







前言
上一篇文章中,作者主要聚焦于前线推理,也就是forward的部分,并解决了对于调整模型结构的一个重要问题:应该在哪里调整?如何添加使用新的网络层?对于希望利用YOLO V5的框架改进得到自己的模型的初学者指明了一条道路。本文将致力于解释另一部分问题:在何处能修改反向传播相关参数以达到更好的效果呢?关于这一部分,问题导向可能不在适用于讲清楚整个模块,于是作者决定采用先梳理整个框架,最后一个部分中再根据前文的内容获得问题的答案。
Part 1:对于反向传播内容的概述(总体概述)
产出结果:
Loss:经过损失函数计算出来的损失值
Loss_items:把三个损失值拼接在一起返回
loss, loss_items = compute_loss(pred, targets.to(device))函数结构:
Step 1:将标注框加载于图片上以便后续能进行计算损失函数
对应函数:build_targets()
产出结果:tcls: target的class类别数组;tbox: target的预测框的whxy信息;indices: target是针对于这一批的第几张图片而言的;anchors: 用来拟合target的anchor框在当前分辨率下的序号。
tcls, tbox, indices, anchors = self.build_targets(p, targets)Step 2:利用加载出来的target的信息计算多种损失
对应函数:bbox_iou,BCEcls,BCEobj
产出结果:loss:单张图片对应的平均损失值
Part 2 细读build_target函数部分
Step1:将targets,也就是yaml中的标注内容加载到图片
(1)对于targets文件进行维度的扩充
对应代码:
ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices直观效果:(178,6)变成了(3,178,7)

分析:
增添的最后一列是用来模拟这个target框的anchor框的序号(0-2)
增添的第一个维度中的3对应的是某一个分辨率大小下的三个对应的Anchor框。这里给预测框增加了一个维度实际上是利用了枚举的一个思想,现将所有情况列举出来,后续经过判断筛选出合适的留存下来,得到问题“对于某个标注框,应该使用哪个预测框来对应地预测它?”的答案。
(2)把targets文件中的比例换算成在不同分辨率下的实际坐标
之前在数据集那一篇文章中提到,在数据集中的标注框的位置是通过比例的形式储存的,因此一定是需要一段代码将比例转化成实际的位置信息。
对应代码:
gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
# 从上一行中的3232就是对应的长宽的值,那么这里的gains的形式就是[1,1,80,80,80,80,1]这保证了对于前面的矩阵的样子即最后那一列表示序号的不会被扩大而中间四个表示坐标的内容会按照被缩放的大小而还原到这张图上
# Match targets to anchors
t = targets * gain # shape(3,n,7)分析:
1.gain的第二位到第六位替换成了这个分辨率的长和宽的对应格数
2.把gain作为一个因子和targets进行矩阵乘法,这样得到的t的第2-6的位置就是在当下的网格坐标下实际坐标了。
Step2:根据处理后的targets得到应该保留哪些内容
对应代码:
r = t[..., 4:6] / anchors[:, None] # wh ratio 这里得到的是预测框长宽和Anchor框长宽的比值
j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare 第一步,对于上面的比值,求自己和倒数的最大值,然后把边长比值最大的作为阈值,如果最大的大于我的要求那就忽略,得到确切使用的Anchor组
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter从结果回头推得应该取哪个分析:
行1:计算得到targets框和anchor框长宽对应的比值。
行2:对于长宽的比值,取得其最大值与阈值相比较,满足小于阈值这个条件的将其索引保存在j数组中。
行3:通过刚刚得到的j数组可以把t做一个缩减。
结果:得到可能用来预测当前标注框的anchor框。
Step3:通过target框中心判断用来预测该target框的方格坐标
对应代码:
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1 < g) & (gxy > 1)).T #通过结果判断具体接近于身边哪些方格,比如上下左右这些
l, m = ((gxi % 1 < g) & (gxi > 1)).T #作用同上
j = torch.stack((torch.ones_like(j), j, k, l, m))#使用上面的jklm得到的参数判断到底距离哪个框会比较近,得到一个序号的集合
t = t.repeat((5, 1, 1))[j]#使用上面的j序号组确定保留哪些对应的Anchor框
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
分析:
行1,2:记录数据类型是左上角的坐标,这里将其转换为中心点的坐标。
行3,4:判断具体是使用哪个方格预测,这四个参数是四个数组分别对应预测框的中心点所在方格的上下左右是否是被用来拟合这个标注框
行5:将行3,4组合成一个数组:第一个元素是中间的格子设定为全True,其余为上下左右,取决于上面的判断
行6:将t这个左边得到的anchor框的数据复制五次,利用刚判断得到的j来筛选出合适的数据。
行7:首先创造一个和预测框一个维度的全零矩阵(125,2),然后再加上off对应着坐标偏移量(5,125,2),最后再用j做一个筛选(643,7)
off矩阵对应的设置内容:
off = torch.tensor(
[
[0, 0],
[1, 0],
[0, 1],
[-1, 0],
[0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
],
device=self.device).float() * g # offsets重点强调:
在之前的YOLO V1-4的泛介绍之中提到了YOLO V4采用了一个很奇特的机制,认可用多个相邻方格所产生的Anchor框同时作为可以用来预测标注框的正样本。
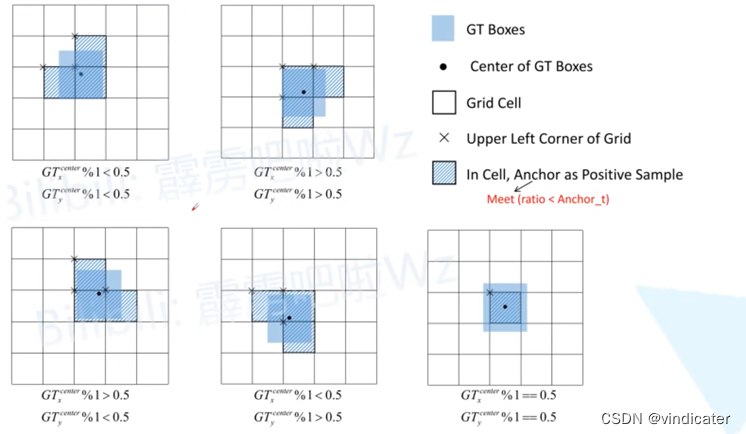
如图,若想详细了解请移步文章:为YOLO V5铺垫:一文看懂YOLO V1-V4的变化_vindicater的博客-CSDN博客
在上面的代码解析中,就很清楚得展现出YOLO V5的作者也同样采纳了这样的机制。
注意:行6本身得到的结果是无法看出到底对应的是哪些方格的。但是有了行7之后,行7是通过同样的j得到的偏移量,所以从行6获得的标注框对应的方格坐标再加上偏移量之后便可得到具体是哪个方格用来拟合标注框
Step4:得到输出结果
(1)得到具体参数:
对应代码:
bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
gij = (gxy - offsets).long()#利用offset中的顺序和gxy确定用来预测的方格的坐标(中心点的坐标)
gi, gj = gij.T # grid indices参数介绍
把t拆分出来:
b:当前标注框对应图像是这个batch的第几张
c:当前标注框中物体的种类对应序号
gxy:当前标注框中心点的xy坐标
gwh:当前标注框的长宽
a:当前标注框对应用来拟合的anchor的编号
gij:通过gxy减去调整的距离取整的方式得到用来预测这个标注框的方格的坐标
gi,gj:将gij这个二维数组拆开,分别对应xy坐标
![]()
(2)将刚刚得到的参数打包return:
对应代码:
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image在batch中的位置, anchor序号, grid的xy坐标
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
anch.append(anchors[a]) # anchors最匹配的
tcls.append(c) # class参数详解:
Indice:包含信息:b,a,gj,gi
tbox:中心点的偏移量(gxy-gij),gwh
anch:每一个确定选取拟合标注框的anchor的序号
tcls:class:每一个拟合标注框的框赢预测出的种类
至此,我们已经得到了要返回的所有内容:应该用来拟合标注框的所有预测框的信息(作用的图片的序号,方格的坐标,应该用的anchor的序号,对应的标注框的长宽坐标,内容物的类别信息),分别分布于以上的四个返回值之中。build_targets函数结束。
Part3:细读compute_loss函数部分:
参数相关分析:
函数目标:
Lbox:预测框位置损失;Lobj:物体置信度损失;Lcls:内容分类损失
已经拥有的参数:
标注框相关:Tbox,tcls,indices,anchors
预测框相关:predict得到的矩阵(可分离的参数:xywh,obj数据,80种物种对应的可能性)
还需要拥有的参数:
Tobj:标注框根据IOU设定的置信概率
具体推进步骤:
Step1:从pred中读出预测框对应的必要参数:pxy, pwh, pcls(先通过枚举分离出一层的一批矩阵然后读取)
对应代码:
pxy, pwh, _, pcls = pi[b, a, gj, gi].split((2, 2, 1, self.nc), 1)pi[b, a, gj, gi]的意思是pi这个矩阵中对应着batch中第b张图片在(gi,gj)这个坐标格上anchor[a]对应的参数
Step2:直接计算lbox
对应代码:
pxy = pxy.sigmoid() * 2 - 0.5
pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
lbox += (1.0 - iou).mean() # iou loss将pxy, pwh经过处理后拼接,形成和tbox[i]一样形式的pbox。带入bbox_iou计算就得到了损失函数的结果(使用的是CIOU)
Step3:直接计算lcls
对应代码:
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(pcls, self.cn, device=self.device) # targets
t[range(n), tcls[i]] = self.cp
# 对于每一个识别出来的object其对应的种类的分类概率定为1
lcls += self.BCEcls(pcls, t) # BCE此处的t令每一个预测框对应的种类概率都是1,其余全部为0。将t与pcls带入BCEcls计算即得到结果。
Step4.1:先计算tobj
对应代码:
iou = iou.detach().clamp(0).type(tobj.dtype)# 把所有小于0的置为0 有了detach之后这个tensor的梯度设为没有且不能回复,设置了之后反向传播就会到这里停止
if self.sort_obj_iou:
# 这里对iou进行排序在做一个优化:当一个正样本出现多个GT的情况也就是同一个grid中有两个gt(密集型且形状差不多物体)
# There maybe several GTs match the same anchor when calculate ComputeLoss in the scene with dense targets
j = iou.argsort()
b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
if self.gr < 1:
iou = (1.0 - self.gr) + self.gr * iou
tobj[b, a, gj, gi] = iou # iou ratioTobj的计算方法是使用预测框和标注框的IOU当做标准的置信度
Step4.2:再计算lobj
具体代码:
obji = self.BCEobj(pi[..., 4], tobj)
# 计算置信度损失
lobj += obji * self.balance[i] # obj loss将tobj和pobj带入BCEobj的计算公式即得到结果。
结束
至此compute_loss函数整体结束
返回代码:
return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()将前面得到的三个损失值相加取平均数就得到了对应的单位损失函数值,由于考虑到所有都是平均值,需要乘上batch_size来得到损失函数值
Part4:收尾&回答问题
根据得到的损失值调用优化器反向传播:
代码展示:
scaler.scale(loss).backward()
# Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
if ni - last_opt_step >= accumulate:
scaler.unscale_(optimizer) # unscale gradients
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0) # clip gradients
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni至此一整个Batch中的训练操作已经完成
问题回答:
1.应该如何通过改变损失函数的方式调整模型?
回答:在loss.py中的compute_loss函数调整需要选取的损失函数,或者在loss函数中添加新的损失函数的计算方式。
2.如何改变优化器?
如上图,这里调用的是optimizer,所以应该做的是在一开始的命令行中确定应该使用哪个优化器。
后记
本文主要关注了损失函数的计算方式和优化器反向传播的部分。事实上,本文和上一篇文章在一起解析了整个模型在训练一个Batch的过程中具体进行了什么样的操作,每一部分代码究竟有什么意义。由于两篇文章合在一起将突破万字,作者这里选择将其拆分成两个部分进行讲解,希望能对于初学者理解YOLO V5的模型主体部分将有所帮助。















 2632
2632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









