



 本文详细介绍了白盒测试的原理、分类及各种覆盖标准,包括语句覆盖、判定覆盖、条件覆盖、条件-判定覆盖和条件组合覆盖。强调了路径覆盖的重要性以及在循环和数据流测试中的策略。此外,还提到了突变测试作为衡量测试质量的手段。
本文详细介绍了白盒测试的原理、分类及各种覆盖标准,包括语句覆盖、判定覆盖、条件覆盖、条件-判定覆盖和条件组合覆盖。强调了路径覆盖的重要性以及在循环和数据流测试中的策略。此外,还提到了突变测试作为衡量测试质量的手段。
目录
概念
特征
- 白盒测试(white-box testing)是一种核实技术,是软件工程师用来检查其代码是否符合预期
- 它考虑系统或组件内部的机制
- 白盒测试又称为structural testing,clear box testing,glass box testing
- 它表示测试者对软件内部工作有足够的可见性,尤其是逻辑和代码的结构
分类
- 白盒测试分为静态测试(static testing)和动态测试(dynamic testing)
- 静态白盒测试方法:代码检查法、静态结构分析法、静态质量度量法等。
- 动态白盒测试是基于覆盖的测试,尽可能覆盖程序的结构特性和逻辑路径。
- 白盒测试主要用于单元测试。
应遵守的规则
- 路径:一个模块的独立路径至少被实现一次
- 逻辑值:一个逻辑值需要测试两个例子:true false
- 数据结构:检查内部数据结构的程序,确保其结构的有效性。
- 循环:在操作范围内运行所有循环。
困难
- 有多个分支和循环时,根据乘法原理选择数过多,如果进行穷举测试,将花费非常恐怖的时间。
- 实现遍历且不重复,白盒测试不适合穷举
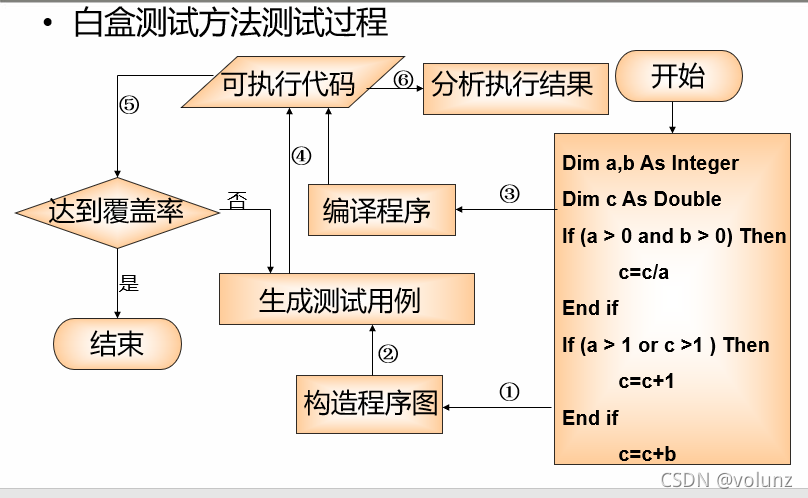
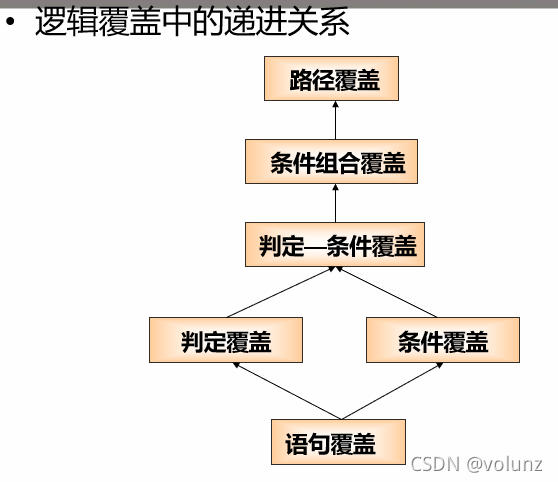
逻辑覆盖(Logic coverage)
- 逻辑覆盖是通过对程序逻辑结构的遍历实现程序的覆盖。
- 是以程序内部的逻辑结构为基础的测试用例设计方法。
- 白盒测试作为逻辑测试方法,是以程序内部逻辑驱动的单元测试方法。|
逻辑覆盖方法:
- Statement coverage 语句覆盖
- Decision coverage 判定覆盖
- Condition coverage 条件覆盖
- Condition/decision coverage 条件-判定覆盖
- Condition combination coverage 条件组合覆盖
- Path coverage 路径覆盖
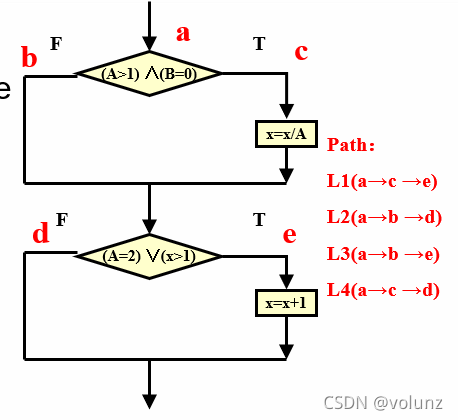
语句覆盖(Statement coverage)
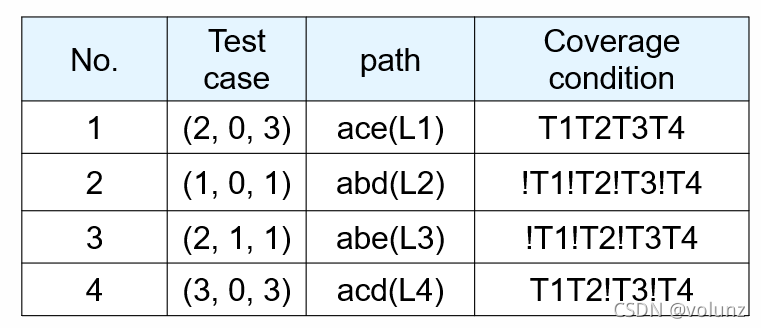
定义:使每个可执行语句至少实现一次。只需一条测试用例,覆盖所有可执行语句(上半部分取真,下半部分取真),即L1(ace)的(2,0,3)是一条语句覆盖的测试用例。
缺点:不能发现判断中的逻辑操作错误 。如果改变测试条件(且和或互换,x>1改成x>0),刚才的测试用例仍然可以覆盖全部语句并且无法发现错误。
语句覆盖和路径覆盖的区别
1、度量对象
语句覆盖:程序中每一可执行语句
路径覆盖:程序中每条路径
2、覆盖程度
语句覆盖:语句覆盖常常被人指责为“最弱的覆盖”,它只管覆盖代码中的执行语句,却不考虑各种分支的组合等等。假如只要求达到语句覆盖,那么换来的确实测试效果不明显,很难更多地发现代码中的问题。
路径覆盖:在白盒测试法中,覆盖程度最高的就是路径覆盖,因为其覆盖程序中所有可能的路径。
判定覆盖(Decision coverage)
定义:设计很多测试用例,使每个判断的真分支和假分支至少经历过一次。
- 除双值判断语句外,还有多值判断语句,如Case语句。
- 判定分支覆盖更一般的含义是:使每个判定获得一种可能的结果至少一次。
- 决策覆盖率并不能保证他们能在判断中发现错误的情况 ,改变条件可能仍然测试结果不变

条件覆盖(Condition coverage)
定义:使过程中每个条件的可能值至少实现一次。
个人理解:判定覆盖聚焦判断菱形两边是否走过,条件覆盖聚焦判断菱形内部的每个条件是否走过
满足判定覆盖一定满足语句覆盖,根据Y和N必须都判断
满足条件覆盖不一定满足判定覆盖
满足条件覆盖不一定满足语句覆盖
令图中的条件分别为T1,T2,T3,T4,以下有两种条件覆盖的用例,第三列中T和!T都有取到,但是第二列和第四列表示经过的分支、走过的路径不同,第一种走过了所有判断,第二个没有,因此第一种同时满足判定覆盖和条件覆盖;第二种仅满足条件覆盖。
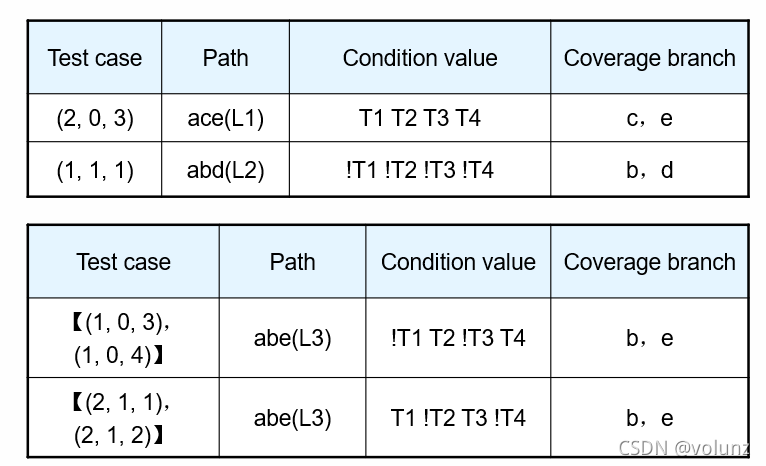
条件-判定覆盖(Condition/Decision Coverage)
定义:同时满足条件覆盖和判定覆盖。不讲人话:设计测试用例,使得测试程序代码的每个判断本身的取真和取假至少满足一次,每个逻辑条件的取真和取假至少满足一次。
测试设计用例如果满足判定条件覆盖,则一定满足判定覆盖,条件覆盖,语句覆盖
局限性:会忽略条件中取或(or)的情况。假如正确代码的条件是取and,但是错误代码的条件是取or,而判定条件覆盖是不能发现这个代码逻辑错误的。
判定条件覆盖测试用例总数=判定结果总数+条件结果总数
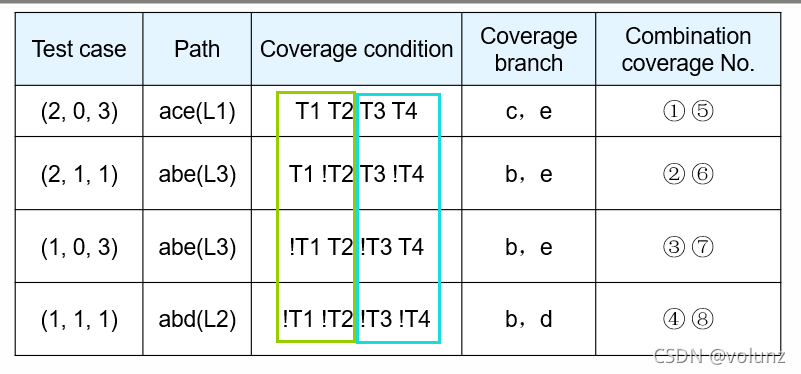
条件组合覆盖(Condition combination coverage)
定义:判定中条件的各种组合都至少被执行一次
如何找条件数:每个菱形框中的条件自己排列组合(是和非),n个小条件就是
2
n
2^n
2n种情况,不同菱形框之间则直接放一块组合即可,小条件数少的服从小条件数多的菱形框。不一定满足所有路径都走。不讲人话:每个判定的条件组合数相加,不同判定中的条件不需要组合。
局限性:不能保证全部路径被执行。
优点:满足条件组合覆盖—>满足判定-条件覆盖
路径覆盖
定义:每条路径至少执行一次。
满足路径覆盖不一定满足条件组合覆盖。
小总结
1、满足条件组合覆盖的用例一定满足语句覆盖
2、满足条件组合覆盖的用例一定满足条件覆盖
3、满足条件组合覆盖的用例一定满足判定覆盖
4、满足条件组合覆盖的用例一定满足条件判定覆盖
5、条件组合覆盖没有考虑各判定结果(真或假)组合情况,不满足路径覆盖
6、条件组合数量大,设计测试用例的时间花费较多
- 语句覆盖:每条语句至少执行一次。
- 判定覆盖:每个判定的所有可能结果至少出现一次。(又称“分支覆盖”)
- 条件覆盖:每个条件的所有可能结果至少执行一次。
- 判定/条件覆盖:一个判定中的每个条件的所有可能结果至少执行一次,并且每个判断本身的所有可能结果至少执行一次。
- 条件组合覆盖:每个判定中的所有可能的条件结果的组合,以及所有的入口点都至少执行一次。(注意“可能”二字,因为有些组合的情况难以生成。)
- 完全路径覆盖:每条路径至少执行一次。
- 基本路径覆盖:根据流图计算环复杂度,得到基本路径覆盖的用例数。
- 分割后的完全路径覆盖:每条路径至少执行一次,每个条件的所有可能结果至少执行一次。
覆盖程度
路径覆盖 > 多重条件覆盖 > 判定/条件覆盖 > 条件覆盖 > 判定覆盖 > 语句覆盖
1. 路径覆盖是覆盖率最高的。语句覆盖最弱。
2. 满足多重条件覆盖准则的测试用例集,同样满足判定覆盖准则、条件覆盖准则和判定/条件覆盖准则。
做题技巧
- 条件判断中,将所有单个原子条件只需要看其独立的是非取到了没有
- 条件组合判断,以菱形框为单位,菱形框里原子条件以2的次方排列,菱形框之间直接结合组合
- 语句覆盖、判定覆盖的测试用例只要保证左侧分支和右侧分支都覆盖即可。(所以满足了判定覆盖一定满足语句覆盖,满足条件覆盖不一定满足语句覆盖,因为条件覆盖推不出语句覆盖)
- 判定覆盖、语句覆盖、路径覆盖可以放在一起看,因为是最为简单的覆盖
N-S图
看ppt吧,文字没法表述。反正就是分成不同的层次,加法原理和乘法原理混合使用。
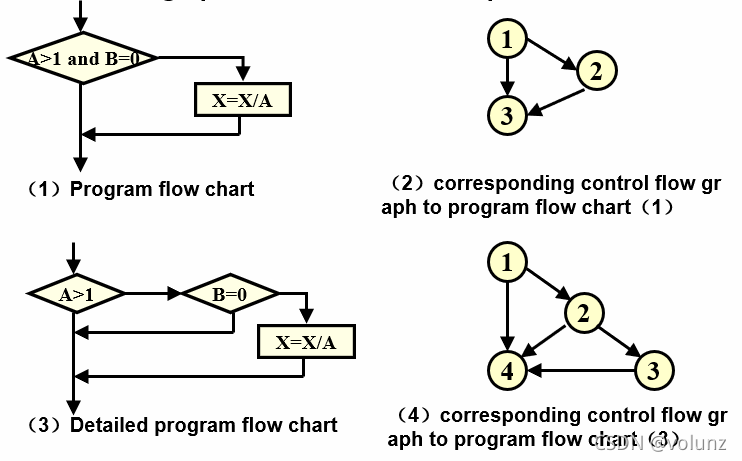
控制流图(Control Flow Graph)
程序流程图用来描述程序的结构性,是一个有向图,又叫框图,它采用不同的图形符号标明条件或者处理等。由于这些符号在路径分析是不重要,为了突出控制流结构,我们将程序流程图简化,产生控制流图。
控制流图组成元素:
- 节点node
- 边 edge
- 域 region
- 判断节点 prediction node:两边有分叉的

until中,2是判定节点;while中,1是判定节点
画控制流图需要注意的 - 1. 不要认为每个节点代表一个语句,这个节点有可能是空节点
- 2. 注意合并
- 3. 添加空节点
- 4. 可以先画框图明确结构,再画控制流图
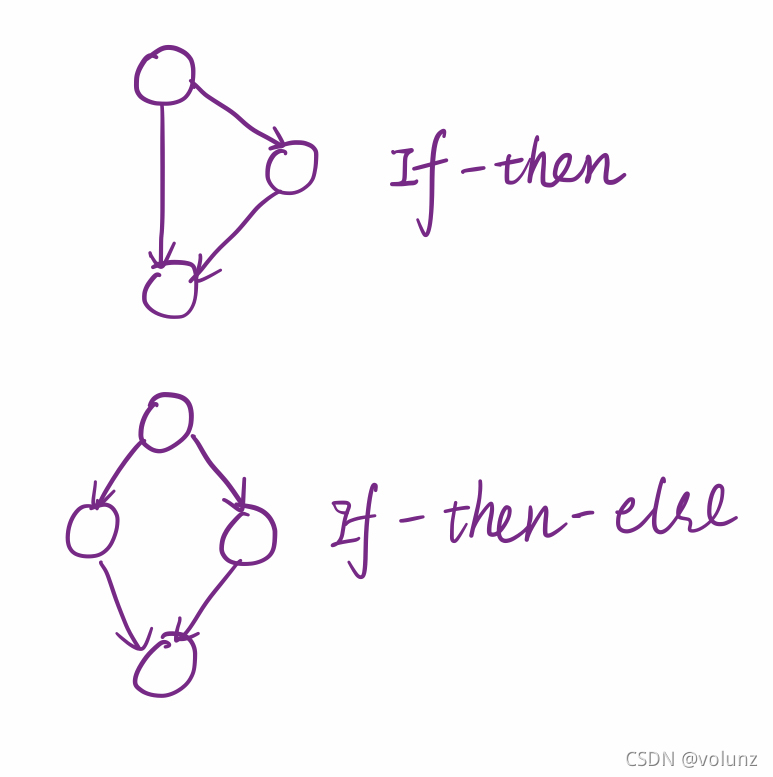
经典结构:
基本路径测试(Basis Path Testing)
Cyclomatic Complexity(基本复杂度/圈复杂度)
- 圈复杂度(Cyclomatic complexity,CC)也称为条件复杂度,是一种衡量代码复杂度的标准,其符号为V(G)。
- 麦凯布最早提出一种称为“基础路径测试”(Basis Path Testing)的软件测试方式,测试程序中的每一线性独立路径,所需的测试用例个数即为程序的圈复杂度。
- 圈复杂度可以用来衡量一个模块判定结构的复杂程度,其数量上表现为独立路径的条数,也可理解为覆盖所有的可能情况最少使用的测试用例个数。
- 圈复杂度可应用在程序的子程序、模块、方法或类别。
计算公式
Cyclomatic Complexity
- ①=#Edges - #Nodes + #Terminal vertices(通常是2,当终结点直达指向初始节点的箭头时为1)
人话:(边数-节点数+2或者+1);全连通图(终结点指向初节点就+1,初节点指向终结点不算)
检查方法,不用于计算: - ②=#Predicate nodes+1 判定节点数+1
- ③=number of regions 区域数(总区域也算)
可以开出,节点合并与否不影响圈复杂度,边数+1节点数+1相减之后结果不变
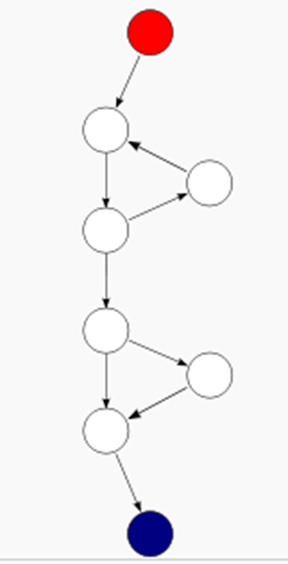
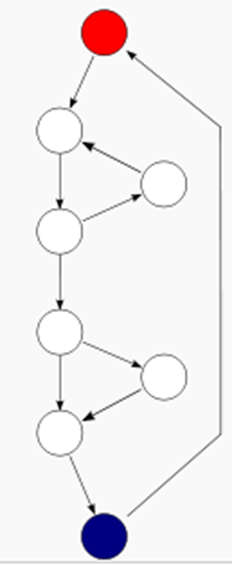
上图两者都是3的圈复杂度,右图终节点指向初节点因此+1;左:9-8+2;右:10-8+1
数独立路径 - 从初始节点开始走路直到终结点
- 有分叉就分别走分叉
设计测试用例步骤
- 画出流程图(我认为是控制流图)
- 计算圈复杂度
- 写出独立路径集
- 测试用例分别执行每一条路径
简单控制流图和复杂控制流图:圈复杂度不同,在判定条件中复杂控制流图进行了拆分
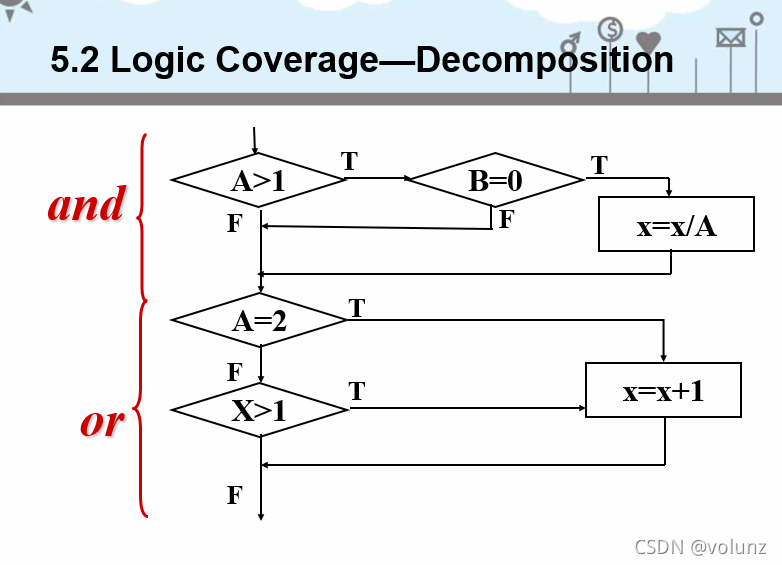
做题技巧:
- 画复杂和简单的流控制图,可以在边旁边标注条件,这样就能顺着条件往下走,非常清晰明了。
- 写独立路径的时候,还要顾及条件,前后条件矛盾的就不用写(估计也是逻辑不对的)
- 简单图和复杂图互相照应,需要拆分的点用小数来写
- 记住复杂图中and和or的基本几何抽象图形

循环测试
循环的类型
- simple loops 简单循环
- nested loops 嵌套循环
- concatenated loops 连锁循环
- unstructured loops 非结构循环
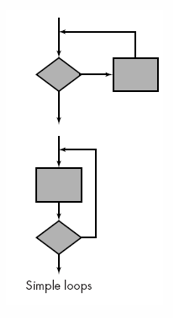
简单循环
n为循环允许最大的圈数
设计一个完全不执行循环体的测试。 (跳过整个循环)
设计一个循环体只执行一次的测试。 (只循环一次)
设计一个循环体恰好执行两次的测试。 (只循环两次)
设计一个测试,让循环体执行一些“典型”的次数。 (循环m次,m<n)
如果有一个上限,n,循环体可以执行的次数,那么也应该应用以下情况。
设计一个测试,使循环体恰好执行n-1次。 (循环n-1次)
设计一个测试,使循环体恰好执行n次。 (循环n次)
设计一个测试,使循环体恰好执行n+1次。 (循环n+1次,可能没有)
问题
对于简单循环,不是非要执行n+1次,而是不论输入什么总有正确的输出信息。
嵌套循环
从最里面的循环开始。 将所有其他循环设置为最小值。
对最内层循环进行简单的循环测试,同时保持外层循环的最小迭代参数(例如,循环计数器)值。 添加超出范围或排除值的其他测试。
向外工作,对下一个循环进行测试,但保持所有其他外部循环为最小值,其他嵌套循环为“典型”值。
继续,直到所有循环都被测试完毕。
- 从最内层循环开始,所有其他设为最小值
- 对最内层循环进行简单循环测试,保持外层循环最小迭代参数值,添加超出范围或排除值的其他测试。
- 向外层测试,保持所有外层循环为最小值,其他嵌套循环为“典型”值。
- 重复操作知道所有循环都被测试
对于嵌套循环测试对最内层循环进行简单的循环测试,同时保持外层循环的最小值。 最小值是1
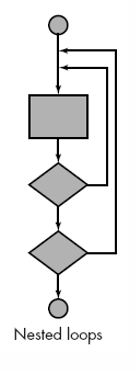
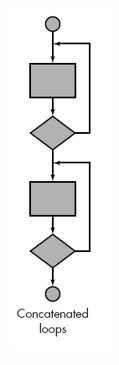
连锁循环
一个接一个地测试,循环都是独立的就使用简单循环测试,否则使用嵌套循环测试。
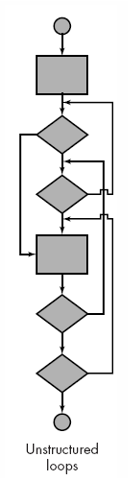
非结构化循环
只要有可能,就应该重新设计这类循环,以反映结构化编程构造的使用

数据流测试(date flow testing)
数据流测试是非功能性测试
数据流测试方法根据程序中变量的定义和使用的位置,选择程序的测试路径
数据流测试是一个强大的工具,可以检测由于编码错误而导致的数据值使用不当
- 错误的赋值或输入语句 (数据类型错误)
- 缺少定义(使用空定义)
- 谓词是错误的(使用了错误的路径,导致了错误的定义) (数据不一致)
数据流分析与路径测试的区别在于:路径测试基本上是从**数学(控制流图)**角度来分析的,而数据流测试则是利用了变量之间的关系,通过定义-使用路径和程序片,得到一系列的测试指标用于衡量测试的覆盖率。
数据流分析定义
数据流指的是数据对象的顺序和可能状态的抽象表示。 数据对象的状态可以是创建/定义(Creation/Defined)、使用(Use)和清除/销毁(Killed/Destruction)。数据值的变量存在从创建、使用到销毁的一个完整状态。 编码错误导致的变量赋值错误检查是发现代码缺陷或错误的一种有效方法。实际上该方法可认为是路径测试的“真实性”检查,是对基于路径测试的一种改良。
**数据流分析的功能作用 **
数据流分析的作用是用来测试变量设置点和使用点之间的路径。这些路径也 称为“定义-使用对”(definition-use 或 du-pairs)或“设置-使用对”。通过数据流分析而生成的测试集可用来获得针对每个变量的“定义-使用对”的 100%覆盖。但是,要追踪整个程序代码中的每个变量的设置和使用时,并不需在测试时考虑被测对象的控制流。
-
程序代码路径中首次出现的变量可能存在的状态组合
-
d 变量不存在或没定义(通过 ~ 表示),然后定义(d),~d 是正确的。
~u 变量不存在或没定义,然后使用(u), ~u 是错误的,因为变量使用之前必须定义。
~k 变量不存在或没定义,然后撤销(k), ~k 可能是错误的,因在创建变量之前撤销变量可能是一个潜在的编程错误。
d、u、k 的具体含义:
d: 变量声明或定义,且变量已赋值
u: 读取及使用
k: 声明或定义变量,但还未为其赋值或已释放变量(模块或函数 结束时)
c -计算右手边,指针(计算)
p -用于谓词(或作为循环的控制变量)
针对程序代码路径中的变量执行的顺序,变量状态 d、u、k 的组合可能会有 3*3=9 种情况
dd:变量赋值后再次赋值,可疑的或可能是编程错误。
du:变量赋值后使用,正确。是程序代码中的正常情况。
dk:变量定义后撤销,可疑的或可能是编程错误。
ud:变量使用后再定义,可以接受。
uu:变量使用之后再使用,可以接受。
uk:变量使用之后撤销,可以接受。
kd:变量撤销后再定义,可以接受,变量撤销之后重新定义。
ku:变量未定义或撤销后使用,严重问题,在变量不存在或没有定义的情况下,使用变量是错误的。
kk:变量未定义或撤销之后再撤销,可能是编程错误。
数据流分析可基于数据流图而展开
数据流图类似于控制流图,描述了测试对象代码的处理过程。同时也详细描述了代码中变量的创建、使用和撤销的状态。通过检查数据流图来验证测试对象代码中每个变量的状态组合是否正确。
首先,执行图的静态测试。 “静态”是指检查图表(正式地通过检查或非正式地通过查看)。
其次,执行动态测试。 “动态”是指我们构建和执行测试用例 。
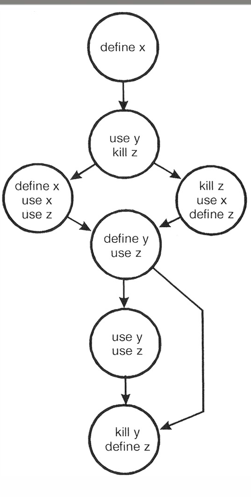
是一个数据流图的例。
静态测试的过程的例子:
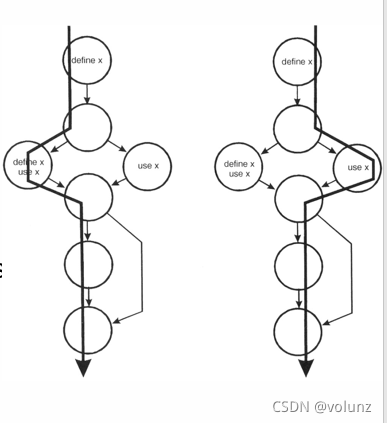
- 对于模块中的每个变量,沿着控制流路径检查定义-使用-终止模式 ,通过分析每个变量的执行顺序状态,可以发现存在的一些问题。 这里,分析例中三个变量 x,y,z,其存在的状态组合如下:
变量 x,其状态的可能组合:
~d:正确的情况
dd:定义之后再定义,可能是编程错误
du:定义之后使用,正确情况
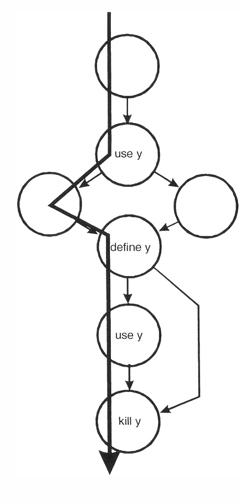
变量 y,其状态的可能组合:
~u: 定义变量之前使用变量,严重错误
ud: 变量使用后再定义,可接受
du: 变量定义之后使用,正确情况
uk:变量使用之后撤销,可接受
dk:变量定义之后撤销,可能是编程错误
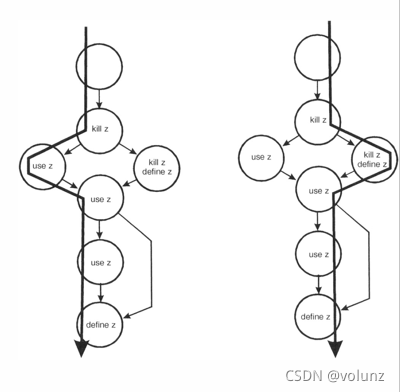
变量 z,其状态的可能组合:
~k:定义变量之前撤销变量,可能是编程错误
ku:变量撤销后使用变量,严重错误
uu: 使用变量后再使用变量,正确情况
ud:变量使用之后再定义,可接受
kk:撤销变量后再撤销,可能是编程错误
kd:变量撤销后再定义,可接受
du:变量定义之后使用变量,正常情况
因此,针对本例的数据流分析中可得出存在着下列问题:(对照前面
的组合状态定义和三个变量的组合状态)
变量 x 存在 dd 的编程错误
变量 y 存在 ~u 和 dk 的编程错误
变量 z 存在 ~k、ku、kk 编程错误
动态测试过程
虽然静态测试可以检测到许多数据流错误,但它无法找到所有错误,因此需要动态数据流测试
- 每个“定义define”都可以追溯到它的每个“用途use”
- 每一个“使用use”都是从它相应的“定义define”追踪到的。
步骤: - 枚举模块中的路径
- 对于每个变量,创建至少一个测试用例来覆盖每个定义使用对。
定义一个名为stuff的数组,由100个整数元素组成。 在C、c++和Java中,单个元素被命名为stuff[0]、stuff[1]、stuff[2]等。 数组是作为一个单元定义和销毁的,但数组中的特定元素是单独使用的。 程序员经常引用[j],其中j随着程序执行而动态变化。 在一般情况下,静态分析不能确定定义-使用-销毁(define-use-kill)规则是否被正确地遵循,除非单独考虑每个元素。
动态数据流测试
为此,枚举模块中的路径。 这可以使用与控制流测试相同的方法来完成:从模块的入口点开始,沿着最左边的路径通过模块到它的出口。 回到开始,改变第一个分支条件。 沿着那条路走到出口。 返回到开始,改变第二个分支条件,然后是第三个,以此类推,直到列出所有的路径。 然后,对于每个变量,创建至少一个测试用例来覆盖每个定义使用对。
突变测试(mutation testing)
突变测试(mutation testing) , 或称作突变分析、程序突变,它是用于衡量软件测试的质量。突变测试通常对程序的源代码或者目标代码做小的改动,并把截然不同的错误行为(或者怪异行为)作为预期。如果测试代码没有觉察到这种小改动带来的错误,就说明这个测试是有问题的。
https://www.cnblogs.com/TongWee/p/4505289.html
这个博客感觉讲的挺好的
变异算子 (Mutation operators):用于通过替换、插入或删除操作符修改变量和表达式。
一阶变异体(First-order mutants):在原有程序 p 上执行单一变异算子并形成变异体 p′ ,则称p′为p的一阶变异体。
高阶变异体(Higher-order mutants): 在原有程序 p 上依次执行多次变异算子并形成变异体 p′ ,则称 p′ 为 p 的高阶变异体。若在 p 上依次执行 k 次变异算子并形成变异体 p′ , 则称 p′ 为 p 的 k 阶变异体。
现在,为了使测试杀死这个突变,需要满足以下条件:
(1) 测试输入数据必须对突变和原始创新引起不同的程序状态。例如:一个测试a=1,b=0可以达到这个目的。
(2)‘c’的值应该传播到程序输出并被测试检查。
弱的突变测试(弱的突变覆盖)只要求满足第一个条件。强的突变测试要求满足两个条件。强突变更有效,因此它保证测试单元可以真实的捕捉错误。弱突变近似于代码覆盖方法。它只需较少的计算能力来保证测试单元满足弱突变测试。
中英对照解释
white-box testing 白盒测试
logic coverage 逻辑覆盖
Statement coverage 语句覆盖
Decision coverage 判定覆盖
Condition coverage 条件覆盖
Condition/decision coverage 条件-判定覆盖
Condition combination coverage 条件组合覆盖
Path coverage 路径覆盖
Control Flow Graph 控制流图
Cyclomatic Complexity 基本复杂度/圈复杂度
simple loops 简单循环
nested loops 嵌套循环
concatenated loops 连锁循环
unstructured loops 非结构循环

















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









