









🏡博客主页: virobotics(仪酷智能):LabVIEW深度学习、人工智能博主
🎄所属专栏:『LabVIEW深度学习工具包』『仪酷LabVIEW目标检测工具包实战』
📑上期文章:『仪酷LabVIEW OD实战(1)——目标检测Object Detection工具包的安装』
🍻本文由virobotics(仪酷智能)原创首发🥳欢迎大家关注✌点赞👍收藏⭐留言📝订阅专栏
一、前言
Hello,大家好,我是virobotics(仪酷智能),一个深耕于LabVIEW和人工智能领域的开发工程师。
上一节给大家介绍了仪酷Object Detection工具包的安装,这节我们来看看这个工具包可以帮助我们快速搭建我们的范例的VI具体有哪些,以及具体VI的参数是什么?
二、环境搭建
2.1 部署本项目时所用环境
- 操作系统:Windows系统
- LabVIEW:2018及以上 64位版本
- VIPM :2021及以上版本
- AI视觉工具包(techforce_lib_opencv_cpu):1.0.1.16及以上版本
加速工具包(ONNX、OpenVINO、TensorRT)的至少其中一个
1、ONNX工具包:virobotics_lib_onnx_cpu-1.13.1.8及以上版本 或virobotics_lib_onnx_cuda_tensorrt-1.13.1.15及以上版本
2、OpenVINO工具包(virobotics_lib_openvino):1.0.0.20及以上版本
3、TensorRT工具包(virobotics_lib_tensorrt):1.0.0.36及以上版本 - 仪酷Object Detection工具包:https://blog.csdn.net/virobotics/article/details/132529219
三、Object_Detection VI函数
该插件一共六个vi函数,可帮助用户快速搭建自己的目标检测应用,具体vi介绍如下:

-
IntialModel_Onnx.vi:多态VI,使用onnxruntime推理引擎加载onnx模型并实现初始化。用户可以在该多态vi下拉菜单中选择需要初始化的模型;
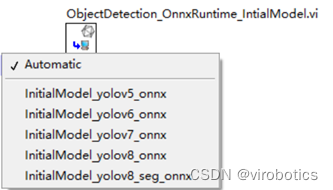
具体参数含义:

- device_id:设备号,可选0、1、2、3等,数字为GPU索引,默认为0;
- type: 推理加速类型,可选CPU、CUDA、TensorRT,默认为CPU
- path:模型路径,默认为空
- class_names_path:对象类别名称文件路径,默认为空
- error in:描述在此VI或函数运行之前发生的错误条件。默认值是没有错误的。
- use_letterbox:用于控制输入图像的缩放和填充方式,默认为True。当 use_letterbox 设置为 True 时,在推理过程中,输入图像将被缩放到固定的尺寸,并在保持图像纵横比的同时进行填充。这通常用于处理输入图像尺寸与模型期望输入尺寸不一致的情况。通过应用 letterbox 缩放和填充,可以确保输入图像的纵横比不变,避免图像形状的扭曲。当 use_letterbox 设置为 False 时,输入图像将根据模型的输入要求进行缩放,但不进行填充。这可能会导致输入图像的纵横比发生变化,但可以更准确地反映原始图像的内容。
- swap rb:如果图像为三通道图片,是否交换Red通道和Blue通道。默认为True。swap rb设置为True,则将读取到的图片的Red通道和Blue通道交换,YOLO模型是在RGB图像上进行推理的。
- yolox_onnx_out:用ONNX工具包推理yolovx的类(x可以为5/6/7/8)
- error out:包含错误信息。如果中的错误指示在此VI或函数运行之前发生了错误,则错误输出包含相同的错误信息。
-
IntialModel_OpenVINO.vi:多态VI,使用OpenVINO推理引擎加载onnx模型并实现初始化。用户可以在该多态vi下拉菜单中选择需要初始化的模型;

具体参数含义:

- device_name:设备名,推理加速类型,可选CPU、GPU,默认为CPU;
- path:模型路径,默认为空
- class_names_path:对象类别名称文件路径,默认为空
- error in:描述在此VI或函数运行之前发生的错误条件。默认值是没有错误的。
- use_letterbox:用于控制输入图像的缩放和填充方式,默认为True。当 use_letterbox 设置为 True 时,在推理过程中,输入图像将被缩放到固定的尺寸,并在保持图像纵横比的同时进行填充。这通常用于处理输入图像尺寸与模型期望输入尺寸不一致的情况。通过应用 letterbox 缩放和填充,可以确保输入图像的纵横比不变,避免图像形状的扭曲。当 use_letterbox 设置为 False 时,输入图像将根据模型的输入要求进行缩放,但不进行填充。这可能会导致输入图像的纵横比发生变化,但可以更准确地反映原始图像的内容。
- swap rb:如果图像为三通道图片,是否交换Red通道和Blue通道。默认为True。swap rb设置为True,则将读取到的图片的Red通道和Blue通道交换,YOLO模型是在RGB图像上进行推理的。
- yolox_openvino_out:用OpenVINO工具包推理yolovx的类(x可以为5/6/7/8)
- error out:包含错误信息。如果中的错误指示在此VI或函数运行之前发生了错误,则错误输出包含相同的错误信息。
-
IntialModel_TensorRT.vi:多态VI,使用OpenVINO推理引擎加载onnx模型并实现初始化。用户可以在该多态vi下拉菜单中选择需要初始化的模型;

具体参数含义:

-
config:包含多个需要配置的元素信息,具体含义如下

-
device_id:设备号,可选0、1、2、3等,数字为GPU索引,默认为0;
-
path:engine模型路径,默认为空
-
class_names_path:对象类别名称文件路径,默认为空
-
error in:描述在此VI或函数运行之前发生的错误条件。默认值是没有错误的。
-
use_letterbox:用于控制输入图像的缩放和填充方式,默认为True。当 use_letterbox 设置为 True 时,在推理过程中,输入图像将被缩放到固定的尺寸,并在保持图像纵横比的同时进行填充。这通常用于处理输入图像尺寸与模型期望输入尺寸不一致的情况。通过应用 letterbox 缩放和填充,可以确保输入图像的纵横比不变,避免图像形状的扭曲。当 use_letterbox 设置为 False 时,输入图像将根据模型的输入要求进行缩放,但不进行填充。这可能会导致输入图像的纵横比发生变化,但可以更准确地反映原始图像的内容。
-
swap rb:如果图像为三通道图片,是否交换Red通道和Blue通道。默认为True。swap rb设置为True,则将读取到的图片的Red通道和Blue通道交换,YOLO模型是在RGB图像上进行推理的。
-
yolox_tensorRT_out:用TensorRT工具包推理yolovx的类(x可以为5/6/7/8)
-
error out:包含错误信息。如果中的错误指示在此VI或函数运行之前发生了错误,则错误输出包含相同的错误信息。
- Detect_1_Batch:使用opencv数据类型图像作为输入,进行模型的预处理和后处理,实现推理,具体参数含义:

- nms_threshold:NMS阈值,用于控制重叠边界框的合并条件,当两个边界框的重叠程度(通常使用IOU,即交并比)超过NMS阈值时,将被视为重叠边界框,并根据一定的规则选择其中一个作为最终的检测结果。较高的NMS阈值会保留更多的检测结果,但可能导致重叠边界框较多。较低的NMS阈值可以更严格地抑制重叠边界框,但可能会导致某些真实目标被错误地丢弃。通常情况下,NMS阈值的取值范围在0到1之间,常见的取值为0.5或0.6。默认为0.5
- confThreshold:置信度阈值,置信度是一个介于0到1之间的概率值,表示模型对边界框所包含目标的置信程度。当某个边界框的置信度大于或等于置信度阈值时,该边界框被认为是有效的检测结果;当置信度小于阈值时,该边界框则被丢弃。通过调整confThreshold的值,可以控制模型对检测结果的准确性和召回率。较高的置信度阈值会提高准确性,但可能会导致一些真实目标被错误地丢弃;较低的置信度阈值则会增加召回率,但可能会引入一些误检测。默认为0.3
- Object_Detection_Utils in:用于推理的类输入
- image:OpenCV数据类型格式图像,是一个Mat
- error in:描述在此VI或函数运行之前发生的错误条件。默认值是没有错误的。
- fontscale:字体缩放因子,用于调整文本或字体的大小比例,一个浮点数值,表示相对于原始字体大小的缩放比例。具体而言,当fontscale的值大于1时,文本将变大;当fontscale的值小于1时,文本将变小。默认为0.5。
- Object_Detection_Utils out:用于推理的类输出,用于后续函数的输入
- results:目标检测结果,包括目标检测框坐标,置信度以及目标检测结果
- img out:带有检测结果的图像Mat索引,用于后续函数的输入
- error out:包含错误信息。如果中的错误指示在此VI或函数运行之前发生了错误,则错误输出包含相同的错误信息。
- Detect_1_Batch_nivison:使用NI Image数据类型图像作为输入,进行模型的预处理和后处理,实现推理,具体参数含义:

- nms_threshold:NMS阈值,用于控制重叠边界框的合并条件,当两个边界框的重叠程度(通常使用IOU,即交并比)超过NMS阈值时,将被视为重叠边界框,并根据一定的规则选择其中一个作为最终的检测结果。较高的NMS阈值会保留更多的检测结果,但可能导致重叠边界框较多。较低的NMS阈值可以更严格地抑制重叠边界框,但可能会导致某些真实目标被错误地丢弃。通常情况下,NMS阈值的取值范围在0到1之间,常见的取值为0.5或0.6。默认为0.5
- confThreshold:置信度阈值,置信度是一个介于0到1之间的概率值,表示模型对边界框所包含目标的置信程度。当某个边界框的置信度大于或等于置信度阈值时,该边界框被认为是有效的检测结果;当置信度小于阈值时,该边界框则被丢弃。通过调整confThreshold的值,可以控制模型对检测结果的准确性和召回率。较高的置信度阈值会提高准确性,但可能会导致一些真实目标被错误地丢弃;较低的置信度阈值则会增加召回率,但可能会引入一些误检测。默认为0.3
- Object_Detection_Utils in:用于推理的类输入
- Image:NI Image控件的数据类型图像的引用
- error in:描述在此VI或函数运行之前发生的错误条件。默认值是没有错误的。
- fontscale:字体缩放因子,用于调整文本或字体的大小比例,一个浮点数值,表示相对于原始字体大小的缩放比例。具体而言,当fontscale的值大于1时,文本将变大;当fontscale的值小于1时,文本将变小。默认为0.5。
- Object_Detection_Utils out:用于推理的类输出
- results:目标检测结果,包括目标检测框坐标,置信度以及目标检测结果
- Image out:经过处理之后的图像的引用输出
- error out:包含错误信息。如果中的错误指示在此VI或函数运行之前发生了错误,则错误输出包含相同的错误信息。
- Release:推理结束,释放模型。

- Object_Detection_Utils in:用于推理的类输入
- Object_Detection_Utils out:用于推理的类输出
- error in:描述在此VI或函数运行之前发生的错误条件。默认值是没有错误的。
- error out:包含错误信息。如果中的错误指示在此VI或函数运行之前发生了错误,则错误输出包含相同的错误信息。
四、工具包获取方式
如需改插件工具包,可关注微信公众号:VIRobotics ,回复关键字:目标检测插件
总结
以上就是今天要给大家分享的内容,希望对大家有用。如有笔误,还请各位及时指正。后续还会继续给各位朋友分享其他案例,欢迎大家关注博主。我是virobotics(仪酷智能),我们下篇文章见~
如您想要探讨更多关于LabVIEW与人工智能技术,欢迎加入我们的技术交流群:705637299。进群请备注:CSDN
如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏
推荐阅读
LabVIEW图形化的AI视觉开发平台(非NI Vision),大幅降低人工智能开发门槛
LabVIEW图形化的AI视觉开发平台(非NI Vision)VI简介
LabVIEW AI视觉工具包OpenCV Mat基本用法和属性
手把手教你使用LabVIEW人工智能视觉工具包快速实现图像读取与采集
👇技术交流 · 一起学习 · 咨询分享,请联系👇
















 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











