







前言
对于任何一个模型来说,程序员在上手使用或是学习的过程中都会首先面对同样一些问题:这个负载的模型是如何读入训练集的?读入的训练集中的图片是以一种什么形式存储?读入的图片尺寸是否有要求,尺寸是否需要完全一致?
对应于YOLO V5这个模型,以上问题变得更加复杂:从之前YOLO V1-4的经验我们可以知道,对于训练集,需要人工标注物体所在的区域和种类。那么YOLO V5这样的一个模型需要的是什么样的训练集输入形式便愈加复杂。下面本文将首先从数据集的形式来一一解析上面提出的问题
问题一、数据集应该是什么样的呢?(序言:数据集的结构)
1.数据集的位置
如图所示,应该放置在和YOLO v5的源代码文件夹的相同目录下:
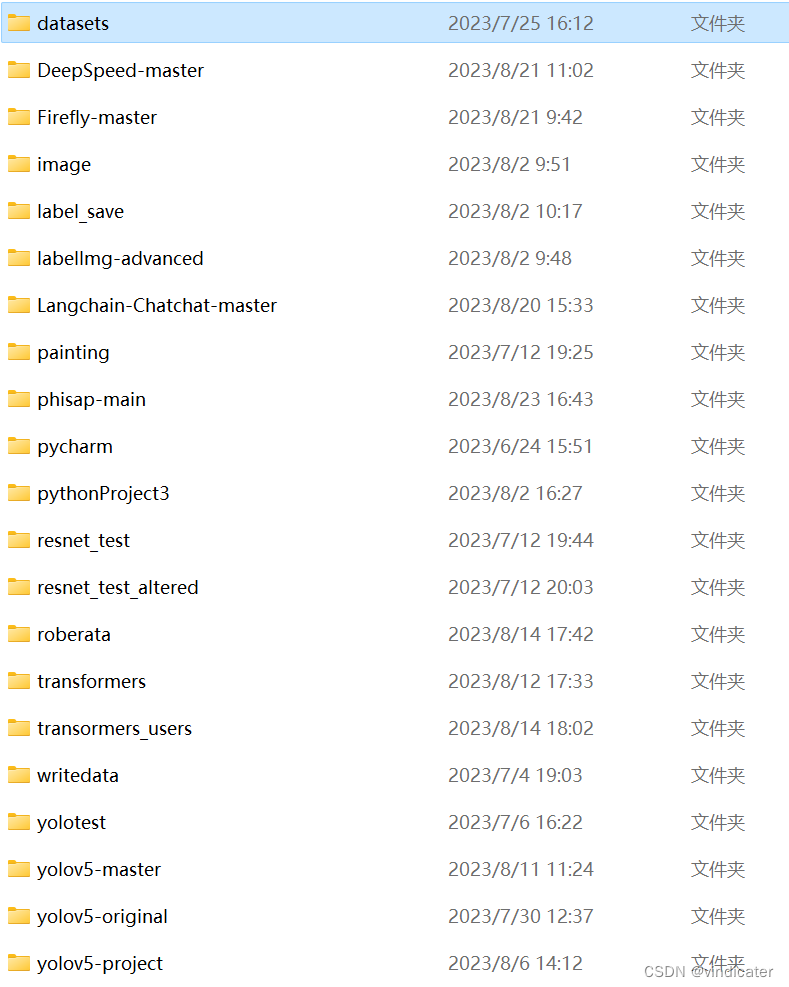
在程序中地址default写的是datasets这样一个文件夹之中,这个位置可以加以修改,修改方式见后文的yaml模块。
2.数据集的结构
数据集应该由什么组成呢?

如图:其中应该有两个文件夹,Images文件夹负责图片,而labels文件夹负责标签
Images
Images文件中有两个组成部分,一个是负责训练用的图片集,另一个是负责验证的图片集:
其中每一个文件夹中都是标有序号的图片
如图是我自己做的一个小的数据集:coco_test:采取了coco数据集中的1w张图片用于训练
Labels:
在label的文件夹中,整体的内容和上面的类似,如果该数据集已经被用于训练过,则会出现两个cache文件
cache文件
如果从云端下载的coco或者coco128,那么会在包中就有这两个文件。但是实际上,这两个文件的意义在于省去程序再读取一次train文件的时间,如果程序读取的时候没有的话,会自动生成!所以不用担心。
# Check cache
self.label_files = img2label_paths(self.im_files) # labels
cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache')
try:
cache, exists = np.load(cache_path, allow_pickle=True).item(), True # load dict
assert cache['version'] == self.cache_version # matches current version
assert cache['hash'] == get_hash(self.label_files + self.im_files) # identical hash
except Exception:
cache, exists = self.cache_labels(cache_path, prefix), False # run cache ops代码位置:dataloaders.py中LoadImagesAndLabels类的构造函数
def cache_labels(self, path=Path('./labels.cache'), prefix=''):
# Cache dataset labels, check images and read shapes代码位置:dataloaders.py中LoadImagesAndLabels类的成员函数
Labels文件夹中的内容:
形式:txt
内容:如图:

1.文件名字是Labels对应的图片的序号
2.第一个数字对应的是识别出的物体的类别编号,编号对应的种类书写在yaml文件之中
3.后面这四个数字是图片中物体的相对位置,分别是左上角和右下角的相对坐标(将长宽置为一的情况下等比例缩小得到的坐标值)
4.间隔使用的是空格,不同的框信息换行
3.数据集的直接读取媒介:xx.yaml
(1)、xx.yaml的位置
代码的文件夹中的data文件夹
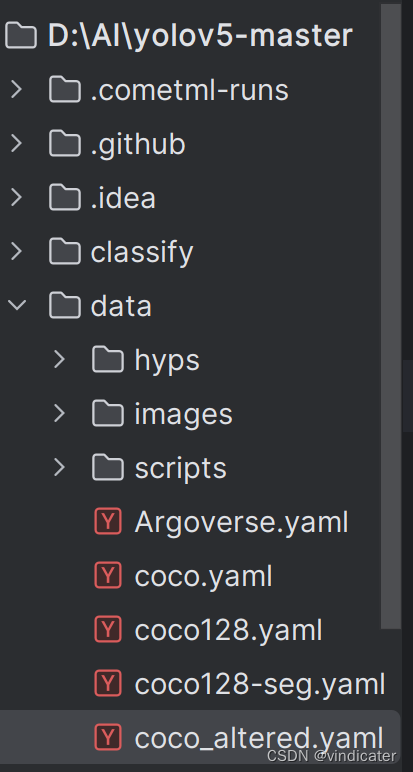
(2)、xx.yaml中的内容
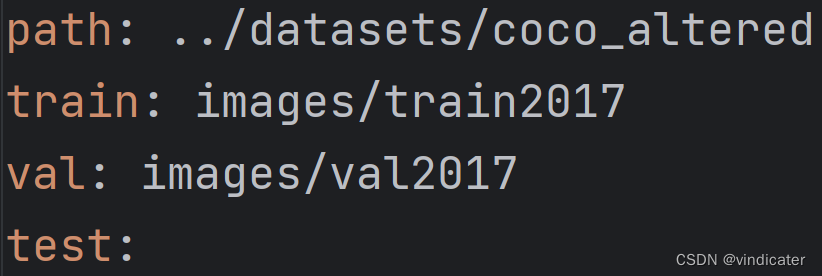
第一部分:测试集,验证集和可能有的test集合的位置:
第二部分:类别信息:

如图,用数字对于识别物体的种类标号,记录于names栏下面。
实际上对于类似于coco.yaml中,还有一个download参数,目的是告诉计算机如何下载数据集,但是由于本文的主要目的是搭建自己的数据集这一块就不给出详解了,只给出关于download部分在代码中的读取位置和相应的处理方式:
读取位置:general.py中的check_dataset函数之中
处理方式:
| 不同情况/download不同内容 | |
| 缺少数据集并且发现没有download内容或者选择不自动下载 | |
| 如果download内容只是一个下载网址: | |
| 如果download后面跟的是一整段代码那么就用exec函数执行安装结果 | |
可以从上面的表格中选择合适的方式从线上获得数据集。
问题二、数据集是如何读入模型之中的?(主体:对于模型框架的部分解读)
前言
数据读入一般是指把图片的地址转化成图片的信息矩阵。在YOLOV5中的读入分成了三个部分,分别对应着下面的Step1,Step2,Step3这样三个内容
Step 1:从opt.data到data_dict(图片以文件夹地址或者txt形式被读取进入模型中)
1.通过命令行读入的数据:opt
| 输入文件汇总 | 内容 |
| opt:opt.yaml | 仅出现在resume=true的时候,从上次保存的文件夹中恢复上次opt指令 否则就是从命令行读取的结果 |
| weights:last.pt(resume) yolov5s.pt(default) | 权重文件,如果是从头开始训练则是初始化的权重,如果resume是加载上次的参数内容 |
| cfg:yolov5s.yaml | Parameters: nc; depth&weight multiple; anchors size Backbone&head structure |
| data:coco.yaml | 数据相关内容: 至少是4类:path;train;val;names test, download(optional) |
| hyp:hyp.yaml(resume) hyp.scratch_low.yaml(default) | 超参数:在程序运行过程中不会进行更新的一些参数,比如lr等等参数 |
以上的命令行中读入的内容将会被保存在opt.data之中,其中就包括和数据集相关的,data的地址:coco.yaml的读取路径。
2.在main函数之中对于一些参数进行处理,准备传给train函数进行训练:
| 改变的参数信息 | 发生的改变 | 改变的位置 |
| Path, Train, Val, Test | 从根目录下的路径变成绝对路径 | general.py中的check_dataset()采用resolve() |
| nc | 新增 | general.py中的check_dataset() |
| __len__ | +=1 | 由于多了一个参数自动做出改变 |
| download | 如果原处不存在该数据集,则进行下载 | 见前 |
3.train函数中采用loggers类的构造函数与remote_dataset函数将xx.yaml读入模型之中
代码:
data_dict = None
if RANK in {-1, 0}:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
# 定义了一个Logger函数来执行上述操作
# Register actions
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# 把字符串和方法进行绑定
# Process custom dataset artifact link
data_dict = loggers.remote_dataset读入的结果:

至此,xx.yaml已经被读入进了程序之中。可以看到,到这里程序中已经录入了文件的绝对位置
Step 2:从train_path中获得datatset和train_loader(图片以每一张的形式储存到模型中)
这一段操作的对应代码在train.py中的中间位置,调用了dataloaders.py中的create_dataloader函数
实际上来说,train_loader的得到的基础是dataset:得到了dataset之后使用系统的Dataloader函数就可以得到。因此,这里主要聚焦dataset的取得过程。
dataset构造方式如下代码:
dataset = LoadImagesAndLabels(
path,
imgsz,
batch_size,
augment=augment, # augmentation
hyp=hyp, # hyperparameters
rect=rect, # rectangular batches
cache_images=cache,
single_cls=single_cls,
stride=int(stride),
pad=pad,
image_weights=image_weights,
prefix=prefix)主要调用的是LoadImagesAndLabels函数,位置还是dataloaders.py中
LoadImagesAndLabels函数:
1.读入path
| 名称 | 内容形式 | 读取方式 |
| Train路径 | 1.路径是文件夹的地址,文件夹中直接就是图片 | 直接获取文件夹中的所有图片的地址并加入f数组中 |
| 2.当前目录下相对路径: ./images/train2017/000000109622.jpg | 1.把txt文件读入 2.从txt文件路径得到图片位置 3.把左边的./替换成parent路径 |
2.得到需求的参数
self.im_files = sorted(x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS)# 如果是图片结尾的内容,那么对于x中的分隔符进行一个替换,比如从/替换成\之类的,具体换成什么取决于你的电脑的系统
# self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
assert self.im_files, f'{prefix}No images found'
except Exception as e:
raise Exception(f'{prefix}Error loading data from {path}: {e}\n{HELP_URL}') from e
# Check cache
self.label_files = img2label_paths(self.im_files) # labels
cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache')
try:
cache, exists = np.load(cache_path, allow_pickle=True).item(), True # load dict
assert cache['version'] == self.cache_version # matches current version
assert cache['hash'] == get_hash(self.label_files + self.im_files) # identical hash
except Exception:
cache, exists = self.cache_labels(cache_path, prefix), False # run cache ops1.替换间隔符号之后得到了Self.im_files
2.使用image2label()处理之后得到了Self.label_files
3.上面的路径添加后缀.cache得到了Cache_path
上面标红的两个内容就是从txt中读出的关于数据集的信息,经历了LoadImagesAndLabels函数之后,现在图片是一张一张以绝对路径的形式保存在了模型之中便于读取
至此dataset中的关于输入数据的内容已经全部处理完成。
Step3:Train_loader后续具体加载进入模型中的路径(从每一张图片的路径变成图片信息矩阵被模型所处理)
1.通过enumerate函数加载进入pbar之中
pbar = enumerate(train_loader)位置:train.py中start training部分
2.通过tqdm函数加载图片和进度条
pbar = tqdm(pbar, total=nb, bar_format=TQDM_BAR_FORMAT)3.经过for循环将内容提取为imgs,targets,paths。
for i, (imgs, targets, paths, _) in pbar:至此,关于数据集的读入已经完成。
问题三、一些其余问题(细节:一些对于训练有意义的小细节)
1.图片的大小尺寸需要一样吗?
回答:不必要一样!
原因:代码如下
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2)
batch_size = check_train_batch_size(model, imgsz, amp)这两行代码保证了在输入进模型之前图片就已经被resize成为了模型所需要的大小,因此输入进来的图片并不一定需要一样的大小。
2.对于Anchor框的大小我是否要根据我的数据集中的物体的大小来调整呢?
回答:不需要的
原因:代码如下
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz) # run AutoAnchor上面的函数会对于Anchor框的size做出自动的调整
总结:(结论)
1.对于数据集中的图片不一定要采用一个txt记录所有图片的相对位置,实际上直接设定path为图片所在的文件夹即可。
2.对于训练自己数据集的时候只要按照格式新建一个yaml文件并且在命令行处进行修改即可
3.对于图片的size,对于Anchor框的大小等等小的细节YOLO V5的代码都顾及到了,提供了自动调整
从而,YOLOV5的代码写的确实很方便于调整修改,这一点是让作者相当佩服的。
都看到这里了不点个赞关注一下嘛awa55555















 6606
6606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









