






目录
报错代码
这是报错代码,想要将xlsx文件中的full_name拆分成名和姓,并进行邮件发送:
full_name = row['Name']
# Convert the full name to email format
first_name, last_name = full_name.split()
email_name = f'{first_name.lower()}.{last_name.lower()}'
to_email = f'{email_name}@gmail.com'
遇到如下报错:
first_name, last_name = full_name.split()
ValueError: not enough values to unpack (expected 2, got 1)df['Name'] = df['Name'].astype(str)
报错原因:
这是原本的xlsx文件,有很多空字符,而full_name.split()函数是用空格拆分 full_name 字符串,并将结果部分分配给 first_name 和 last_name 变量。
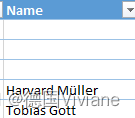
但是,对于 DataFrame 中的某些行,“Name”列仅包含一个单词(或没有空格,完全为空),导致 split() 返回的列表中只有一个元素。
所以在这种情况下,尝试将其解包为两个变量(first_name 和 last_name)会引发 ValueError。
要处理此问题,需要添加一个条件来检查拆分操作是否在解包之前产生多个元素。
修改方案:
full_name = row['Name']
name_parts = full_name.split()
if len(name_parts) > 1:
first_name, last_name = name_parts
else:
# Handle the case when there's only one name or no name
first_name = name_parts[0] if name_parts else ''
last_name = ''
email_name = f'{first_name.lower()}.{last_name.lower()}' if first_name else ''
to_email = f'{email_name}@gmail.com'
我们首先使用 split() 将 full_name 拆分为 name_parts 列表。
- 如果 name_parts 的长度大于 1,则表示有姓和名,因此我们可以像以前一样解包它们。
- 如果 name_parts 的长度为 1 或 0,则表示只有一个名字或根本没有名字。
在这种情况下,我们将 name_parts 的第一个元素(如果存在)分配给 first_name,并将 last_name 设置为空字符串。
最后,我们使用 first_name 和 last_name 构造 email_name,但前提是 first_name 不为空。
















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









