






Event Loop是node.js的核心内容。网上有很多文章描述Event Loop,但或多或少有一些错误或者过时的地方。这篇文章也是对我个人的理解做一个总结,如有错误,请指出。
参考资料汇总
The Node.js Event Loop, Timers, and process.nextTick()
这篇是官方文档,还是比较权威的。中间有些地方表述不够清晰,容易让人产生迷惑,后续会提到。
AceMood : Event loop in javascript
这篇文章写的很详细,从i/o模型一路解释上来,详细而准确。如果硬要我找错,我只能说文中有些语法错误- -
JavaScript 运行机制详解:再谈Event Loop
鉴于阮老师本人的影响力,这篇文章应该是有很大阅读量的。浅显易懂遵循了阮老师一贯的风格,不幸的是,文章里有不少的错误,建议配合朴老师的批注一起阅读。另外,评论区也是要仔细看得,里面有大量的勘误。
Node.js Event Loop 的理解 Timers,process.nextTick()
文章的内容主要以翻译node官方文档为主,下面的评论才是重点。
要搞明白Event loop,看看libuv源码是很有帮助的。这篇文章翻译自uvbook。
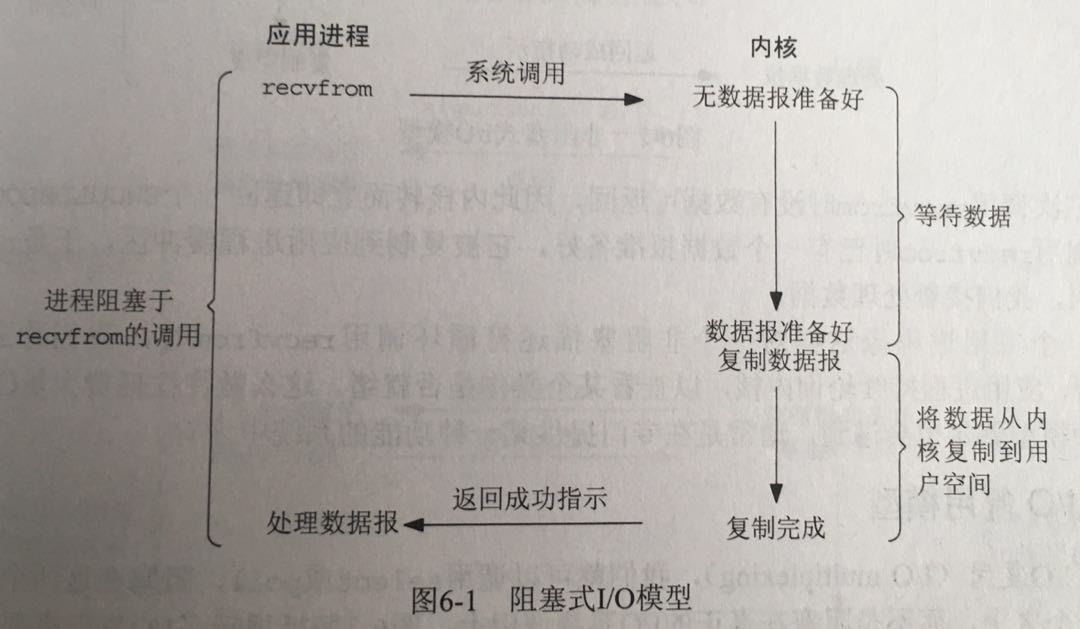
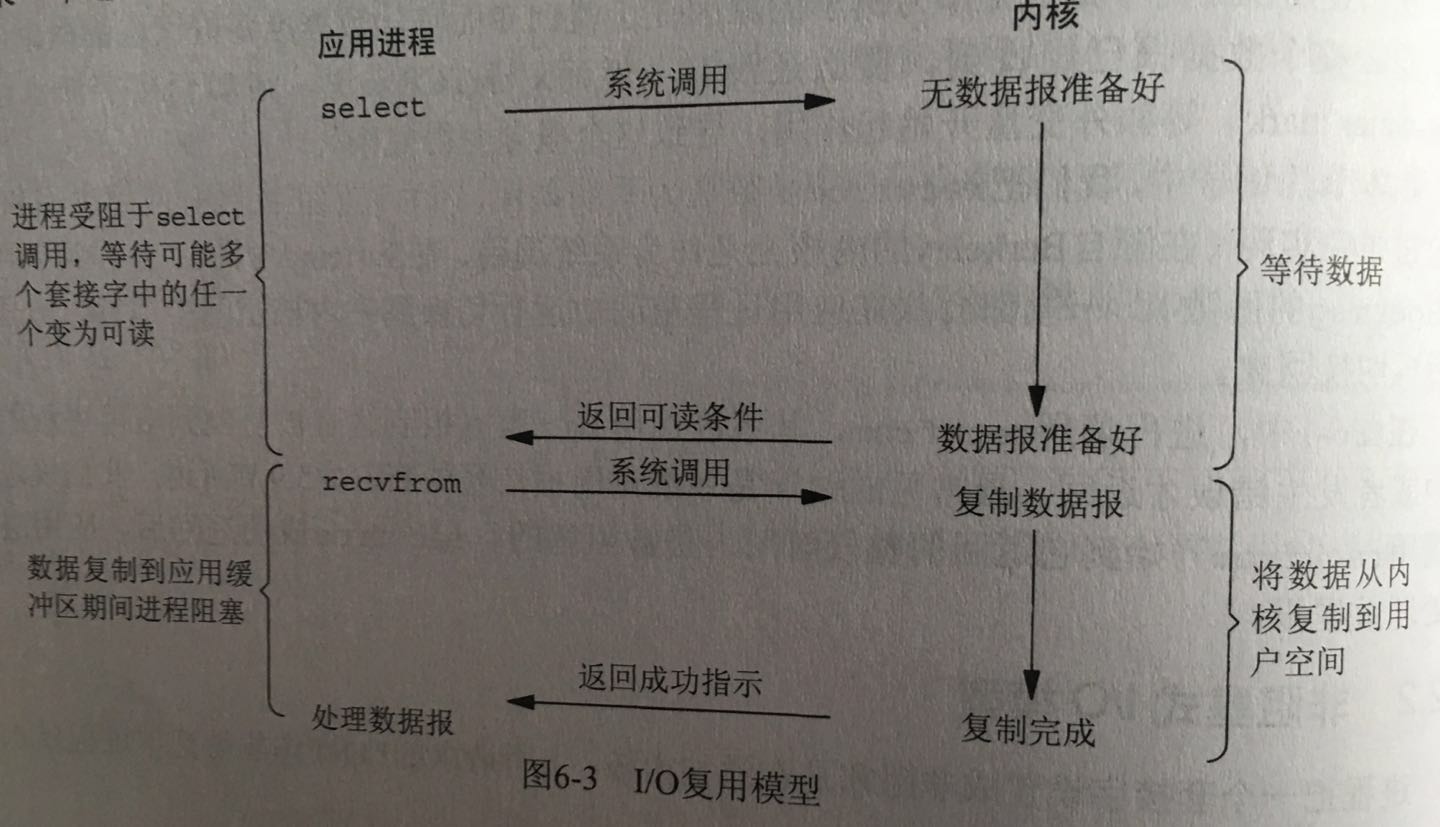
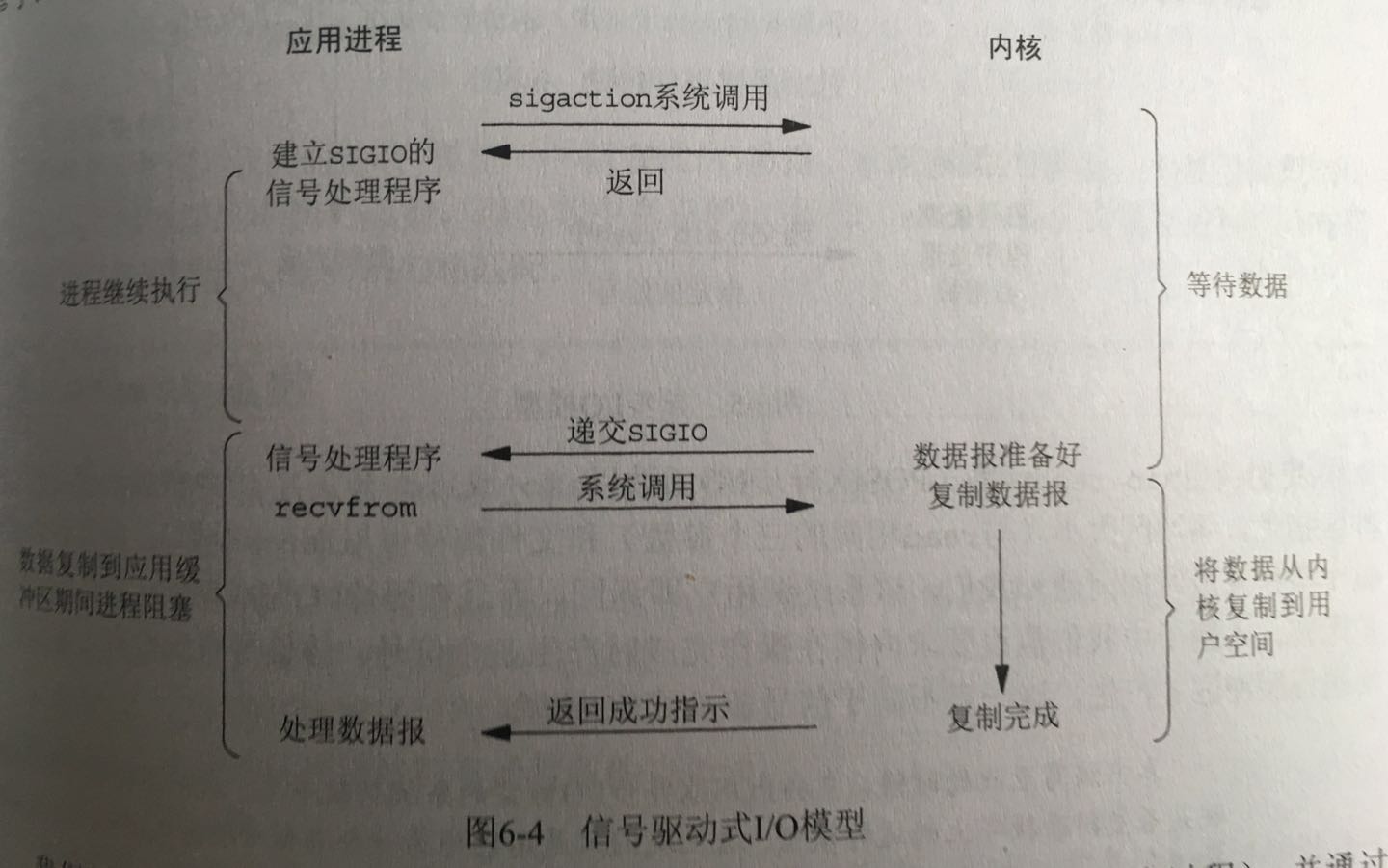
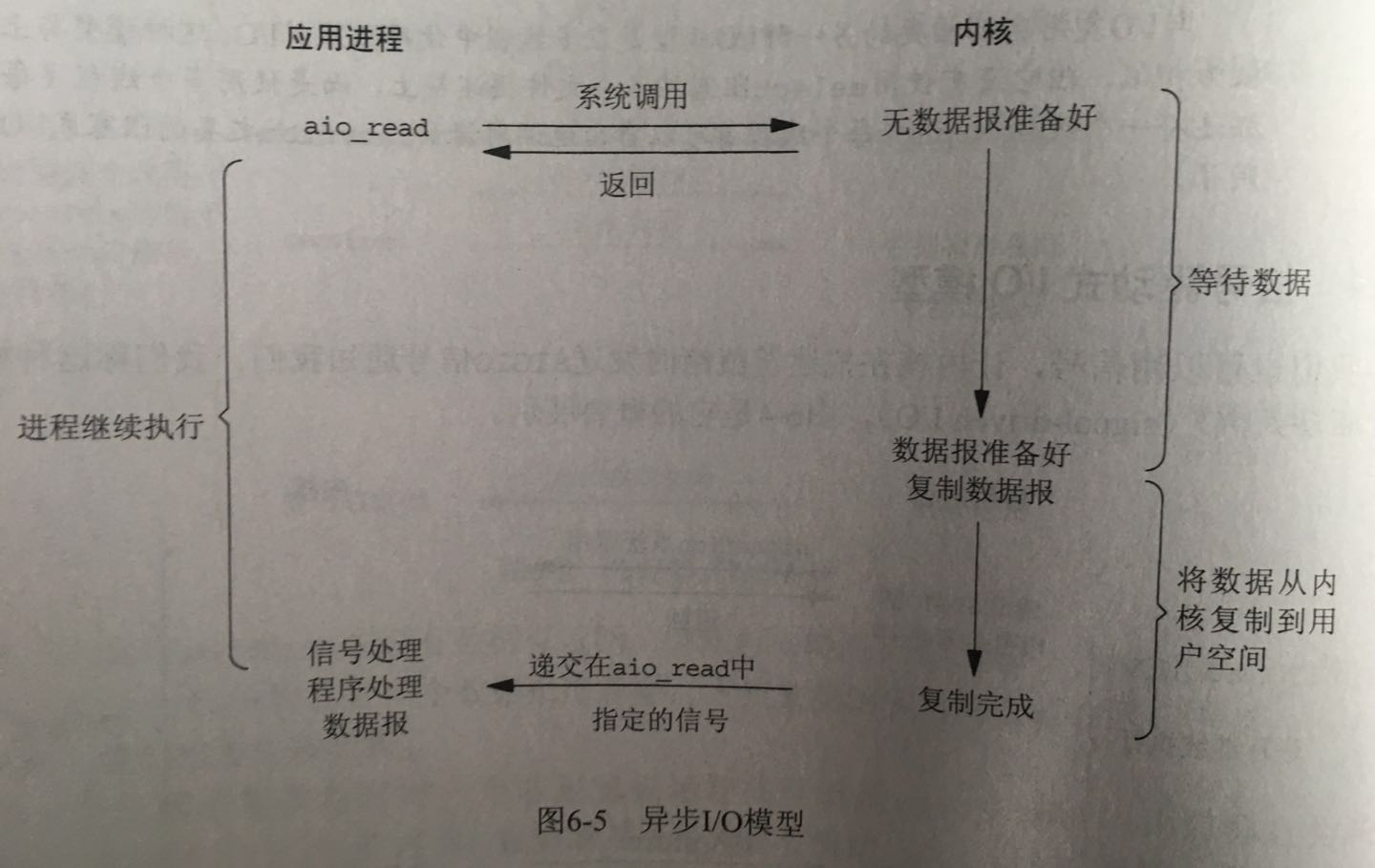
IO模型
常见的io模型一共有五种。
- 阻塞IO
- 非阻塞IO
- IO多路复用
- 信号驱动io
- 异步IO
这五种的具体内容在AceMood : Event loop in javascript这篇文章里都写的很明白了。libuv中的io主要有两种,一是网络io,LINUX和MAC使用的是IO多路复用的策略,即系统提供的EPOLL/KQUEUE,WIN下则是使用的异步IO,即IOCP;二是文件IO,在各个平台下均使用线程池实现。
这里附上一份《UNIX网络编程》上的图吧。

事件循环的优点
通常服务器都是要同时承受很多个连接的,如果使用单进程/线程配合阻塞IO的话,那么势必会浪费大量的时间在等IO上,大量的请求积压得不到处理。为了解决这个问题,衍生出了两种模型,一种是多进程多线程处理的,如apache,socat(指定fork)。一个连接对应一个进程/线程。缺点显而易见,进程/线程本身创建是有资源消耗的,上下文切换也是有资源消耗的;第二种是事件循环,如nginx和node。资源消耗小,高并发是它的优势。缺点是,难以利用现代处理器多核的优势。
Phase in event loop
┌───────────────────────┐
┌─>│ timers │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ I/O callbacks │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
│ │ idle, prepare │
│ └──────────┬────────────┘ ┌───────────────┐
│ ┌──────────┴────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └──────────┬────────────┘ │ data, etc. │
│ ┌──────────┴────────────┐ └───────────────┘
│ │ check │
│ └──────────┬────────────┘
│ ┌──────────┴────────────┐
└──┤ close callbacks │
└───────────────────────┘event loop是libuv里的主循环,位于src/unix/core.c里的int uv_run(uv_loop_t* loop, uv_run_mode mode)。各个阶段的区别参见官方文档The Node.js Event Loop, Timers, and process.nextTick()。
setTimeout
timer在node中的实现要分两部分讨论,一是js层面的timer,另一个是libuv层面的timer。关于具体实现,后续有时间再单独写,这里只列举一些关键点。
libuv的timer
- 基于最小堆实现
- 新建操作的时间复杂度是O(logn),删除和到期操作都是O(1)
js的timer
- 使用双向链表来管理所有的timer对象
- 所有超时时间一样的timer会共享一个libuv的timer。
注册在setTimeout上的回调会在event loop的第一个阶段执行。
setTimeout(fn, 0)
node源码对timer的超时时间做了预处理,见lib/timers.js:
function createSingleTimeout(callback, after, args) {
after *= 1; // coalesce to number or NaN
if (!(after >= 1 && after <= TIMEOUT_MAX))
after = 1; // schedule on next tick, follows browser behavior过小或者过大的超时时间都是会被转成1ms,也就是说,无法利用setTimeout来实现所谓立即执行的效果。
setImmediate
setImmediate位于check阶段执行。它有个显著的特点,就是总是把回调函数注册到下一次执行的immediate队列里,在进入check阶段后一次性执行完。
重点有两个,一个是每次在check阶段里都会把注册到当前事件循环里的所有callback全部执行。有种说法是每次event loop执行一个,其实是并不准确的,见如下代码:
setImmediate(() => {
console.log("imm1");
process.nextTick(() => {
console.log("next1");
})
})
setImmediate(() => {
console.log("imm2");
process.nextTick(() => {
console.log("next2");
})
})这里有个前提,那就是console.log本身是个同步操作,不会干扰我们对异步任务顺序的观察。
二是它总是把callback注册到下一次的immediate队列里,这也就意味着嵌套调用setImmediate并不会阻塞事件循环。注意这里说的是下一次,而不是下一次事件循环,这二者是有区别的。考虑如下情形,在setTimeout的callback里再注册一个setImmediate回调,也就是在timer的执行阶段注册,那么它会注册在本轮event loop的check阶段执行还是下一轮event loop的check阶段执行?如下代码会给出答案:
setTimeout(() => {
console.log("event loop 0 phase: timer");
setImmediate(() => {
console.log("event loop 0 phase: check");
for (let i = 0; i < 1000; i ++) {
let p = "";
p += "waste time here to make sure the second timer will expire in the next loop";
}
setImmediate(() => {
console.log("event loop 1 phase: check");
})
}, 0);
setTimeout(() => {
console.log("event loop 1 phase: timer");
}, 0);
}, 0);process.nextTick
process.nextTick并不在libuv的event loop内。事实上,它在每一次event loop的phase改变的时候执行。和setImmediate不一样的是,它会一直试图清空已有的任务队列,因此,递归调用process.nextTick会使得事件循环无法执行。node官方文档里是这样描述的:
any time you call process.nextTick() in a given phase, all callbacks passed to process.nextTick() will be resolved before the event loop continues
这里就会有一个问题,如果同时注册了两个定时器,在第一个定时器的callback内调用process.nextTick,那么是process.nextTick先执行,还是先清空已有的timer回调队列呢?代码如下:
setTimeout(() => {
console.log(1);
process.nextTick(() => {
console.log(3);
})
}, 0);
setTimeout(() => {
console.log(2);
});
for (let i = 0; i < 1000; i ++) {
let p = "";
p += "waste time";
}文档里关于这个问题写的比较模糊,before the event loop continues, 执行下一个定时器回调也可以叫做continue,执行下一个phase也可以叫continue。
有篇文章里是这么写的(这句话好像已经被删掉了,评论区里前几天已经有人提出质疑了):
So if the event loop is in Timer and there were 5 callbacks in the timer queue already; and event loop is busy executing the third one. By that time if few process.nextTick() callbacks are pushed to nextTickQueue, the event loop will execute all of them synchronously after completing the current callback execution (which is 3rd one) and will resume the Timer callback execution again from the 4th callback
大意就是,注册了5个定时器,在第三个定时器的callback内调用了process.nextTick,那么process.nextTick会立刻执行,然后才去执行第四个定时器的回调。
实际上这个分析是有问题的,如同前面所述,process.nextTick()只在phase改变的时候执行。引用node官方的另一篇博客:
All callbacks scheduled via process.nextTick() are run at the end of a phase of the event loop (e.g. timers) before transitioning to the next phase.
并发与并行
并行这个概念应该是来源于硬件。
早期的硬件接口使用的是串行接口,同一时刻同一方向上(发或者收)只会传输一个比特,典型的如RS232串口,其规范里的最大速率115kbps多点,这实在太慢了。一根线传起来太慢,多搞几根线不就完了?于是就出现了并口,老式的打印机、电脑上还能见到这个接口,早期的硬盘用的也是PATA并口。同一时刻同一方向上传输的最大比特数取决于用了几根线。再到后来,并行传输很快就遇到了瓶颈:紧密排布的几根线之间的电磁干扰很难解决,虽然一次可以传很多个比特,但是时钟速率提高之后,传输错误也显著增加,通俗的说就是:跑不快。所以,折腾了一圈,最后又回到了串行通信上。以上可以看出并行和串行的本质不同在于,同一时刻能够传送的比特数量。
到软件层面,就变换为同一时刻能够处理的任务。这个时刻,是物理意义上的精确的时间,从CPU这个层面来理解,就是每个时钟上升沿。并发从本质上来说,依然是串行处理的,同一时刻只处理一件事。但是它处理的速度很快,以至于你觉得它像是在同时处理它们一样。除了多核处理器、分布式等算是真正的并行处理以外,其他都算是伪并行。与硬件类似,软件中的并行同样存在着缺点,首先不是所有代码都可以被并行化处理,其次并行处理必然需要额外的共享资源、通信机制、锁额外开销。所以,如果有两个选择,1个核可以跑到10G,和有10个核每个只能跑1G,我想大多数代码在前者上的效率要高的多。















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









