







在深度生成模型中,采样(Sampling)指的是根据模型生成新样本的过程。在扩散模型(Diffusion Models)中,采样的关键是从高斯噪声逐步还原出原始数据。让我们分别探讨 DDPM 和 DDIM 的采样过程,以及两者之间的差异。
DDPM(Denoising Diffusion Probabilistic Models)中的采样
基本概念
-
前向扩散过程(Forward Diffusion Process)
- 从真实数据
开始,逐步添加高斯噪声生成一系列中间状态
,直到最终变为近似纯噪声
。
- 这一过程可以用公式描述为:
, 其中
是控制每步添加噪声量的参数。
- 从真实数据
其中,只有参数 是可调的。
是根据
计算出的变量,其计算方法为:
,
.
为了能直接使用预训练的DDPM,我们希望在改进DDPM时不更改DDPM的训练过程。而经过简化后,DDPM的训练目标只有拟合x₀,训练时只会用到前向过程公式, 所以,我们的改进应该建立在公式
完全不变的前提下。 换中写法:
参考:DDIM 简明讲解与 PyTorch 实现:加速扩散模型采样的通用方法 - 知乎
-
逆向去噪过程(Reverse Denoising Process)
- 从纯噪声
- 理论上需要学习真实逆过程的条件分布
,但实际中近似为高斯分布:
, 其中
和
是由神经网络预测的参数。
- 从纯噪声
-
采样过程
- 逐步去噪:从纯噪声
。
- 全步骤采样:完整还原
- 逐步去噪:从纯噪声
DDIM(Denoising Diffusion Implicit Models)中的采样
DDIM 是对 DDPM 采样过程的改进,目标是在不重新训练模型的前提下,加速采样并控制生成的灵活性。
主要创新
-
确定性采样(Deterministic Sampling)
- 在 DDIM 中,假设逆向过程是一个确定性映射,而不是像 DDPM 那样的随机采样。
- 给定
,直接计算
, 其中
是从当前状态推断的原始数据,
是噪声估计。
-
跳步采样(Non-Markovian Sampling)
- 在 DDPM 中,采样是逐步进行的(每步对应一个时间步
)。而在 DDIM 中,允许直接跳过中间时间步,从而减少采样步骤。
- 通过选择一个子集
(通常
),只对这些时间步进行采样,显著提升采样速度。
- 在 DDPM 中,采样是逐步进行的(每步对应一个时间步
采样的效果
- DDIM 的采样是确定性的,这意味着在每一步中,模型会根据当前的噪声图像和预测的噪声,直接计算出前一步的图像,而不是像DDPM(Denoising Diffusion Probabilistic Models)那样依赖于随机噪声。
- 通过减少采样步数(比如从 1000 步减少到 20 步),采样速度可以提升约 50 倍,同时尽可能保留生成质量。
DDPM 和 DDIM 的采样对比
| 特性 | DDPM | DDIM |
|---|---|---|
| 采样类型 | 随机(Stochastic) | 确定性(Deterministic) |
| 采样步数 | 多步(通常 1000+ 步) | 少步(比如 20-50 步) |
| 采样速度 | 慢 | 快 |
| 生成质量 | 高(取决于步数) | 质量保持较好 |
| 灵活性 | 不支持跳步 | 支持跳步和方差调整 |
总结
- 采样的意义:
在扩散模型中,采样是指从纯噪声逐步生成新的样本数据。这个过程模拟了数据从无序到有序的生成过程。 - DDPM 的采样:随机逐步还原,计算开销大但生成质量高。
- DDIM 的采样:通过确定性映射和跳步策略,大幅提升采样速度,同时在不重新训练模型的前提下保持生成质量。
LOSS:
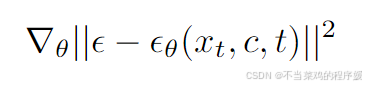
the objective of diffusion model is simplified to predicting the true noise ε from Eq. 1 when xt is fed as input with additional inputs like the timestep t and conditioning c.
DDPM, DDIM, stable diffusion 和 LDM 发展历程的概述:
-
DDPM (Denoising Diffusion Probabilistic Models):
- DDPM是扩散模型的早期形式,它通过逐步去噪的方式生成高质量数据,但其效率较低,特别是在处理高分辨率图像时需要耗费大量的计算资源。(没有任何的引导生成技术的出现,这一阶段的论文都属于利用输入图像引导生成的范式。)
-
DDIM (Denoising Diffusion Implicit Models):
- DDIM是DDPM的改进版本,通过设计非马尔科夫链的扩散过程,提出了一种加速采样的技巧(Respacing),从而加快了模型的推理速度。
-
LDM (Latent Diffusion Models):
- LDM进一步发展了扩散模型,通过在低维潜在空间进行扩散过程,极大地减少了计算资源的需求。相比DDPM,LDM在推理速度上有了显著提升,特别是在处理高分辨率图像时,这种优势更加明显。
-
Stable Diffusion:
- Stable Diffusion是基于LDM发展而成的强大的文生图大模型,它采用了更加稳定、可控和高效的方法来生成高质量图像。Stable Diffusion在生成图像的质量、速度和成本上都有显著的进步,因此该模型可以直接在消费级显卡上实现图像生成。
综上所述,从DDPM到DDIM,再到LDM,最后到Stable Diffusion,这些模型的发展体现了扩散模型在图像生成领域的不断进步和优化。每一步的发展都在提高生成效率、降低计算成本以及提升图像质量方面做出了贡献。

















 877
877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









