






问题描述
给定一个 n 个点 m 条边的有向图,点的编号是 1 到 n,图中可能存在重边和自环。
请输出任意一个该有向图的拓扑序列,如果拓扑序列不存在,则输出 −1。
若一个由图中所有点构成的序列 A 满足:对于图中的每条边 (x,y),x 在 A 中都出现在 y 之前,则称 A 是该图的一个拓扑序列。
输入格式
第一行包含两个整数 n 和 m
接下来 m 行,每行包含两个整数 x 和 y,表示存在一条从点 x 到点 y 的有向边 (x,y)。
输出格式
共一行,如果存在拓扑序列,则输出任意一个合法的拓扑序列即可。
否则输出 −1
问题求解
拓扑排序:
依次删除入度为0的点以及它发出的边
如果最后全部点都被删除完全,则成功进行拓扑排序
否则,输出-1
首先记录各个点的入度
然后将入度为 0 的点放入队列
将队列里的点依次出队列,然后找出所有出队列这个点发出的边,删除边,同事边的另一侧的点的入度 -1。
如果所有点都进过队列,则可以拓扑排序,输出所有顶点。否则输出-1,代表不可以进行拓扑排序
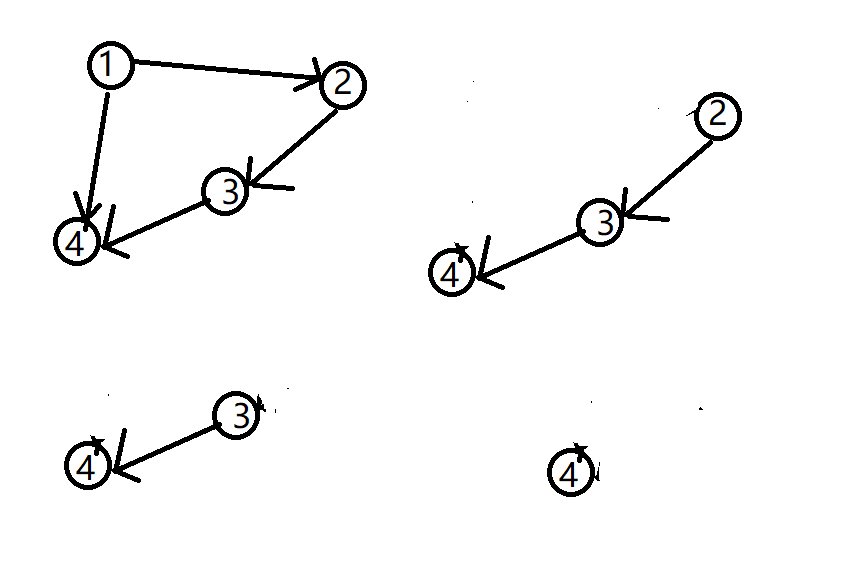
代码实现
# include <iostream>
# include <queue>
# include <vector>
# include<cstring>
# include <algorithm>
using namespace std;
const int N = 100010;
queue<int> q;
vector<int> v;
int e[N], ne[N],h[N];
int d[N];//计算每个点的入度数
int idx;
int n,m;
int sum;
void add(int a, int b){
e[idx] = b;
ne[idx] = h[a];
h[a] = idx++;
}
void topsort(){
//找度为0的点
for(int i =1; i<=n; i++){
if(d[i]==0){
q.push(i);
}
}
while(!q.empty()){
int u = q.front();
v.push_back(u);
sum++;
q.pop();
for(int j = h[u]; j!=-1; j=ne[j]){
int c = e[j];
d[c]--;
if(d[c]==0){
q.push(c);
}
}
}
if(sum == n){
for(auto i : v){
cout<<i<<" ";
}
}
else{
cout<<-1;
}
}
int main(){
memset(h, -1, sizeof(h));
cin>>n>>m;
int a,b;
for(int i =0 ;i<m ;i++){
cin>>a>>b;
add(a,b);
d[b]++;
}
topsort();
}















 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









