






一、前言
YOLO系列一直是最近几年机器视觉的炙手可热的项目之一,自从Joseph Redmon发表于CVPR2016夺得了当年的最佳论文之后,接下来机器视觉领域的学者研究专家蜂拥而至对于Joseph的YOLO框架进行继承和改善,创造出了YOLO V1-8的众多版本开源为大众使用。如今时代,动态物体识别的领域中最主要运用的版本就是YOLO V5。但是YOLO V5的内容是基于之前的YOLO进行修改完善的,因此只学习YOLO V5相关的内容似乎有些不太合理。事实上,从作者本人的经历来看,Joseph在前3个版本的YOLO之中所加入的元素撑起了整个YOLO的框架,而之后的V4 和V5做到的仅仅是在其上添砖加瓦,但是再难以在结构上做出什么创新性的调整,因此学习YOLO V1-3不仅不是浪费时间,其在梳理整个发展的时间线的基础上更是一步一步为YOLO V5的出现铺平着道路。本文将通过对于不同版本的YOLO模型的对比,仅从思想思路上给出对于YOLO V1-4的内容分析。就代码来说,作者下一篇博客将基于ultralytics发布的YOLO V5s的源码进行讲解。
二、总体介绍

简介&每一个版本的基础特性
三、细节对比
1.对比总览
表格如下:
| 序号 | 模块/代 | V1 | V2 | V3 | V4 |
| 1 | BackBone 网络架构 | Google Net | Darknet 19 | Darknet53 (Res残差模块) | CSP Darknet53 (CSP架构) |
| 2 | Neck部分 &输出形式 | 无特殊处理 一个特征矩阵 | 无特殊处理 一个特征矩阵 | 采用了FPN结构 三个特征矩阵(代表分辨率不同) | 采用了PAN结构 输出形式同前 |
| 3 | Anchor相关 | ||||
| 是否采用先验框(Anchor) 每个cell采用几个框 | 否 2预测框/cell | 是 5 预测框/cell 对应5 anchor | 是 3 预测框/cell 对应9Anchor/点 | 同 V3 | |
| 每一个预测框对应的参数数量 | 5(W,H,X,Y,C) | 25(WHXYC& Imagenet对应的20种class的概率) | 85(WHXYC&COCO数据集对应的80种class的概率) | 同左 | |
YOLO V1-3的具体变化
那么接下来将按照上面分画的三个大模块进行分析学习与解析。
2.BackBone网络架构上的区别:
V1 VS V2:最大的变化是增加了一个PassThrough 部分:
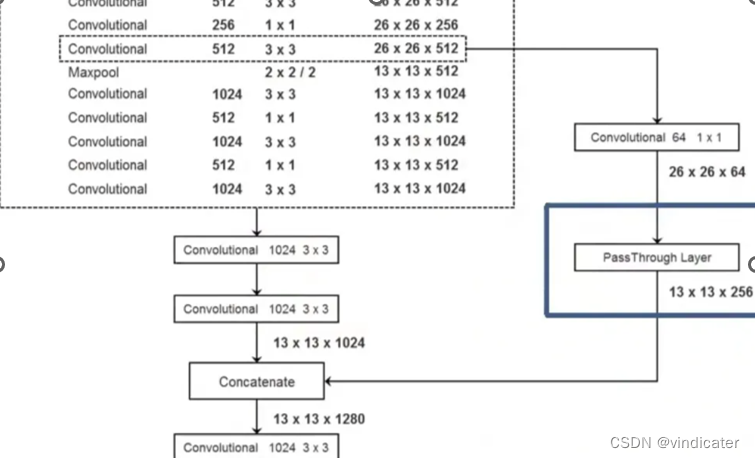
上图为YOLO V2的结构图,聚焦Passthrough层
从上面的网络结构中可以看出一点:Passthrough层是通过concatenation拼接的,拼接的操作实际上就是和残差结构的直接相加有着异曲同工之妙
Passthrough层的具体行为:
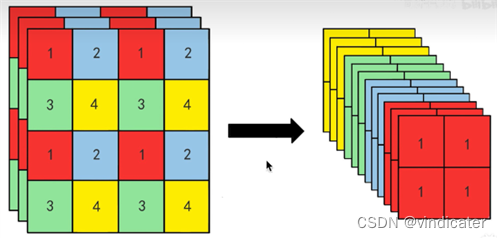
Passthrough层的优劣分析:
优点:通过类似于残差的结构,使得较高分辨率下的特征信息可以保留。
不足:仅仅采用了残差的结构但是没有采用残差块的形式,只有一层细粒度不够
V2 VS V3:Darknet 19 VS Darknet 53:
这一块并没有什么值得分析的内容,网络的加深带来了更好的效果。
V3 VS V4:增添了两个模块:CSP&SPP:
增添CSP和SPP这两个模块属于是trick,不过就实验结果来看属于较为有效的trick。
CSP模块简介:
论文中的CSP模块图
论文:[1911.11929] CSPNet: A New Backbone that can Enhance Learning Capability of CNN (arxiv.org)
CSP模块通过从一开始的矩阵中截下一部分保持原样拼在了经过处理的剩下的矩阵之后,可以说是同时保留了原样的一部分信息和处理后的信息。拼接完成之后通过一组CBR函数(convolution+batch normalization+ReLU)激活就得到了同时糅合了浅层内容(即被直接拼接的原矩阵的一部分)和深层内容(即经过卷积操作之后的原矩阵的另一部分)的输出结果。
SPP模块简介:

具体就是通过三种不同的池化,得到三个不同的结果拼接得到最终输出的内容。好处是maxpool采用的kernel size的不同尺寸分别对应着三个不同的范围,因此可以看到不同尺度的信息,最后得到的结果融合了以上得到的这些,对于模型的效果和精度有所提升。
3.Neck部分
V1,V2 vs V3,V4:输出矩阵数量的变化
变化图示:

V1和V2的输出结果,仅仅只有一个矩阵(作者:铁心核桃)
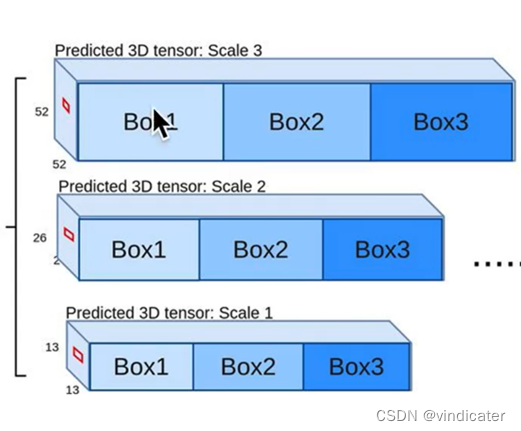
V3和V4对应的输出结果,可以看出分成了三个不同的矩阵
矩阵数量发生改变的好处:
不同大小的矩阵也就意味着同一图片在被分割成不同大小的方格时,每一种分割方式对应分割出的图片其均可以用来产生预测框。被分割地较粗的图片可以用来定位识别较大的物体,被分割地较细密的图片可以用来识别较小的物体的,这样分成三层有效弥补了前版本难以识别小物体的缺点。
图示如下:

V3 vs V4: FPN结构&PAN结构
FPN:
论文网址:[1612.03144] Feature Pyramid Networks for Object Detection (arxiv.org)
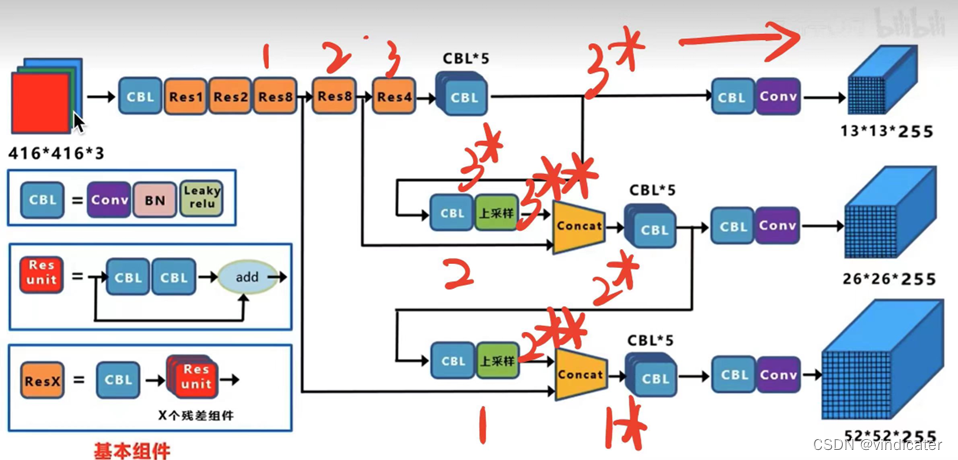
具体的操作正如上图所画的一样,输出的三个分别是1*,2*,3*这三个不同的结果,而其中的1*和2*分别融合进了2**和3**,每一个大小的矩阵都采取了别的感受野的矩阵的一些信息使得每一个矩阵中包含的信息更加全面。
PAN:
论文:[1803.01534v2] Path Aggregation Network for Instance Segmentation (arxiv.org)
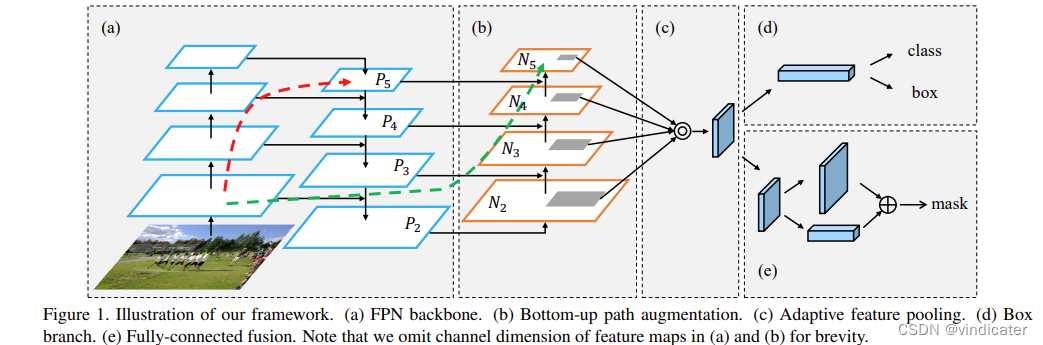
论文中的图示
正如图上所画的一样,这个结构像是一个正金字塔和一个倒金字塔相拼接得到的结果。每一步都揉合了之前的内容和上一层的内容使得得到的结果信息更加丰富。这两个也都是提升效果的trick,在实验中效果较好。
4.Anchor相关
(1)是否采用Anchor&Anchor的数量
V2 VS V1:是否采用Anchor
采用Anchor的好处:
大部分的物体的大小都是有规律的,则V2中先确定Anchor框再以此为基础微调后生成预测框相比于V1中直接预测预测框的对角顶点的坐标要更稳定,可以减少较多的计算量。
获取Anchor的数量以及大小:

聚类得到的结果
采取类K-means算法,通过在训练集上聚类来取得具体应该设置几个Anchor。
V2 VS V3:采用了多少个Anchor:
实际情况介绍:
对于V2使用了5个Anchor以及对于V3每一个方格使用了三个Anchor,但实际上等效的是9个
对于Anchor而言,数量越多,平均IOU会越大,效果也会越好,但是相应的会带来更多的计算量
对于V3来说:一个点,若其不在边界上,会也只有可能属于三个不同的方格,且这三个方格一定属于不同的分割方式。于是如果一个方格有K个对应的预测框,则等效于每一个点有3K个包含其的预测框。同样综合考虑之后,决定令K=3。

取自书本《深度学习之Pytorch物体检测实战》,作者:董洪义
(2)采用anchor框后对于预测框的定位:
YOLO V2,V3 vs V1:预测偏移量替代了直接预测对角坐标

YOLO V2&V3对应的计算公式

知乎用户luckily的图片
2.为何不直接加上偏移量呢?
Sigmoid函数目的:将横向与纵向的坐标偏移值都用sigmoid函数限制在0-1中,即将预测框的中心点限制在格子中,在开始训练时更容易达到应该处在的位置
3.Sigmoid函数带来的问题:
对于sigmoid函数,当标注框的中心点落在方格的边缘上时,对应的sigmoid(𝑡x)应该等于0,但是实际上左边的函数无法取0,这样就无法判断应该由哪个方格的预测框负责拟合。
因此,有了下面的改变:
YOLO V4 vs V2,3:计算位置的公式的改变:

图片原作者:CSDN 太阳花的小绿豆
好处:
这样的操作下,妥善地解决了之前标注框的中心点落在边缘上的问题:在这种情况下距离方格左上角的距离在0-1之间,见左边的函数曲线图,这是可以取到的。
(3)采用Anchor后对于正负样本的判断
V2 :
对于标注框的中心点所在的方格,其产生的五个预测框和标注框IOU最大的框判定为正样本,其余的判定为负样本
V3:
1.将九个确定的Anchor框的左上角和标注框的左上角对齐,算出这九个框和标注框的IOU
2.得到IOU最大的框对应的分割方式,以及通过分割方式唯一确定标注框中心点对应的方格
3.在2确定了两个最重要的参数的情况下,唯一确定了三个预测框,计算这三个预测框和标注框的IOU
4.判断: IOU最大的被标注为正样本并用来拟合这个标注框;和标注框IOU大于某个阈值K但不是最大值的被标注为中性样本直接忽略,小于K的判定为负样本。其余的六个可以用数学运算不严谨的说明一定都是负样本
V4:
对于 V4而言,主体思想跟之前的一致,但是由于现在的函数的取值范围已经不局限于(0,1)中,这就导致了现在一个预测框可以移到相邻的框中确定其Anchor,因此,作者选择增加正样本的数量:具体方式如左图:除非中心点距离边界的位置是0.5,否则每一个中心点其周围能确定三个正样本

演示的图片来自B站up主
(4)采用Anchor后损失函数的不同
V1:正样本的位置位置偏差+正样本的置信度偏差+负样本的置信度偏差
V2-V4:在上面的基础上增加了下面一项,其目的是为了尽快让预测框接近Anchor框


不同的计算方式:
比如在V1V2的损失函数的计算中使用的全都是MSE的计算方式,对于V3的损失函数,采用的主要是BCE。事实上除了正样本位置误差用的是MSE计算方式之外,别的误差用的都是BCE误差。
四、总结
YOLO系列的主要变化的来源都是Joseph做出来的,对于V4 的推出,肯定可以说是提升,但是只能说是一些修补而不再有像1-2的时候加入Anchor和Passthrough,2-3时采用了多个结果矩阵这样的从根本上的变化了。所以其实最重要的是吃透YOLO V1-3的所有想法,这些会对于YOLOV5的了解和学习有着非常大的帮助。
都看到这里了不点个赞关注一下嘛awa55555















 1097
1097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









