







这个系列是关于YOLO V5代码的学习和研究。作者在暑期研究期间,导师在布置了学习ResNet50相关内容之后的任务直接就是学习YOLO V5相关的知识。出于对于知识的一个完整性的尊重和重视,作者先花费了一周时间仔细研究并且横向对比了一下YOLO系列之前的最主要的三个版本:V1-V3,并且略读了一下YOLO系列的V4看看具体做了什么改进。关于这两段学习经历我都在之前发了文章概述,关于V1-4的研习链接如下:
为YOLO V5铺垫:一文看懂YOLO V1-V4的变化_vindicater的博客-CSDN博客
从之前的学习中作者对于YOLO系列大致的思路有了一些模糊的把握。比如对于YOLO模型的结构分成了几个部分:Backbone部分,Neck部分,和最后计算Anchor时候的部分,代码应该就是基于这几个内容进行编写的。
作者学习的代码版本:V6.0
但是实际研究代码的时候作者发现遇到了如下的一些问题:
1.ultralytics在YOLO V5的压缩包中实现了很多功能的使用,包括识别:Detect,也就是最常用的一个部分,更是包含了segmentation:物体分割,以及在识别出来之后进行归类:classify。内容全面的另一个表达方式就是庞大复杂,极其容易让初学者或者新进入这个圈子的学者不知从何开始,难以上手。
2.如果仅考虑YOLO实现对于物体识别的能力,实际上YOLO支持三种处理对象:图片、视频、和网络摄像头。此外对于实际鉴别的时候,YOLO模型还支持不同方式保存的权重:
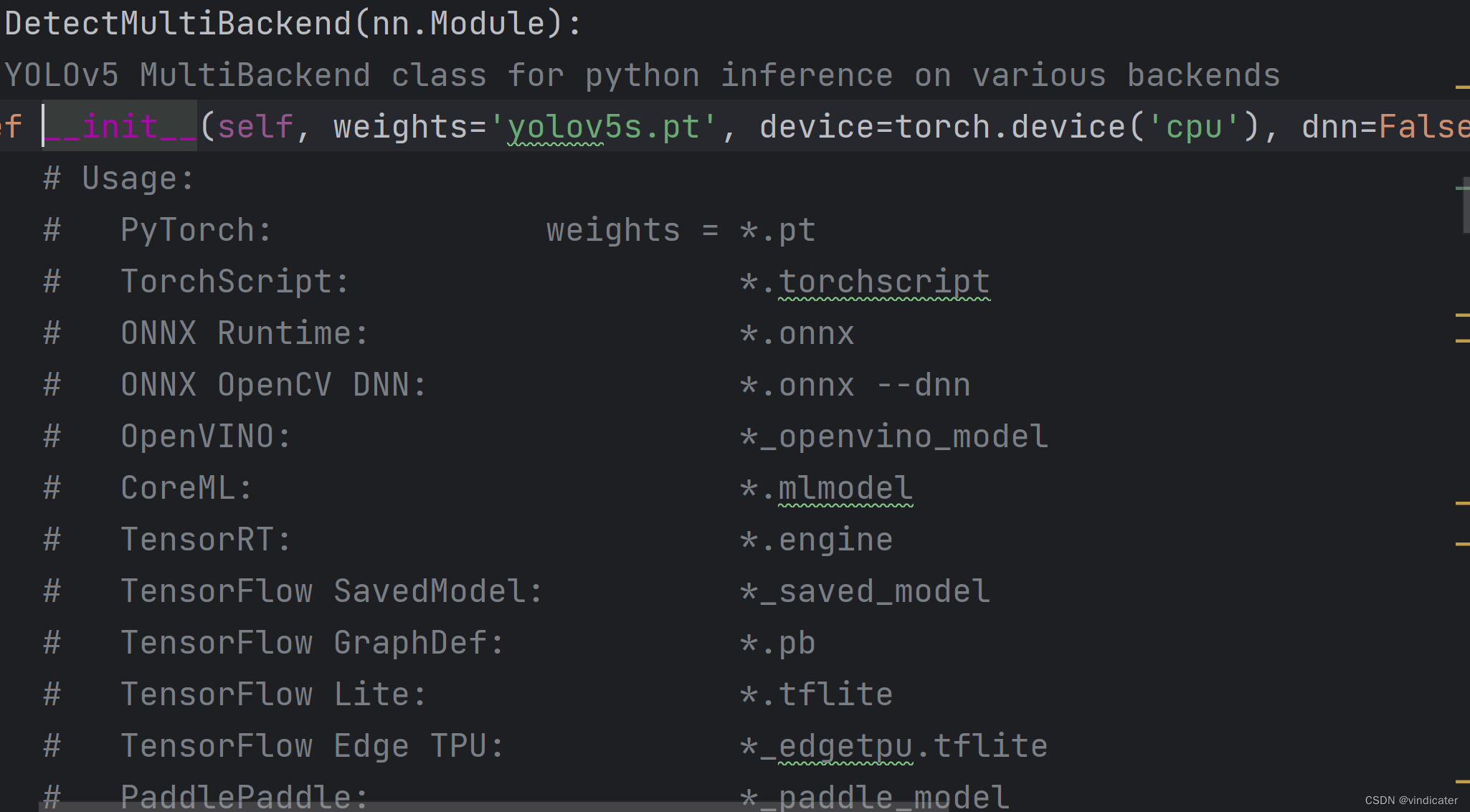
因此在代码内部考虑得周全导致了代码本身冗长,且变量相互交织,令读者从变量名直接了解其用途变得有些困难
3.作者使用公司中的网络在在线加载模型的预训练权重时候时常会出现拒绝访问的情况,但是压缩包中并没有给出,需要通过下载的方式得到预训练权重。
4.为了使得整个程序能够更有泛用性,读者能够更方便的加以修改,ultralytics把整个模型切成了很多模块。封装的操作在增加了便捷性的同时也一定会增加理解难度,因为整个程序的一条完整思路被分在了不同的py文件中。不通过综合理解的方式是无法复现出完整的思路的。
CSDN中的各位先辈们对于YOLO V5的各种教程很多都讲得相当清晰,也对于我第一次学习的时候起到了至关重要的作用。这里作者主推“满船清梦压星河HK”这位博主。
如果希望按照每一个py文件学习的方式,那么他的代码注释是解释的相当清楚的,这里贴上一个链接。
【YOLOV5-5.x 源码解读】loss.py_yolov5代码中loss.py详细解释_满船清梦压星河HK的博客-CSDN博客
而本系列文章的创新点是将通过一个个主题来解析YOLOV5代码,将散落的模块重新拼接加以解析,也希望我的这个专栏能够帮助后来的学习者,更好的学习清楚具体这个模型的哪个部分对应着哪些代码,而某些代码具体是用来做什么的,解决上手较大模型时手足无措的问题。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









