







简单介绍

API介绍:
nn.LSTM(input_size=100, hidden_size=10, num_layers=1,batch_first=True, bidirectional=True)
inuput_size: embedding_dim
hidden_size: 每一层LSTM单元的数量
num_layers: RNN中LSTM的层数
batch_first: True对应[batch_size, seq_len, embedding_dim]
bidiectional: True对应使用双向LSTM
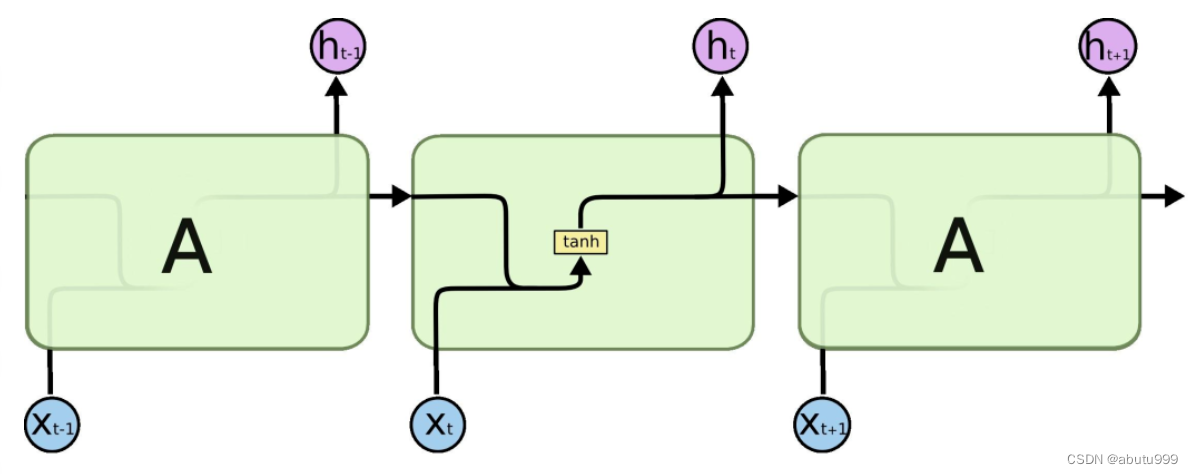
实例化LSTM对象后,不仅要传入数据,还有传入前一次的h_0和c_0
lstm(input, (h_0, c_0))
LSTM默认输出(output, (h_n, c_n))
output: [ seq_len, batch, hidden_size*num_directions ] (若batch_first=false)
h_n: [num_directions, batch, hidden_size]
c_n : [num_directions, batch, hidden_size]
import torch.nn as nn
import torch.nn.functional as F
import torch
batch_size = 10
seq_len =20 #句子长度
vocab_size = 100 # 词典数量
embedding_dim = 30 # 用embedding_dim长度的向量表示一个词语
hidden_size = 18
input = torch.randint(0, 100, [batch_size, seq_len])
print(input.size())
print("*"*100)
# 经过embedding
embed = nn.Embedding(vocab_size, embedding_dim)
input_embed = embed(input) # [bs, seq_len, embedding_dim]
print(input_embed.size())
print("*"*100)
lstm = nn.LSTM(embedding_dim, hidden_size=hidden_size, num_layers=1, batch_first=True)
output,(h_n, c_n) = lstm(input_embed)
print(output.size())
print("*"*100)
print(h_n.size())
print("*"*100)
print(c_n.size())
通常由最后一个输出代替整个句子
使用双向LSTM实现
"""
定义模型
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from lib import ws,max_len
from dataset import get_data
import lib
import os
import numpy as np
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.embedding = nn.Embedding(len(ws), 100)
self.lstm = nn.LSTM(input_size=100, hidden_size=lib.hidden_size, num_layers=lib.num_layers,batch_first=True, bidirectional=lib.bidirectional, dropout=lib.dropout)
self.fc = nn.Linear(lib.hidden_size*2, 2)
def forward(self, input):
"""
:param input: [batch_size, max_len]
:return:
"""
x = self.embedding(input) # [batch_size, max_len, 100]
x,(h_n,c_n)= self.lstm(x)
output = torch.cat([h_n[-2,:,:],h_n[-1,:,:]],dim=-1)
output = self.fc(output)
return F.log_softmax(output,dim=-1)
model = MyModel().to(lib.device)
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
if os.path.exists("./model0/model.pkl"):
model.load_state_dict(torch.load("./model0/model.pkl"))
optimizer.load_state_dict(torch.load("./model0/optimizer.pkl"))
def train(epoch):
for idx,(input,target) in enumerate(get_data(train=True)):
input = input.to(lib.device)
target = target.to(lib.device)
# 梯度清零
optimizer.zero_grad()
output= model(input)
loss = F.nll_loss(output,target)
loss.backward()
optimizer.step()
print(epoch, idx, loss.item())
if idx%100==0:
torch.save(model.state_dict(),"./model0/model.pkl")
torch.save(optimizer.state_dict(),"./model0/optimizer.pkl")
def eval():
loss_list = []
acc_list = []
for idx,(input,target) in enumerate(get_data(train=False, batch_size=lib.test_batch_size)):
input = input.to(lib.device)
target = target.to(lib.device)
with torch.no_grad():
output= model(input)
loss = F.nll_loss(output,target)
loss_list.append(loss.cpu().item())
pre = output.max(dim=-1)[-1]
acc = pre.eq(target).float().mean()
acc_list.append(acc.cpu().item())
print("total loss, acc:", np.mean(loss_list), np.mean(acc_list))
if __name__ == '__main__':
for i in range(10):
train(epoch=i)
eval()















 2022
2022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









