







前言:
作为本专栏的第一篇正文,作者想聊一下关于embedding的内容,这也初入NLP所第一个遇到的一个问题:如何让计算机读入语句?。
引子:CV处理输入时的三大优势:
当我们要考虑对于NLP的输入的时候,很自然的就会考虑一下CV这个看似类似的“兄弟”。
1.全包含性
对于CV而言,处理对象是图片。而对于彩色图片来说,其是由三原色构成,可以用RGB三色的矩阵叠合的方式表达出任何颜色任何构造的图片。既然如此,在机器眼里,只要把一张图片变换成为一个三维矩阵即可,在长宽之外多余的维度信息是3,对应的就是上面说的三种颜色,也就说每一张图片都一定对应着一个三维矩阵。
2.独特性
此外,图片的处理还有一个相当合理有优势的特点:两张不同的图片不可能每一个像素格都完全一样。那么这也就意味着两张不同的图片其表示矩阵是绝对不同的。
3.内容丰富性
最后,对于两张相似的图片而言,其相似性也会表现在矩阵中。比如说对于两张都表示一只小鸟的图片,位置可能会发生变化,但是反馈在矩阵上就是都存在一块很类似的矩阵内容。
以上这三个特点,指导了本篇文章的处理方式。所以本篇文章的核心诉求就是:如何通过一种编码方式使得NLP用来表示词语的矩阵也能拥有上述的这三个必要的特点?这就是下面的发展的方式和想法。
正文:NLP对于词语输入的演化历程
但是对于NLP而言,句子长度不同,句子本身又没有一个天然的能够用矩阵表示的形式,既然如此,怎么讲句子独一无二地表现出来,这会是一个巨大的问题。
Stage 1:one-hot词向量
对于人们来说,第一个诉求就是,对于不同的词语需要不同的向量来表示,因此人们想到了one-hot词向量法则。
one-hot词向量的具体形式:
比如现在有一个语料库,里面有如下几个词语:I,love,like,apples,cakes,play,basketball。那么按照one-hot 词向量的处理方式,这些词语会进行排序,比如“I”这个词语就是第一个词表中的元素,“love”是第二个词语等等。在这个基础上,如果我们有一句句子“I love playing basketball ”
其中的词语“I”的表示向量就是(1,0,0,0,0,0,0),类似的,对于basketball这个词语就表示成了(0,0,0,0,0,0,1)这样的一个向量。实际上,确定的法则是:给到一个词语,就将其放在词表中比对,这个词语在词表中位列第几个,那么其对应的one-hot向量的第几位就是1,其余位数全是0。通过这样的方式,我们就可以将不同的词语区分开来了:不同的词语在词表中对应的向量肯定不同,而如果词表的大小足够,那么每一个词语都能有其对应的词向量。所以双射这一个基本诉求成立
one-hot 词向量的问题
以上的这种处理方式满足了双射的要求,所以其已经是一个合格的词向量命名方式了。但是其远不能称谓一种“优秀的处理方式”。为什么呢?因为第三条:词和词之间的关系并不能被表现出来
问题1:近义词或者同词根的词语之间的关系被抹去了
我们还是采取刚才的例子:在刚才的词表之中,like对应的词向量形如:(0,0,1,0,0,0,0),而love对应的词向量形如:(0,1,0,0,0,0,0)。like和love是同义词,但是观察这两个向量,两者可以说毫无相似之处。无法通过词向量展现出词语之间的关系。从人类学习的角度思考的话,将love和like两个词语分开学习是很没有效率的行为。
问题2:词表大小限制了应用场景
one-hot向量的双射的建立前提是词表必须足够大。在one-hot向量的embedding方式中,如果一个词语其没有出现在词语表中,那么这个词语是根本无法被转换成词向量的,这会导致报错。那么为了不出现报错只有两种处理方式:
1.按照全零向量处理
2.将词表扩充到一个比较大的程度。
对于第一种处理办法看似只会缺少一些词语,影响不大,但是实际上,词表中所没有的词语更多是那些罕见词,对于这些词语意思的遗失会对于句子的理解产生难以弥补的影响。
那么如此只有采用第二种方式了:对于其词表需要扩大,扩大到无论询问什么样的问题其词语都不会让程序无法判断这个词语的情况。
这真的可行,或者说是经济吗?我需要为了日常交流就把一整本英汉大字典全部记在脑子里面嘛?很明显,这不合适。
词表太小会导致有词语无法被识别,词表太大又没有起到应有的作用,徒浪费空间。
因此,当时的NLP的应用场景非常受限,因为在不学习词和词关系的情况下,根本无法做意思理解等相关操作。这个时候的词向量还是稀疏向量,就是除了一个位置是1之外其余全是0的向量,人们自然而然的就会想,能否将稀疏向量转化为密集向量,包含更多信息呢?以此为根基,word2vec模型被提了出来。
Stage2:word2vec模型(CBOW模式)详解
目的:如此通过内积判断词语之间的相互关系
正如上述所提到的一样,为了解决词语的内在关系的问题,我们推出了word2vec的词向量生成方式,将词语用稠密向量来表示。通过向量之间的内积的大小,我们就可以判断两个词语之间究竟是否有关,有多少关联。
在这一语境下,就没有双射的概念了,但是我们会发现我们的核心要求仍然能被满足。
1.当我们设定的两个词语不同,其表示的稠密向量就不同
2.对于每一个词语我们都寻找一个对应向量
那么我们就完美契合了之前的要求。
内在思想:用一个词语周边的词语来表示其本身
上面的稠密向量的处理方式有着众多优点,但是接下来的问题就是:如何定下一个映射关系使得词语能够如上面规划的一样被处理成为稠密向量。这时这个映射关系就不再像之前的one-hot向量那么自然了,实际上word2vec选择的是用上下文来表示一个词语:一个词语的意思是可以用其周边的词语进行表示的。
具体模型内容:
word2vec就是一个为了上述的目的创造的模型,思想和成果目的如上所示。但是对于这个模型具体应该如何操作仍旧在一团迷雾中,下面就从几个最基本的问题解析模型的结构。
1.如何判断模型的结果是否是合理正确的?
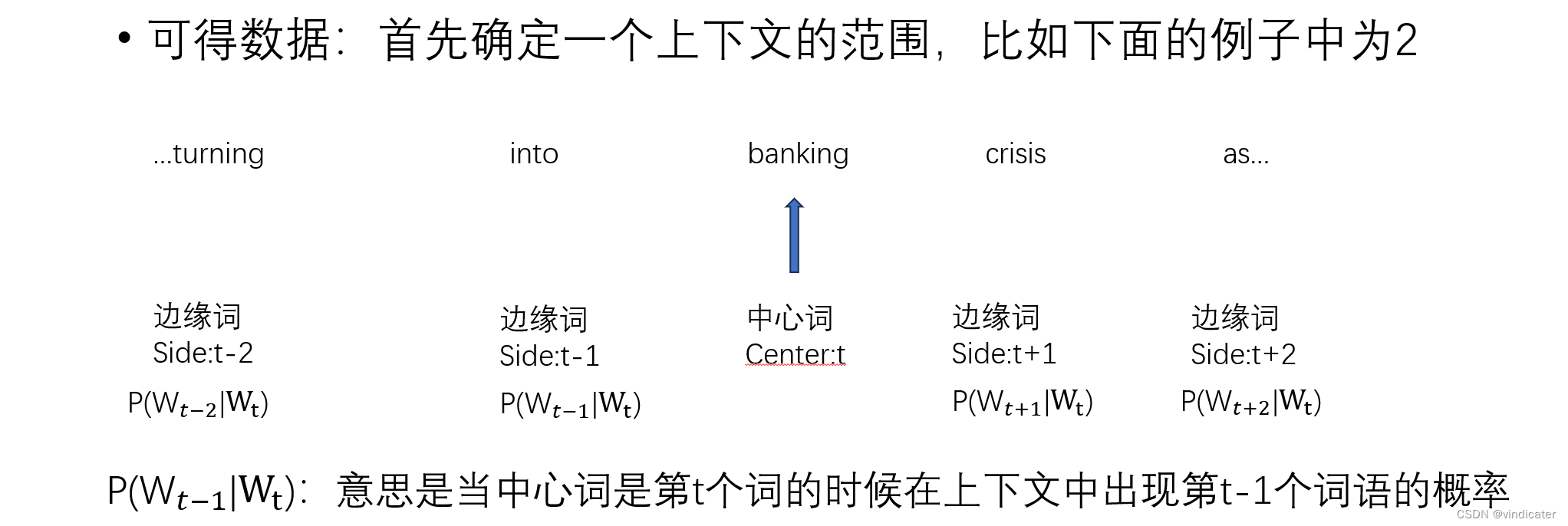
那么上面这个概率越大,也就说明模型预测的内容越准确,说明这个模型越合理。
利用周边的词语的词向量来预测中间的词语这一内容也有一定的事实依据:实际上人类是怎么判断填空应该做什么的呢?就是通过综合考虑一个词语的上下文,利用上下文的词语的语义信息的理解结果来“预测”中间的这个词语的。
注意:这里的结果和位置无关,只针对词语本身,事实上顺序和位置由于句法和语句结构角度是有意义的
2.这个possibility应该如何计算?
预测操作:
参数:语料库中一共有v个备选词语
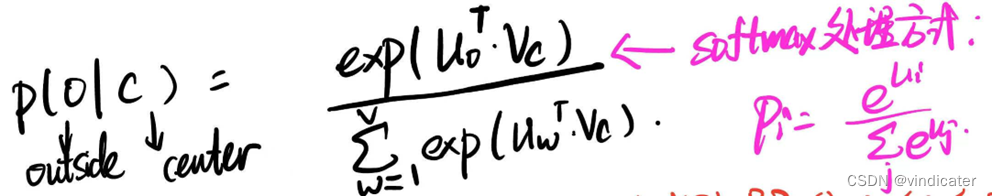
分析:
1.在word2vec模型之中,一个词作为中心词和作为边缘词对应的是两个不同的矩阵V和U,这样便于计算,所以这里的u指的是对于状态是作为边缘词的矩阵,而这里的v指的是对于作为中心词的矩阵。
2.其中的所有乘号是点乘,而右上角的T的意思是转置。
3.这其中使用了softmax的处理方式得到总和为1的概率值;通过exp的方式在保留了原先特征的前提下将所有内容全部变成正数
3.损失函数是什么?
在论证了一个模型的结果是可以判断而且合理的之后,那接踵而至的问题就应该是如何判定损失函数。模型必须通过反向传播的方式改善推理得到的词向量结果,此时一个合适的损失函数就是至关重要的。
word2vec的损失函数如下:
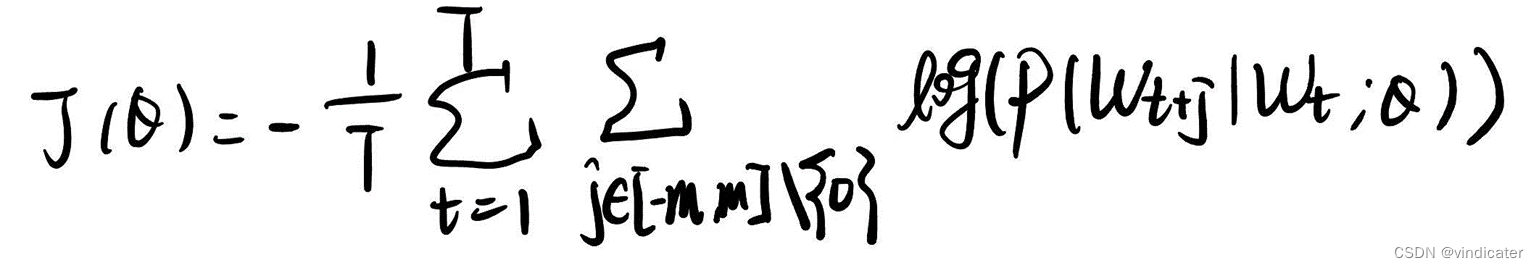
解释说明:
1.由于后面的概率小于1,取对数之后得到的结果应该是个负数,这里在前面加上负号来使得结果取正数的同时使得损失函数我们的目标是取最小值,符合一贯的习惯。
2.对于这2m个词语,分别根据预测的结果,得到其出现在这一中心词的上下文中的概率。对于这2M个概率取对数之后累加,得到的结果越大说明每一个概率越接近于1,也就是预测的越准,越小说明越不准。
4.从方向传播角度说明模型的合理性:
下面的是上文的内容求导的表达式

(由于CSDN不支持Word的格式这里采用截图的形式解析):

后续的一些improvement:
1.Negative Sampling
目的:
每次运算之后都会出现正负样本的调整,而这个模型中,对于一个句子中的一个词语位置,其只可能有一个正样本(确实存在在那个位置的词语),其余词库中的内容全是负样本,这就会导致负样本量过大不便计算。因此对于负样本需要进行筛选以提高效率。
具体操作:按照负样本词语的出现频率筛选负样本。
公式:
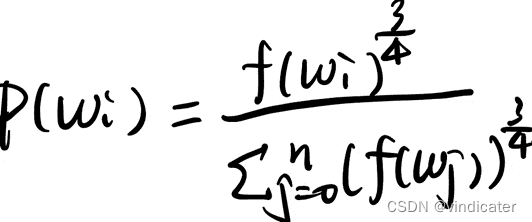
1.f:frequency,某一个词在所有语料中出现的频率
2.采用了softmax的形式让所有的频率归一化
3.3/4这个系数是通过实验得出的最合适的参数
选择原则:按照p得分进行加权筛选负样本做反向传播
操作理由:为何选取常见词语作为反向传播的对象呢?
答:一个既定事实是常见词语会很频繁地出现在正样本中,而正样本的要求是越接近1越好,那么如果我们不指定某些为负样本反向传播,机器会发现直接把常见词汇设置为1得到的结果很好,这不是合理的结果。因此需要把常见词汇更多的设置为负样本来抑制机器学习时的错误学习策略。相对的来说,对于那些不常出现的词汇不会出现上面的情况
2.sub-sampling
目的:防止某些出现频率过高的词语作为边缘词语被采样过多
例子解释:

1.蓝色框中:如果重复把the作为边缘词,那么让机器学习fox的上下文中有the这个词语这一行为意义是不大的,因为the后面可以添加大量的不同物体,未必一定是fox,对于fox的意义扩展不大。所以这样的学习最好是能够减少甚至避免的。
2.黄色框中:fox的上下文中出现the可以说明fox是作为一个名词的出现,而born这样一个词语的出现说明了其作为一个生物的属性,可以看出这样的罕见词fox的学习效果是极好的,需要多进行学习。
具体操作:
在形成窗口之前就进行按照下面的公式的丢弃操作,高频词更容易被丢弃,从而使得窗口中能采到更多有意义的词语

如图,在扔掉一部分没有什么意义的词语之后上下文采样就可以采到最合适的词语。
确定的可能性的计算公式:
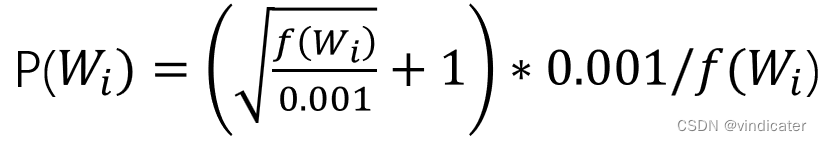
这个possibility是扔掉某些词语的概率和可能性。
结语:
本文中主要介绍的是对于词语的一种处理方式:如何把词语变化成词向量。从one-hot向量方式变成word2vec的发展途径是很有逻辑的,从只具备了双射的特性,到考虑到了词语之间的内在关系,如果掌握了思路之后,相信能对于整个模型有更加深刻的理解。对于word2vec作者仅选择了一个CBOW进行了解,关于另一个版本skip-gram作者了解的不是很多,未来如果有学习到会来更新笔记的。这一步是NLP处理的绝对基础,将词语转化成词向量了之后,计算机便可以读取语句内容了。读取了之后应该如何处理呢?下一篇文章中作者将主题介绍网络模型的基础架构。如果认为本文对于读者有所帮助的话,点个赞点个关注吧awa















 2971
2971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









