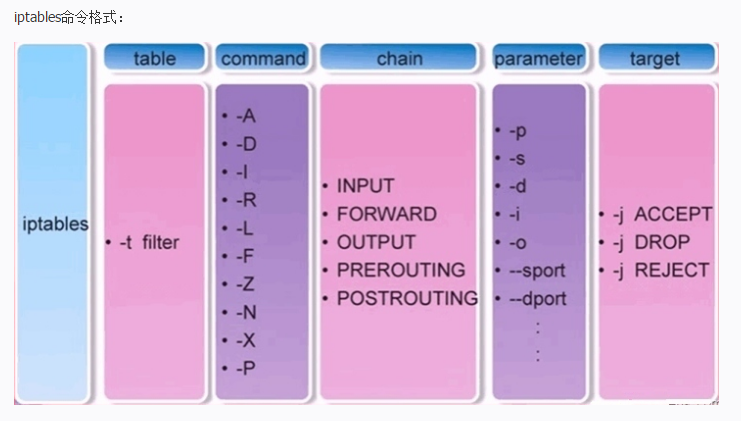
我们根据我们的需求进行抽象化,即用规则来抽象化描述我们的目的,在编写的过程中要注意不同的Hook点所能做的修改是不同的
//开启Linux路由转发开关,由于本机对数据包进行转发
echo “1” > /proc/sys/net/ipv4/ip_forward
//将客户端的HTTP流量进行NAT,改变数据包的SrcIP,注意,是在POSTROUTING(数据包即将发送出去之前进行修改)
iptables -t nat -A POSTROUTING -p tcp -s 10.0.0.0/24 –dport 80 -j SNAT –to-source 192.168.159.254
//将远程WEB服务器返回来的HTTP流量进行NAT,回引回客户端,注意,是在PREROUTING(数据包刚进入协议栈之后马上就修改)
iptables -t nat -A PREROUTING -p tcp -d 192.168.159.254 -j DNAT –to 10.0.0.100我们在DHCP服务器中指定客户端的默认DNS服务器是10.0.0.1(本机),即伪DNS,但我目前还没有在本机架设DNS,所以目前还需要将53号端口的DNS数据包NAT出去,牵引到谷歌的DNS: 8.8.8.8上去
iptables -t nat -A PREROUTING -p udp -s 10.0.0.0/24 –dport 53 -j DNAT –to 8.8.8.8
iptables -t nat -A POSTROUTING -p udp -s 10.0.0.0/24 –dport 53 -j SNAT –to-source 192.168.159.254
iptables -t nat -A PREROUTING -p udp -d 192.168.159.254 –sport 53 -j DNAT –to 10.0.0.100
iptables -t nat -A POSTROUTING -p udp -s 8.8.8.8 –sport 53 -j SNAT –to-source 10.0.0.1 














 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









