







前言:
上一篇文章解决了最开始NLP相关遇到的问题:怎么将句子或者文本以切分成的词语的形式被输入进模型之中,文章链接如下:
从embedding开始的NLP学习之旅:如何让机器读入语句内容?_vindicater的博客-CSDN博客
有了上述技术的前提,我们可以将一句句子看做是若干词语的顺序组合,其中每一个词语都有对应的一个稠密向量。现在面对的问题就变成了,如何让程序将这一个个词语融合在一起形成对于句子的理解?这就是本文的主要介绍内容,涉及到:RNN到GRU与LSTM。在这一步步的发展中,模型愈来愈精细,应用的场景也愈来愈丰富。对于当今时代更重要更让人赞叹的transformer和大模型等等的内容,作者会在下一篇文章中提及。
演变过程:
Stage 1:RNN神经网络
1.基本结构:

分析:
1.对于最早的RNN,在还没有提出word2vec的时候,采用的是one-hot向量来进行运算,但是,我们可以发现,这里对于词语的向量表示,无论是one-hot形式的表示还是CBOW的稠密向量的表示方式,对于整个模型的效果其实影响不大。
2.其实RNN作为初代的NLP的网络结构,其思路是相当基础而且漂亮的。
观察人类理解一个句子的时候,大致有以下特性:
(1)当阅读一句句子的时候,人们倾向于从头开始阅读,一个词语接着一个词语阅读
(2)阅读的过程是一个一直记忆的过程,而不是读完了之后就遗忘再继续阅读。
对于第一点,体现在了网络的结构中:一个接着一个词语输入进入程序之中,模拟的就是一个一个词语按照顺序被人脑接收的过程。这样,词语的顺序信息也被程序所吸纳。
对于第二点,体现在了那个层与层之间传递的数据“h”中,每一次加入了最新的词语之后,这个参数h就被更新一次用来传递给下一次读取数据。这个h中就是对于之前所有阅读到的内容的一个总结。
2.输出结果:
1.N VS N:输入n个词语得到了n个词语的输出,一般是用来处理视频的逐帧的处理
2.N VS 1:输入n个词向量,得到一个结果(一般搭配softmax分类使用),可以用于语段内容理解分类
3.1 VS N:输入一个向量,得到n个输出,一般用于比如对于一张图片输出一段描述的语言
4.N VS M:对应的就是2和3的组合或者2和1的组合,目的是可以用来做翻译等等内容(Encoder-Decoder)
5.双向RNN:这个属于是网络结构的一个改进,会在后续小节专门提到对于RNN的改善的时候介绍。
3.优点和不足:
优点:每一次计算都附带了上一次的信息,照顾到了上下文词语的相关性。作为开创性的NLP的网络结构,其效果已经属于是可圈可点了。
缺点:1.计算方式是有顺序的,不能多线程
2.很容易产生梯度爆炸或者消失的问题。
分析:
梯度爆炸和梯度消失这种问题是任何没有残差或者类残差结构的网络共同面对的问题之一,在CV相关的内容中就是首先引入了PassThrough再引入了Residual network。对于NLP,相应的解决办法就是LSTM和GRU这两个门控单元。
Stage 2:对于RNN的改进:GRU,LSTM和双向RNN
1.GRU介绍
(1)基本结构&对比

主要变化:
1.从h的计算方式中改变:在和上一次的和h求和的时候多出了一个可以调整的系数r,通过改变其中的三个系数来改变这个参数从而达到调整上一次得到的h在这次要输出的h中占有的权重,一般称为遗忘门(重置门)。
2.在计算这一次输出h的时候加入了一个系数z,可以用此直接调整上一次的计算结果h在其中的权重,相当于是从浅层直接相加,一般被称为更新门。
变化分析:
由于主要目的是为了对抗可能出现的梯度爆炸和梯度消失的情况,GRU采用了一个类似于resnet50的残差结构的方式保留了之前的信息。同时这两个参数一个是直接相加另一个是在函数的最内层相加分别是从深层添加了之前的信息和从表层添加了之前的信息,虽然这个在NLP中没有如同CV中那样表面的颜色和深层次的纹理那样的形象描述,但是仍然是有理由相信这样的行为是合理的且有实际功效的。
2.LSTM介绍(以下的图片参考自openBMB的大模型公开课,链接请看本专栏的前言)
基本结构:
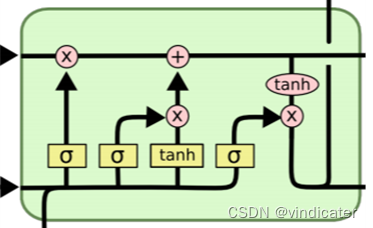
具体内容:
1.
Step1:计算遗忘门的参数
2.
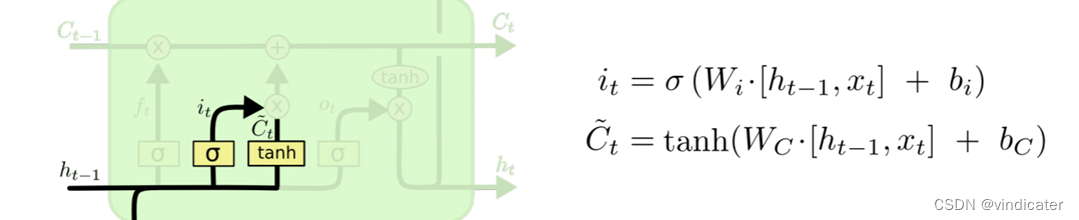
Step2:计算更新门的参数
3.
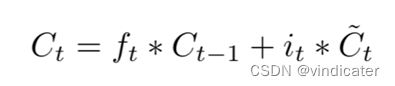
Step3:通过上面得到的两个参数计算C,此时C已经融合了之前的和这次的信息
4.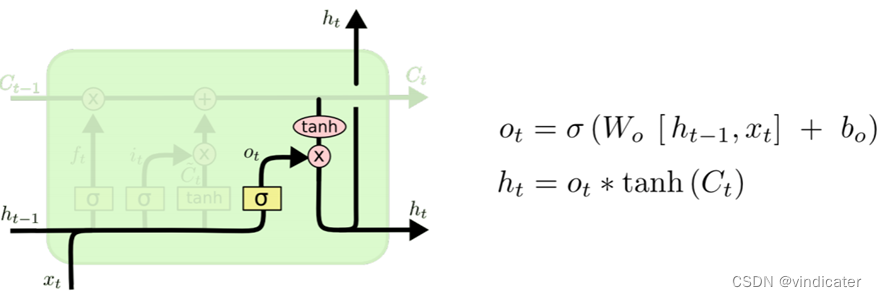
Step4:利用上面得到的C和这次的结果对应的系数相乘得到输出结果
总结:
对于LSTM而言,其网络结果极其复杂,但是其结构的本质还是通过concatenation的方式进行了类残差操作。因此尽管LSTM的推出时间比GRU推出的时间要早很多,但是这里作者决定先介绍GRU再介绍LSTM。几乎每一步中都运用了之前传来的C和h 的结果!
3.将GRU和LSTM对比:
直观对比图:
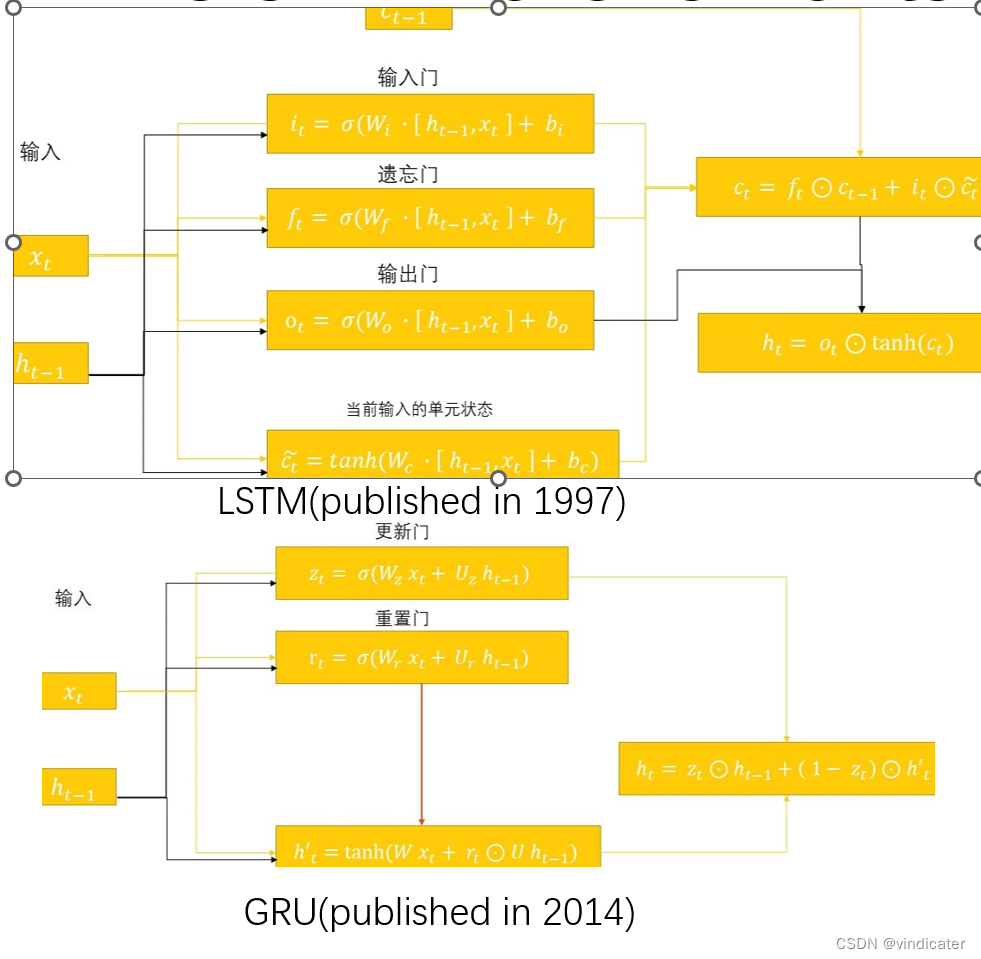
两个基本的形式变化:
1.和上次的输出结果的叠加从直接相加变成了concatenation
2.增加了一个状态量C,C这个状态量将会贯彻始终,而GRU认为C这个隐向量和h中的信息有一定重复因而不选择单独拿出C
3.GRU相对于LSTM来说把输入门和遗忘门融合在了一起,并且比较“粗暴地”通过决定这次的信息和上次的信息按照和为1的方式进行相加。这一点其实是有道理的,即使采取的是两个参数,但是实际上起到作用的是两者的比例,而不是两个参数本身
优势分析:
对于LSTM来说,所有的内容都被保存在了C中因而长期记忆肯定效果更好。
对于GRU来说,通过合并了一个门的方式大大减轻了计算量,且采用了类残差结构也很有效地减少了梯度爆炸和消失的问题。
选择哪个?
事实上,这两者在performance上差距不大,远远不及调参的优势。而就收敛速度来说GRU因为参数少更胜一筹。但是实际上,现在的很多有现实运用的模型,两者都有搭载,而且效果尚可。
4.双向RNN:解决单向观察问题:
RNN网络的问题:只能单向观察
对于RNN网络来说,其网络结构是单向的,也就是说其只能看到前面的词语的内容,无法看见后面的词语的内容。但是我们人类在阅读的时候会选择上下文兼顾的方式去理解一个文本。
前面讲到了word2vec这一方法,介绍到了其CBOW模型。其在阅读训练的时候采用的是通过挖掉中间一个词语进行预测的方式学习。那么对于这样一句句子“我的车坏了我要()新车”:当看到后面的“新车”二字的时候,得到填空处的“买”,就会自然地将买新车结合起来形成一个用法。这样的学习效果比“我要买”这样的搭配要合理很多。这就体现出了给予机器双向视野的重要性。
因此为了解决理解词语只能看前文的限制,双向RNN被提了出来。
结构图(摘自知乎用户:宋迎新):
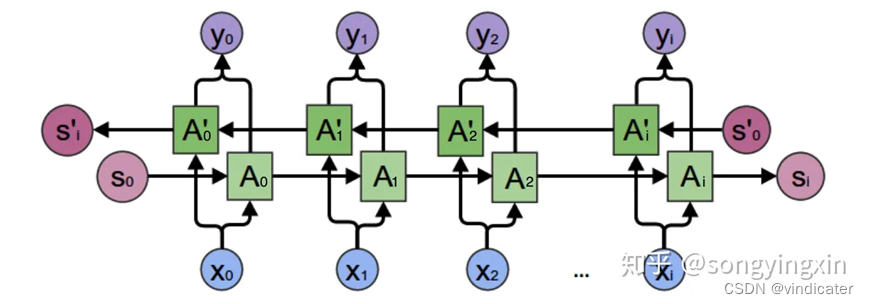
其中最重要的区别是从原来的单方向变成了双方向,这样每一个结果都融合了之前和之后的结果。
5.总结对比:
RNN:最大特色就是可以记忆多个词语之前的信息,利用之前的信息来判断输出的应该是什么,但是会出现两个问题:
1.容易出现梯度爆炸或者消失
解决方法:通过类似于残差模块的设计来解决,GRU与LSTM都是利用了这一设计,只是LSTM的类残差模块数量更多因此效果更好。
2.有些内容只靠前侧内容无法做出判断
解决办法:使用了双向RNN来采集前后的信息。
后记
本文中主要介绍了自然语言处理中比较基础的一些内容,从最简单的RNN到LSTM,GRU或者双向RNN,其发展的思路是很朴素的提出了初步的解决方法之后,分析找到其中的不足,相应的做出一些修改和改善。为了解决梯度爆炸和消失的问题,GRU和LSTM被创造出来;为了解决双向问题:双向RNN的结构被创造而出。这一模型在当时的时代背景之下被认为是最合理的模型结构,指导attention机制和transformer结构的横空出世。其聚焦于一个新的内容,完成了对于模型性能的巨量提升,这些我将在下一篇专栏中介绍。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









