







C#调用python导出的onnx模型
写在前面
本文通过python导出回归预测模型为onnx格式,然后通过c#进行调用,本篇重点是c#调用的方式,关于python如何导出Onnx模型详见钥匙君另一篇文章:python成功导出Onnx模型
开炮!开炮!
1.导入拓展包
拓展包没那么复杂,直接上Nutget,前面两项打钩的
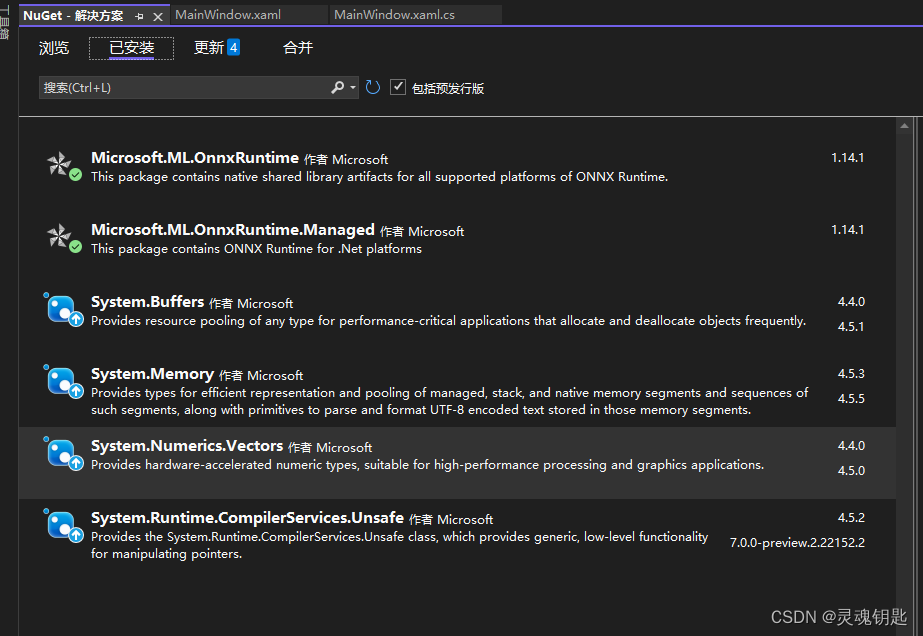
2.导入onnx模型
将导出的onnx模型放置于Debug文件夹下做准备
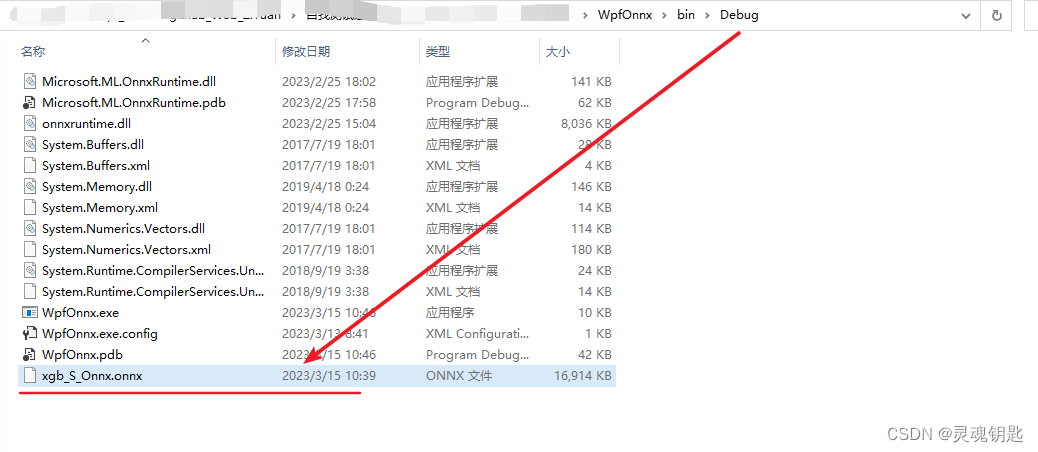
导入onnx模型,这里就是根目录下第一步放置的,这里定义一个输入
string modelFilePath = @".\xgb_S_Onnx.onnx";
// 定义模型的输入
float[] inputData = new float[] { 2, 54, 1, 1, 1 };
//List<float> inputData = new List<float>();
3.导入onnx关键代码解读
定义SessionOptions,这里使用cpu进行运算时调用
SessionOptions options = new SessionOptions();
options.LogSeverityLevel = OrtLoggingLevel.ORT_LOGGING_LEVEL_INFO;
options.AppendExecutionProvider_CPU(0);
这里的inputMeta将包括Key为“flaot_input",这也是在python中定义好的,如果不清楚可以去看一下上一篇文章:python成功导出Onnx模型
将 input_tensor 放入一个输入参数的容器,并指定名称,这里主要是因为c#在读取外部data的一些规定,NamedOnnxValue可以理解为在c#的onnxruntime读取数值都是以这种类型进行传递的
var inputMeta = _onnxSession.InputMetadata;
var container = new List<NamedOnnxValue>();
对于inputMeta中的每一个Key,这里只有一个key就是“flaot_input",name也在循环中被赋予“flaot_input"
container.Add是不是很熟悉,有点类似于字典,添加了(name, tensor)也就是添加了
“flaot_input",{{2,54,1,1,1}}
此时的tensor就是{{2,54,1,1,1}},inputMeta[name].Dimensions是2,因为输入是1x5的,所以Dimensions其中1个是1,1个是5,表示输入的维度是[1,5]
foreach (var name in inputMeta.Keys)
{
var tensor = new DenseTensor<float>(inputData, inputMeta[name].Dimensions);
container.Add(NamedOnnxValue.CreateFromTensor<float>(name, tensor));
}
运行 Inference 并获取结果
这里注意resultsArray的类型是onnx_tensor不能直接转为float[],因此这里需要调用函数进行处理,将resultsArray的数组提取出来,通过AsEnumerable()结合ToArray()方法来实现,这个shuchu就是我们预测得到的一个1x112的数组
IDisposableReadOnlyCollection<DisposableNamedOnnxValue> results = _onnxSession.Run(container);
//将resultsArray变为数组
var resultsArray = results.ToArray();
float[] shuchu = resultsArray[0].AsEnumerable<float>().ToArray();
//Console.WriteLine(shuchu.Length);
4.完整代码
public MainWindow()
{
InitializeComponent();
string modelFilePath = @".\xgb_S_Onnx.onnx";
float[] inputData = new float[] { 2, 54, 1, 1, 1 };
SessionOptions options = new SessionOptions();
options.LogSeverityLevel = OrtLoggingLevel.ORT_LOGGING_LEVEL_INFO;
options.AppendExecutionProvider_CPU(0);
InferenceSession _onnxSession = new InferenceSession(modelFilePath, options);
var inputMeta = _onnxSession.InputMetadata;
var container = new List<NamedOnnxValue>();
foreach (var name in inputMeta.Keys)
{
var tensor = new DenseTensor<float>(inputData, inputMeta[name].Dimensions);
container.Add(NamedOnnxValue.CreateFromTensor<float>(name, tensor));
}
IDisposableReadOnlyCollection<DisposableNamedOnnxValue> results = _onnxSession.Run(container);
var resultsArray = results.ToArray();
float[] shuchu = resultsArray[0].AsEnumerable<float>().ToArray();
}


















 1732
1732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









