






🏡博客主页: virobotics(仪酷智能):LabVIEW深度学习、人工智能博主
🎄所属专栏:『仪酷LabVIEW目标检测工具包实战』
📑上期文章:『仪酷LabVIEW OD实战(4)——Object Detection+OpenVINO工具包快速实现yolo目标检测』
🍻本文由virobotics(仪酷智能)原创首发🥳欢迎大家关注✌点赞👍收藏⭐留言📝订阅专栏
文章目录
一、前言
Hello,大家好,我是virobotics(仪酷智能),一个深耕于LabVIEW和人工智能领域的开发工程师。
今天我们给大家详细介绍一下Object Detection+TensorRT工具包快速实现yolo目标检测。
二、环境搭建
2.1 部署本项目时所用环境
-
操作系统:Windows系统64位
-
LabVIEW:2018及以上 64位版本
-
VIPM :2021及以上版本
-
AI视觉工具包(techforce_lib_opencv_cpu):1.0.1.17及以上版本
-
TensorRT工具包(virobotics_lib_tensorrt)1.0.0.48及以上版本
-
仪酷Object Detection工具包(virobotics_lib_object_detection):1.0.0.5及以上版本
2.2 LabVIEW工具包下载及安装
- AI视觉工具包下载与安装参考:
https://blog.csdn.net/virobotics/article/details/123656523 - TensorRT工具包下载与安装参考:
https://blog.csdn.net/virobotics/article/details/129304465 - 仪酷Object Detection工具包下载与安装参考:
https://blog.csdn.net/virobotics/article/details/132529219
三、项目实战
3.1 快速打开范例
-
双击打开LabVIEW,在“Help”选项下找到“Find Examples…”单击打开。

-
打开范例查找器,选择Directory Structure–VIRobotics AI Vision–Object Detection即可获取所有的范例。不同模型的范例,放到了不同文件夹下。

-
以YOLOv5相关范例为例,双击“yolov5”范例文件夹,双击想要运行的vi(若您电脑当前无法使用相机,建议加载名字含有“imgs”的vi范例)。

(注意:范例VI名字中带有onnx表示该范例使用ONNX工具包实现推理;范例VI名字中带有openvino表示该范例使用OpenVINO工具包实现推理;范例VI名字中带有trt表示该范例使用TensorRT工具包实现推理;您可根据您目前已经安装的工具包来打开对应范例。范例VI中带有nivision表示使用NI VISION方式进行图像采集并实现推理,如您预计使用官方NI VISION来采集图像,则可使用此范例。不带有nivision则表示使用仪酷工具包进行图像采集或图像读取来实现推理。)
- 若您电脑没有安装NI VISION工具包,则在打开范例过程中会出现如下图所示弹窗,一直点击“Ignore Item”即可,或者直接点击Ignore All。

3.2 加载yolo模型实现推理
范例VI名字中带有
trt表示该范例使用OpenVINO工具包实现推理
3.2.1 实时检测推理
- 以yolov8_seg为例(其他范例相似),先将onnx模型转化为tensorRT所使用的engine模型,可使用如下下载地址范例来实现模型的转换: https://pan.baidu.com/s/1-LXmaDYMNGMY1LyGa6FhUg?pwd=yiku,电脑显卡不同,engine模型不同,所以不同电脑之间engine模型不可以共用。
- 转化完毕后,关闭所有LabVIEW程序;一定要先完全关闭LabVIEW,再加载模型,否则会出现程序卡死等异常;
- 快速打开范例,双击yolov8_seg文件夹,双击yolov8_seg_trt.vi,会直接打开前面板(Front Panel),选择刚刚转化好engine模型文件(默认保存在路径:C:\ProgramData\VIRobotics\ModelZoo\Object_Detection\yolov8_seg\onnx_model 下),点击运行,程序会直接加载yolov8_seg模型及分类文件,开启摄像头实现实例分割。

- 若需要停止本次检测,点击“STOP”按钮控件即可。
- 如果想要加载自己训练好的模型,则可按照如下步骤进行设置
① 先将自己已经训练好的onnx模型转化为tensorRT所使用的engine模型,可使用如下下载地址范例来实现模型的转换: https://pan.baidu.com/s/1-LXmaDYMNGMY1LyGa6FhUg?pwd=yiku ,转换过程需要将onnx及engine模型的路径改为实际路径(不可包含中文),电脑显卡不同,engine模型不同,所以不同电脑之间engine模型不可以共用;
② 转化完毕后,关闭所有LabVIEW程序;一定要先完全关闭LabVIEW,再加载模型,否则会出现程序卡死等异常;
③ 查看转换之前的onnx模型的输入大小以及类别,可使用网址:https://netron.app/ 来查看;
④ 加载已经转化好的的engine模型;
⑤ 加载模型对应的类别文件class_names_file(默认加载官方模型类别文件);
⑥ 设置imageSize及inputSize中的x,y为模型的输入大小(比如640,640或者1280,1280);
⑦ 设置class_number,即需要识别的类别数目;
⑧ 全部设置完毕,点击运行,即可实现实时检测。
⑨ 需要停止本次检测,点击“STOP”按钮控件即可。
程序框图如下图所示:
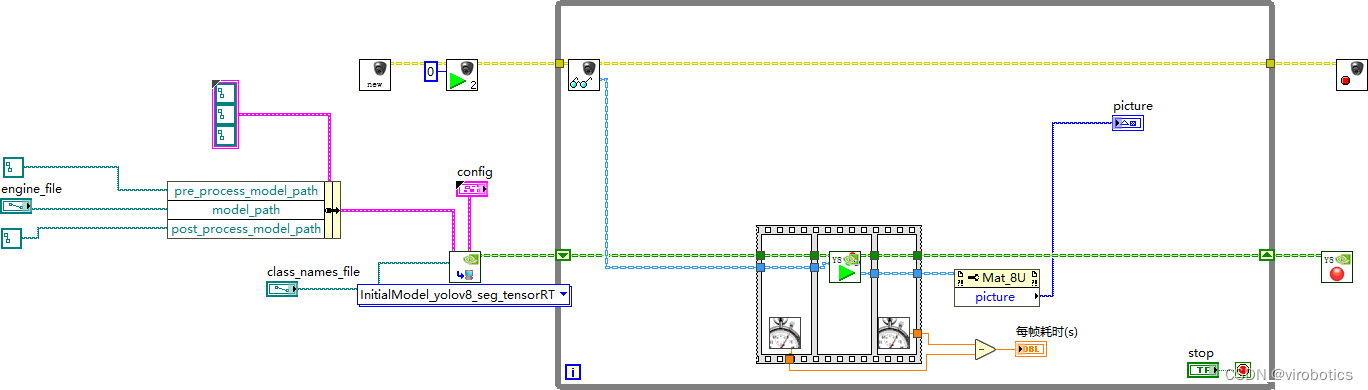
3.2.2 实现图片集推理检测
- 以yolov8_seg为例(其他范例相似),做如下操作:
① 先将onnx模型转化为tensorRT所使用的engine模型,可使用如下下载地址范例来实现模型的转换: https://pan.baidu.com/s/1-LXmaDYMNGMY1LyGa6FhUg?pwd=yiku,电脑显卡不同,engine模型不同,所以不同电脑之间engine模型不可以共用。
② 转化完毕后,关闭所有LabVIEW程序;一定要先完全关闭LabVIEW,再加载模型,否则会出现程序卡死等异常;
③ 快速打开范例,双击yolov8_seg文件夹,双击yolov8_seg_trt_imgs.vi,会直接打开前面板(Front Panel),选择刚刚转化好engine模型文件(默认保存在路径:C:\ProgramData\VIRobotics\ModelZoo\Object_Detection\yolov8_seg\onnx_model 下),点击运行,启动程序,将会加载默认图片集;
④ 单击界面右侧imgs控件中需要进行检测的图片,即可实现图片检测;
⑤ 如下图所示为检测结果,需要停止本次检测,点击“STOP”按钮控件即可。

- 如果想要加载自己训练好的模型,则可按照如下步骤进行设置
① 先将自己已经训练好的onnx模型转化为tensorRT所使用的engine模型,可使用如下下载地址范例来实现模型的转换: https://pan.baidu.com/s/1-LXmaDYMNGMY1LyGa6FhUg?pwd=yiku ,转换过程需要将onnx及engine模型的路径改为实际路径(不可包含中文),电脑显卡不同,engine模型不同,所以不同电脑之间engine模型不可以共用;
② 转化完毕后,关闭所有LabVIEW程序;一定要先完全关闭LabVIEW,再加载模型,否则会出现程序卡死等异常;
③ 查看转换之前的onnx模型的输入大小以及类别,可使用网址:https://netron.app/ 来查看;
④ 加载已经转化好的的engine模型;
⑤ 加载模型对应的类别文件class_names_file(默认加载官方模型类别文件);
⑥ 设置imageSize及inputSize中的x,y为模型的输入大小(比如640,640或者1280,1280);
⑦ 设置class_number,即需要识别的实际类别数目;
⑧ 全部设置完毕,点击运行,启动程序;
⑨ 选择并加载需要识别检测的图片数据集;
⑩ 单击界面右侧imgs控件中需要进行检测的图片,即可实现图片检测;
⑪ 需要停止本次检测,点击“STOP”按钮控件即可。
💡一些小技巧:
我们可以通过设置置信度阈值confThreashold(默认为0.3)和NMS阈值nms_threshold(默认为0.5)来控制检测结果,较高的置信度阈值和较低的NMS阈值可以提高结果的准确性,但可能会导致漏检和冗余检测。较低的置信度阈值和较高的NMS阈值可以增加检测结果,但可能会引入更多的误检和重复检测。因此,可以需要根据实际场景和性能要求调整这些阈值,即如下图所示中的Detect_1_Batch.vi中可进行参数设置;
可以设置Detect_1_Batch.vi中的fontscale,即字体缩放因子,用于调整文本或字体的大小比例,该参数是一个浮点数值,表示相对于原始字体大小的缩放比例。具体而言,当fontscale的值大于1时,文本将变大;当fontscale的值小于1时,文本将变小。默认为0.5;
如果想要获取检测结果,可以在函数Detect_1_Batch.vi输出results中获取相对应结果;

四、工具包获取方式
如需该插件工具包,可查看:https://blog.csdn.net/virobotics/article/details/132529219
总结
以上就是今天要给大家分享的内容,希望对大家有用。如有笔误,还请各位及时指正。
至此关于仪酷Object Detecrion工具包的大致内容就给大家介绍完了,后续还会给大家介绍一些更多关于此工具包的详细内容。
欢迎大家关注博主。我是virobotics(仪酷智能),我们下篇文章见~
如您想要探讨更多关于LabVIEW与人工智能技术,欢迎加入我们的技术交流群:705637299。进群请备注:CSDN
如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏
系列文章链接:
仪酷LabVIEW OD实战(1)——目标检测Object Detection工具包的安装
仪酷LabVIEW OD实战(2)——Object Detection VI函数详细介绍
仪酷LabVIEW OD实战(3)——Object Detection+onnx工具包快速实现yolo目标检测
仪酷LabVIEW OD实战(4)——Object Detection+OpenVINO工具包快速实现yolo目标检测
推荐阅读
LabVIEW图形化的AI视觉开发平台(非NI Vision),大幅降低人工智能开发门槛
LabVIEW图形化的AI视觉开发平台(非NI Vision)VI简介
LabVIEW AI视觉工具包OpenCV Mat基本用法和属性
手把手教你使用LabVIEW人工智能视觉工具包快速实现图像读取与采集
👇技术交流 · 一起学习 · 咨询分享,请联系👇
















 1448
1448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











