







作者:voiceless_Li
主页:我的主页[添加链接描述](https://blog.csdn.net/voiceless_Li?type=blog)
学习方向:网络安全,python
作者寄语:这是我的第一篇文章,也是一个刚入门计算机半年的小白,初来乍到,请多指教!
每日清醒:在这个繁杂的世界中,保持高级清醒,明确自己的方向。
分享内容:Python网络爬虫
我的专业方向是网络安全,也是我十分热爱的专业,业余时间会学习python,写一些好玩的python脚本,我大一,刚入门计算机半年,其实我想了很久,我的第一篇文章到底要发什么,最后分享一些有趣的python脚本,前几篇文章我会用python语言写一些脚本分享出来(我会把代码过程和解析写得尽量清晰易懂,若有错误,还请指正),后面就会开始分享一些网络安全方面的内容,以此来记录我在大学的学习历程。
本篇的网络爬虫我用的是python语言来写的,这也是写爬虫最常用的一种语言,当然其他语言也能写,但可能会有些麻烦
一般来说,网页上的内容,所见皆可爬,爬虫都能解决,但这篇文件仅分享最简单的入门的爬虫技术,能爬的网站也有着局限性,如果大家想学的话,以后有机会的话我也会分享一些相对进阶一些的内容,毕竟太难的我也没学到哈哈
一、网络爬虫是什么?
网络爬虫是一种自动化的程序或脚本,通过脚本或程序在网站上自动化获取信息,也可以在网络上进行网页、图片、视频的批量下载,但网络爬虫也有相应的爬取规则,也就是robots协议,原则上来说爬取的内容需要遵循robots协议,网络爬虫的应用场景也非常广泛,例如搜索引擎中的网页抓取、数据挖掘、网站监测等领域,网络爬虫的工作流程包括网页源代码、解析网页内容、存储数据等步骤。常见的网络爬虫包括:通用爬虫、聚焦爬虫、增量式爬虫。
二、使用步骤:
搜索引擎:Google
环境:python环境
工具:pycharm
确认网站目标:
网站:www.baidu.com

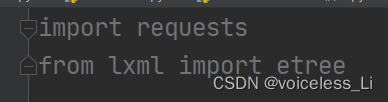
1.导入模块
导入requests模块和etree模块
requests模块用来向网站发请求,etree模块用来定位爬取内容的位置
2.创建对象:

实例化url和headers
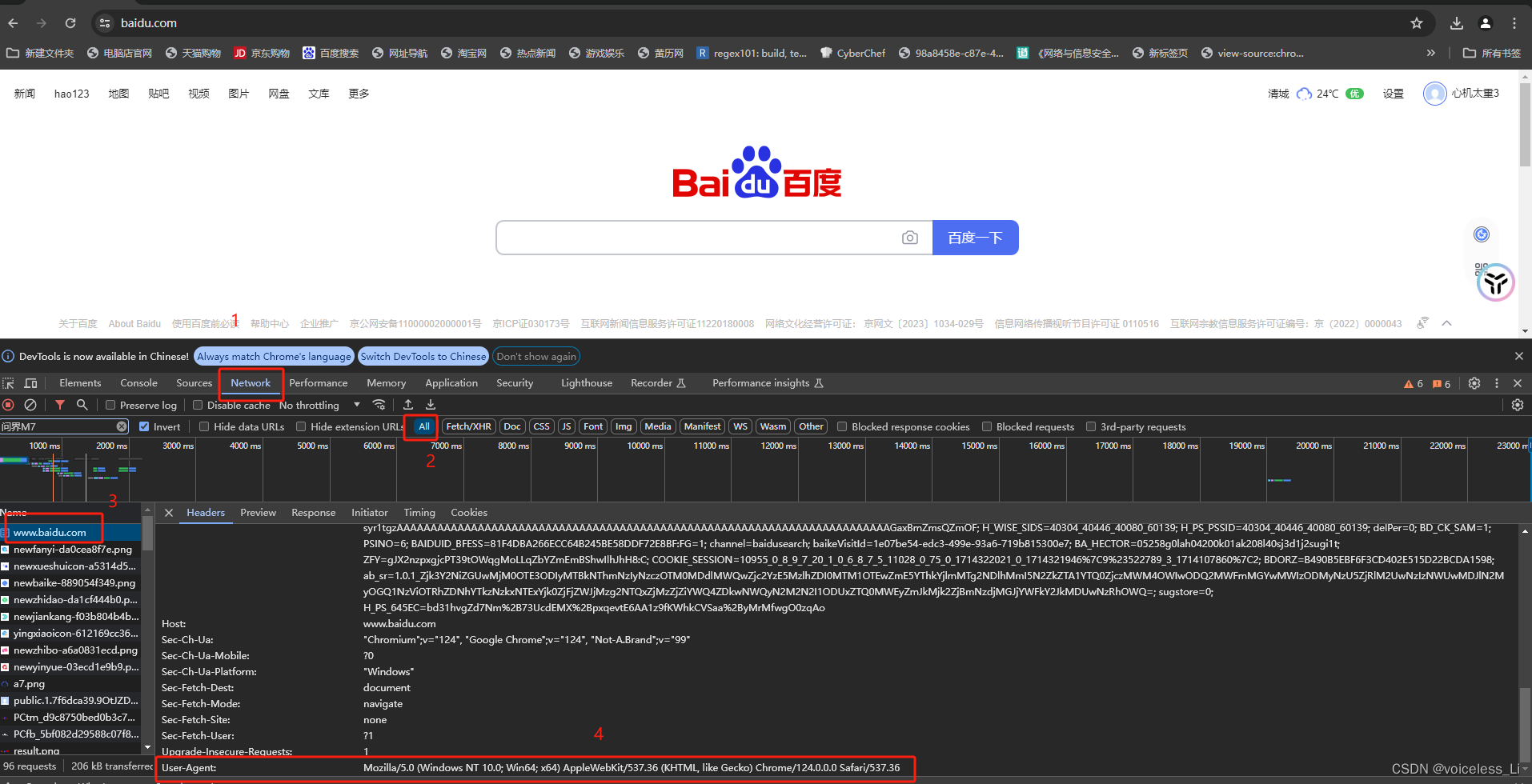
headers怎么获取?
单机鼠标右键,点击检查,然后按照以下步骤就能找到了
3.获得网页HTML源码
创建一个get_url函数,向网站发请求,获取网站HTML源码。

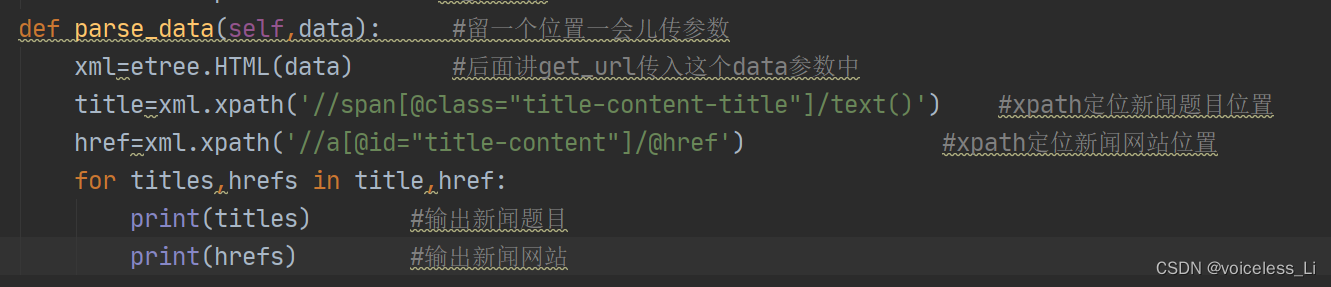
4.爬取数据
如果有不了解xpath用法的朋友,可以先在百度上查一下相关用法再看下面这里哦
5.运行
6.代码展示
import requests
from lxml import etree
class Baidu():
def __init__(self):
self.url='https://www.baidu.com/' #导入url,实例化
self.headers={
'User - Agent':'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 124.0.0.0Safari / 537.36'
} #导入headers,实例化
def get_url(self):
response=requests.get(self.url,headers=self.headers) #向网站发请求,得到网站响应数据response
return response.text #返回数据
def parse_data(self,data): #留一个位置一会儿传参数
xml=etree.HTML(data) #后面将get_url传入这个data参数中
title=xml.xpath('//span[@class="title-content-title"]/text()') #xpath定位新闻题目位置
href=xml.xpath('//a[@id="title-content"]/@href') #xpath定位新闻网站位置
for titles,hrefs in title,href:
print(titles) #输出新闻题目
print(hrefs) #输出新闻网站
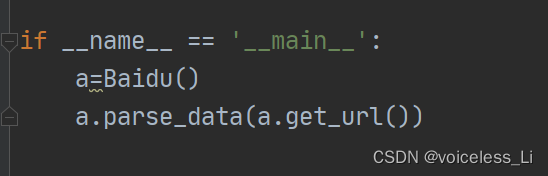
if __name__ == '__main__':
a=Baidu()
a.parse_data(a.get_url())
ps:这只是最简单的一种爬虫技术,但是在网站日益安全的今天,反爬手段越来越完善,爬虫技术越来越难,写好代码写好之后不要经常反复运行,如果网站监测到了,会封IP,如果非要爬取的话,可以在网上购买IP代理,普遍价格不贵,例如:快代理,芝麻代理等。
















 60万+
60万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









