









这里写自定义目录标题
随着AI技术的发展和成熟,Python语言凭借其万能胶的能力成为了机器学习编程语言的首选。特别是随着Tensorflow等优秀库类的出现,大大降低了机器学习入门的门槛,本文旨在给各位码友提供一个迅速进入编写机器学习程序的正确姿势。
0. 操作系统选择
Linux:
追求性能和可玩性的推荐ubuntu 18.04 Lts版本,新出的20.x可能其他功能包支持不足情况。如果是有GPU的同学在安装时可能会有些坑,其中最大的坑就是nvidia网站下载相关包可能很慢导致安装受阻。
Windows:
Win10在各方面兼容性上,特别是显卡方面,支持得挺不错。
1. Python语言环境安装
Python环境首选推荐Anaconda,不仅因为其相对简单、多平台可用,还因为其对Python虚拟环境支持比较友好(这点在后面将进一步说明,其对于想多尝试各种新技术又不想破坏原有环境的同学特别有用)。
1.1 安装包
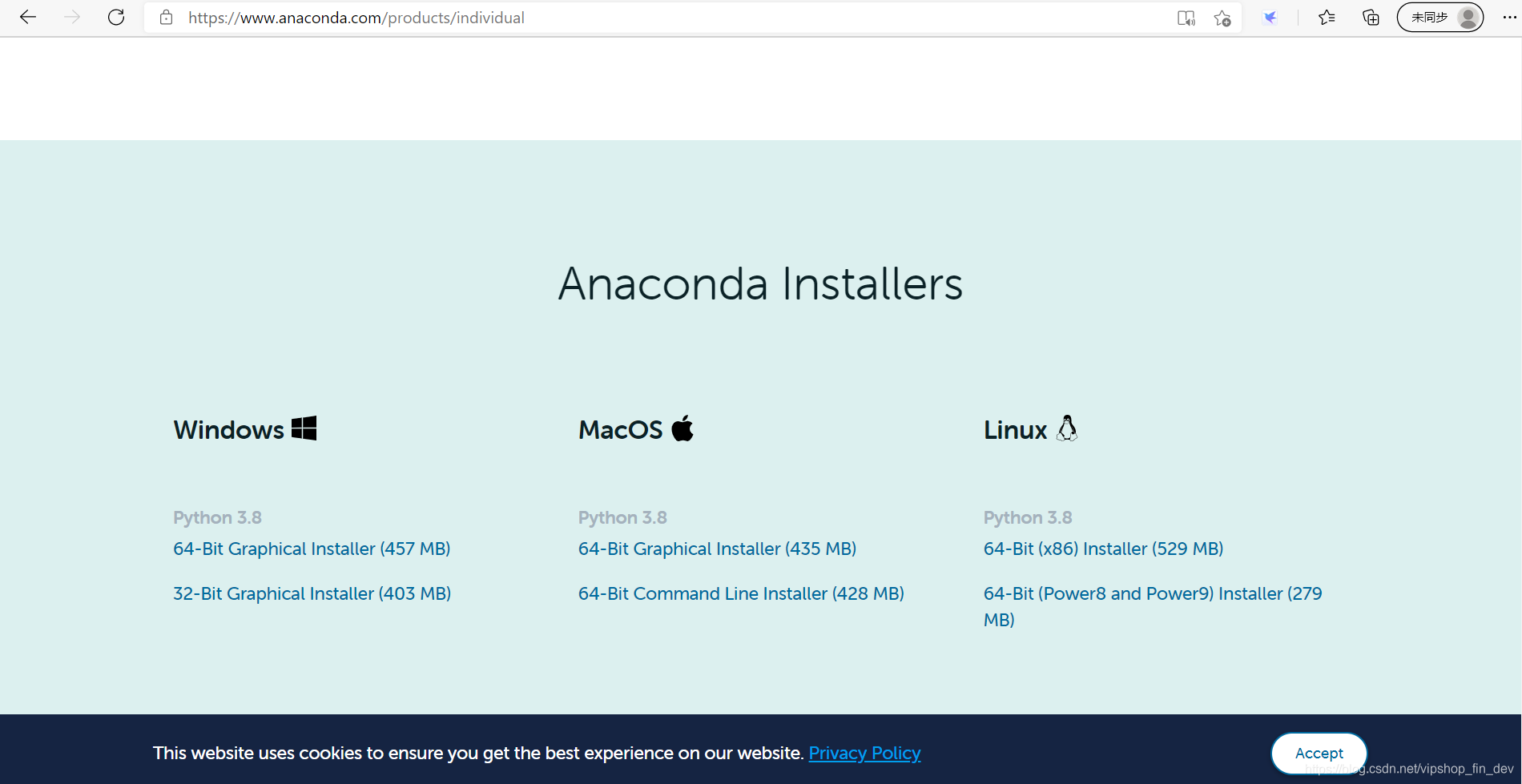
根据各人系统环境选择安装全家桶系列:
https://www.anaconda.com/products/individual
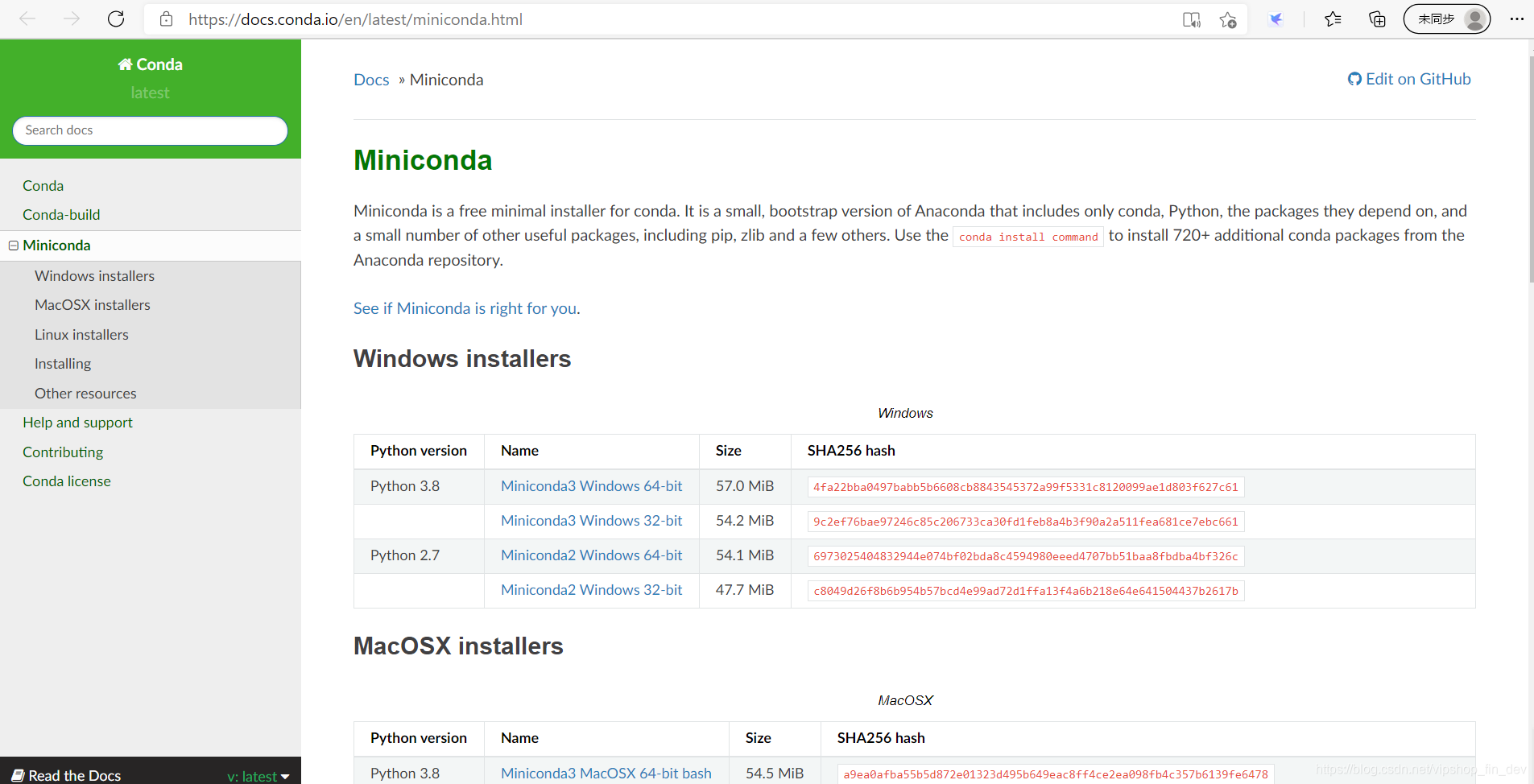
如对于想最小化安装的同学,可以选择miniconda,大概就50多m:
https://docs.conda.io/en/latest/miniconda.html
1.2 使用虚拟环境
如果是全家桶的同学,建立虚拟环境将,非常方面,可以在Linux控制台上直接输入命令
anaconda-navigator
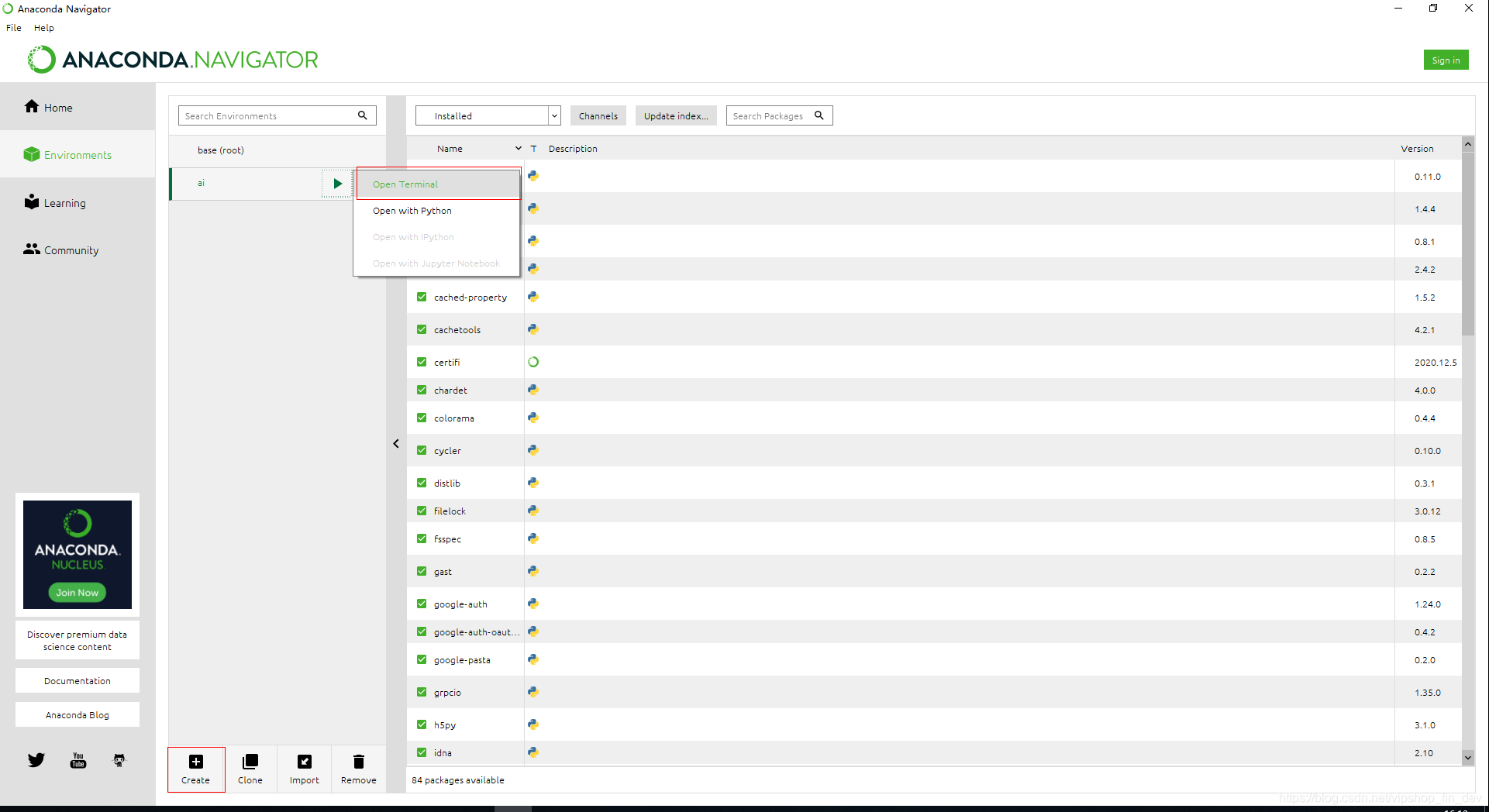
左侧菜单栏进入“Environments” -> 点击下方按钮“Create” 并命名即可建立新的虚拟环境,创建完毕后点击箭头按钮选择“Open Terminal” 即可打开对应虚拟环境的控制台,在其中安装、卸载包都不影响原来的“base(root)”环境
而对于未安装全家桶的同学,就需要使用命令行操作了,以下是虚拟环境相关操作命令
#创建虚拟环境
conda create -n env_name python=2.7
#同时安装必要的包
conda create -n env_name numpy matplotlib python=2.7
#激活虚拟环境
Linux: source activate your_env_name(虚拟环境名称)
Windows: activate your_env_name(虚拟环境名称)
#退出虚拟环境
Linux: conda deactivate your_env_name(虚拟环境名称)
Windows: deactivate env_name
也可以使用如下命令切回root环境
activate root
#删除虚拟环境
使用命令conda remove -n your_env_name(虚拟环境名称) --all
#删除虚拟环境中的包:
使用命令conda remove --name $your_env_name $package_name(包名)
2. 显示驱动安装(如有GPU可选)
Ubuntu 18.04
显卡要使用Nvidia的,因黄教主在人工智能方面做得很好,显卡兼容性相比AMD的好很多,使用也相较简单,而且各种机器学习工具包支持也好很多(这也是为什么Nvidia股票一路狂涨的原因)。此外,如果对于台式机多屏幕的情况,最好所有输出都集中到同一个显卡上,因为Ubuntu对这种情况的驱动设置支持不够友好。
- 卸载原有nvidia显卡驱动
sudo apt-get remove --purge nvidia*
sudo apt-get autoremove nvidia*
sh ./nvidia.run --uninstall
- 添加Graphic Drivers PPA
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
- 查看合适的驱动版本:
ubuntu-drivers devices
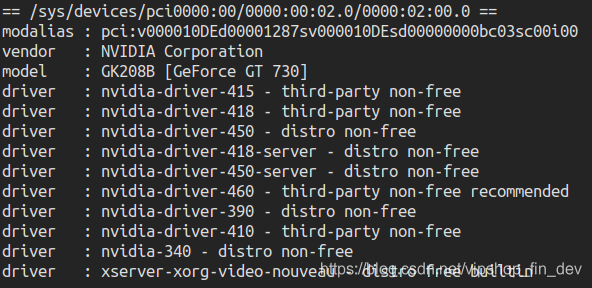
- 选择推荐的驱动进行安装(这里需要有点耐心,安装文件比较多也比较大,有时Nvidia网站又会比较慢,选择晚上安装似乎情况好点)
sudo apt-get install nvidia-driver-460
- 重启后可通过nvidia-smi 查看显卡信息,至此显卡驱动安装完毕。
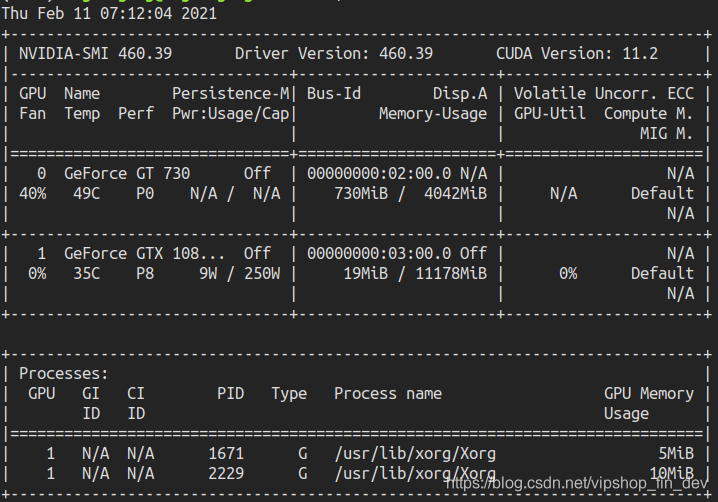
Windows
windows依然推荐用Nvidia显卡,理由同上,驱动的安装就不需要说了,大家都懂。
3. 编程IDE(VS CODE)安装
VS Code 是现在比较流行的轻量级IDE,安装也简单,建议直接下载绿色压缩版本进行解压执行:
https://code.visualstudio.com/#alt-downloads
 一般安装如下插件:
一般安装如下插件:
Python
Jupyter
GitLens(版本控制)
Visual Studio IntelliCode (输入提示)
vscode-icons(文件类型图标)
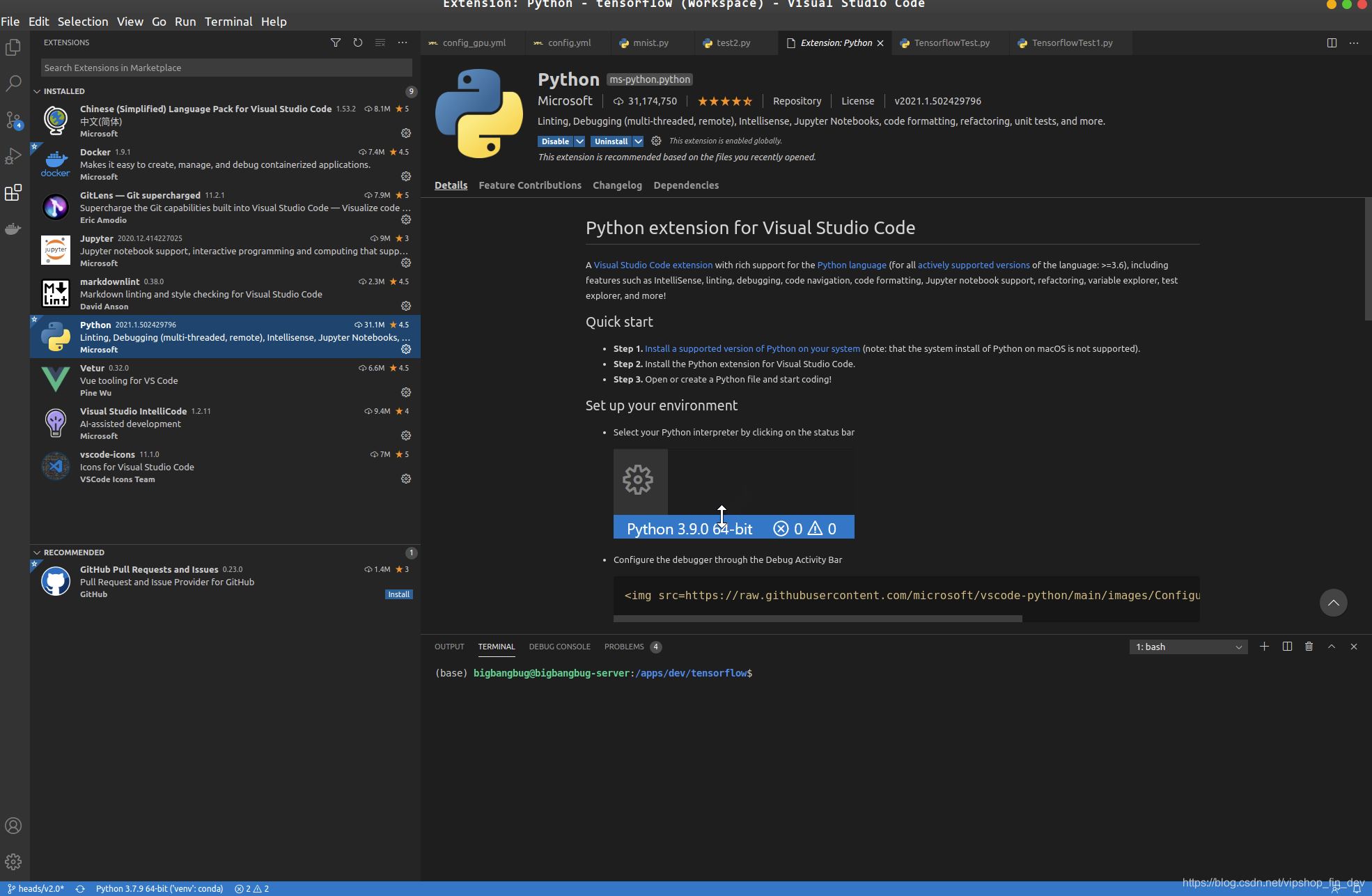 安装完毕后,在左下角一般可以选择前面说到的Conda 虚拟环境,如无则可以使用命命令行 ctrl +p 然后输入命令: (>号不能少)
安装完毕后,在左下角一般可以选择前面说到的Conda 虚拟环境,如无则可以使用命命令行 ctrl +p 然后输入命令: (>号不能少)
>python:select interpreter
选择相应环境或者定位目录
至此,IDE基本已经和Python环境结合起来了,后面就是安装相关的软件包了
4. 常用函数包安装
通常安装软件包,可以直接在VSCode中的“终端”上或者另外打开控制台都行(Windows也可以使用Powershell)。注意要切换到相应的虚拟环境中再进行安装(参考上面的命令)。一般使用pip命令安装会比较简单,机器学习不可或缺的软件包括pandas和scikit-learn:
https://pandas.pydata.org/
https://scikit-learn.org/stable/
# 查看现有包
pip list
# 安装pandas、scikit-learn包
sudo pip install pandas scikit-learn
深度学习TensorFlow包安装
https://tensorflow.google.cn/install/pip
因我们已经安装了Python3,以及切换到了虚拟环境,可以直接跳过官网上的第一第二步,直接到第三步:
sudo pip install --upgrade tensorflow
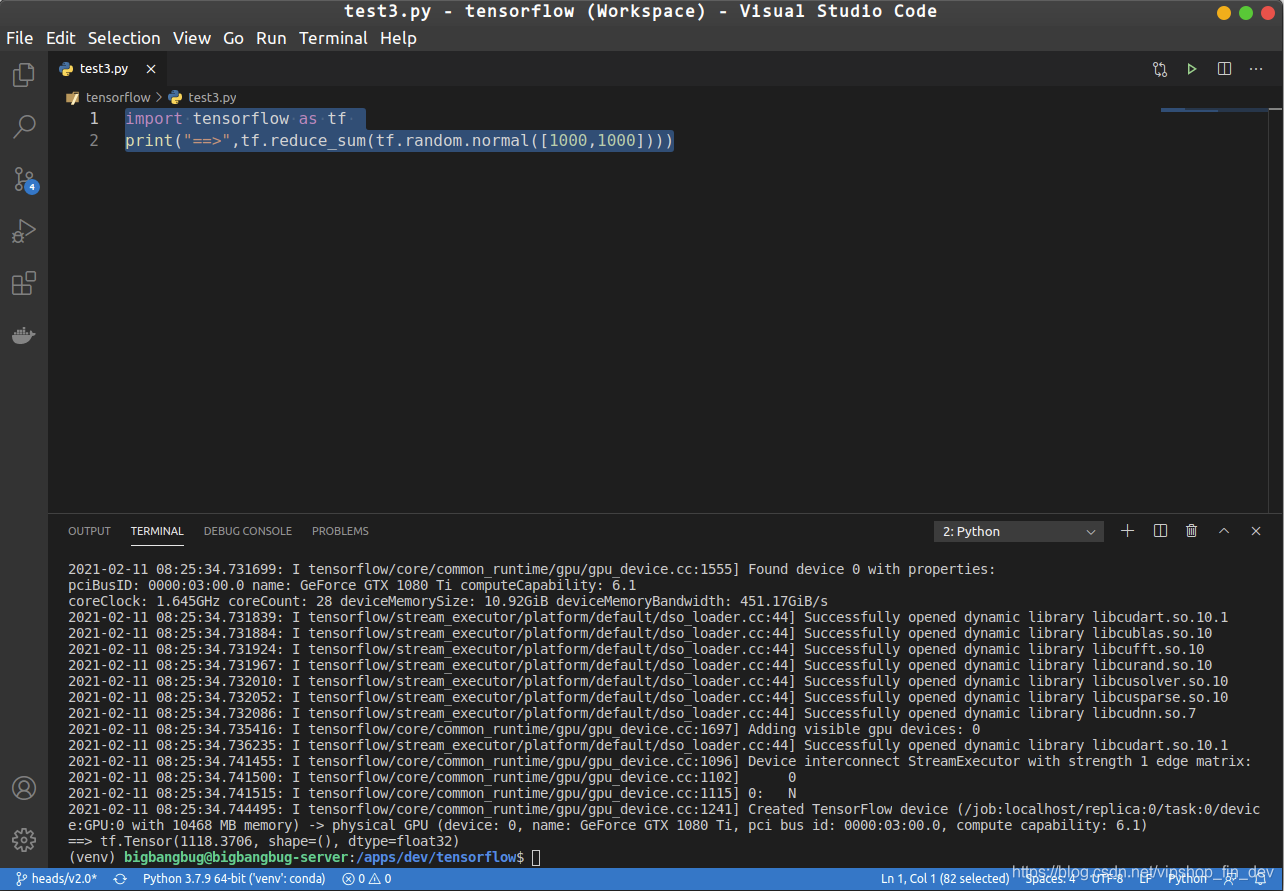
验证安装成功,创建一个空的python文件(例如test3.py),并贴代码:
import tensorflow as tf
print("==>",tf.reduce_sum(tf.random.normal([1000,1000])))
点击运行按钮后,在终端输出结果代表成功:
5. 一个神经网络的例子
我们已完成整个机器学习的开发实验环境,可以在例如TensorFlow官网的Example中进行尝试,也可去kaggle网上尝试别人建立的模型:
https://tensorflow.google.cn/learn
https://www.kaggle.com/
最后我们以一个TensorFlow官网改编的关于影视数据分析的例子结尾:
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
import os
#os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
#os.environ["CUDA_VISIBLE_DEVICES"] = "1" # 使用第二块GPU(从0开始)
imdb = keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
word_index=imdb.get_word_index()
word_index={k:(v+3) for k,v in word_index.items()}
word_index["<PAD>"]=0
word_index["<START>"]=1
word_index["<UNK>"]=2
word_index["<UNUSED>"]=3
print(train_data[0])
train_data=keras.preprocessing.sequence.pad_sequences(train_data,value=word_index["<PAD>"],padding='post',maxlen=256)
test_data=keras.preprocessing.sequence.pad_sequences(test_data,value=word_index["<PAD>"],padding='post',maxlen=256)
vocab_size=10000
model = keras.Sequential([
keras.layers.Embedding(vocab_size, 16),
keras.layers.GlobalAveragePooling1D(),
keras.layers.Dense(16,activation='relu'),
keras.layers.Dense(1,activation='sigmoid'),
])
model.summary()
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
x_val = train_data[:10000]
partial_x_train = train_data[10000:]
y_val = train_labels[:10000]
partial_y_train = train_labels[10000:]
history=model.fit(partial_x_train,partial_y_train, epochs=40,batch_size=512,validation_data=(x_val,y_val),verbose=1)
results = model.evaluate(test_data, test_labels, verbose=2)
print(results)
history_dict = history.history
history_dict.keys()
acc=history_dict['accuracy']
val_acc=history_dict['val_accuracy']
loss=history_dict['loss']
val_loss=history_dict['val_loss']
epochs=range(1,len(acc)+1)
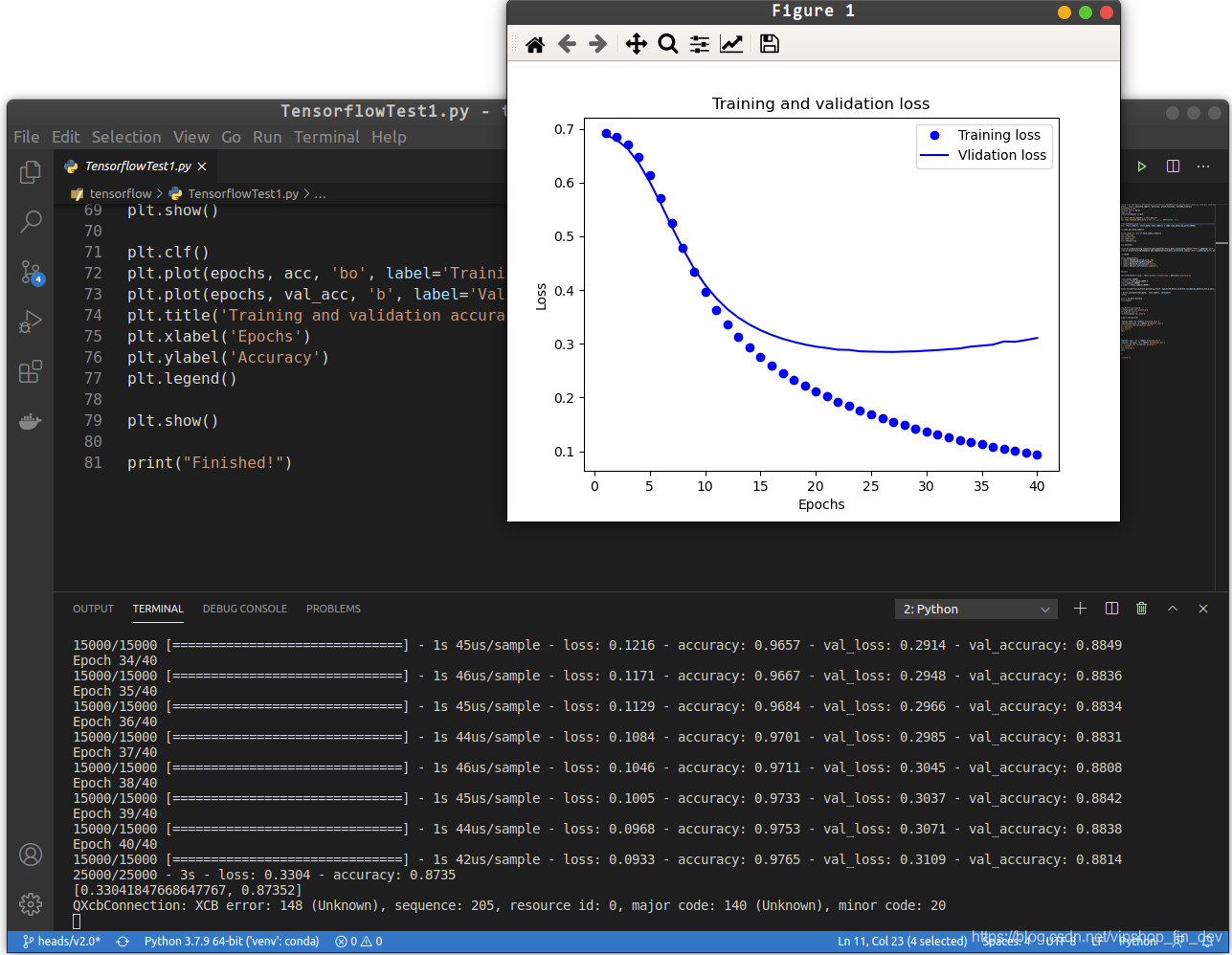
plt.plot(epochs,loss,'bo',label='Training loss')
plt.plot(epochs,val_loss,'b',label='Vlidation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.clf()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
print("Finished!")
作者:侯嘉逊














 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









