







 文章介绍了NCF框架中的三种模型——GMF(广义矩阵分解)、MLP(多层感知器)和NeuMF,它们通过不同的方式处理用户和物品的潜在特征。GMF采用线性内积,MLP引入非线性以学习交互,NeuMF则是两者融合,提供更灵活的模型。
文章介绍了NCF框架中的三种模型——GMF(广义矩阵分解)、MLP(多层感知器)和NeuMF,它们通过不同的方式处理用户和物品的潜在特征。GMF采用线性内积,MLP引入非线性以学习交互,NeuMF则是两者融合,提供更灵活的模型。
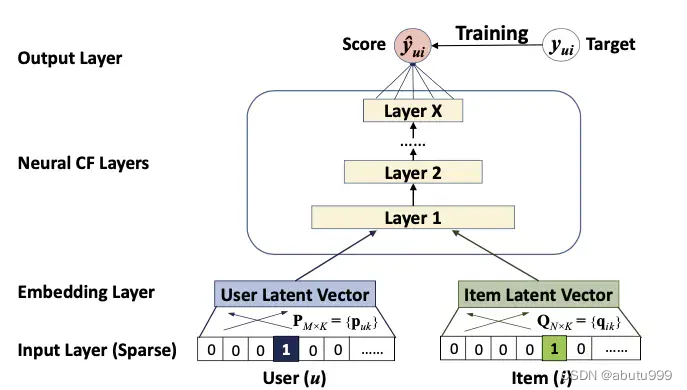
NCF框架
NCF框架是本文要实现的3个模型的主体结构。
首先是输入层,分别包含两个特征向量 v u v_u vu和 v i v_i vi,描述了用户u和物品i。输入仅由一个用户向量和一个物品向量构成,它们分别是以one-hot编码的二值化稀疏向量。
接着是Embedding层,这是一个全连接层,用于将输入层的系数向量表示成一个稠密向量。
接着用户和物品的embedding向量被送入多层神经网络架结构中,这一层叫做神经协同过滤层(Neural CF Layer),它用于将潜在特征向量映射成预测分数(Score)。
class NCF(object):
def __init__(self, config, latent_dim_gmf=8, latent_dim_mlp=8):
self._config = config
self._num_users = config['num_users']
self._num_items = config['num_items']
self._latent_dim_gmf = latent_dim_gmf
self._latent_dim_mlp = latent_dim_mlp
self._embedding_user_mlp = torch.nn.Embedding(num_embeddings=self._num_users,embedding_dim=self._latent_dim_mlp)
self._embedding_item_mlp = torch.nn.Embedding(num_embeddings=self._num_items,embedding_dim=self._latent_dim_mlp)
# 建立GMP模型的user Embedding层和item Embedding层,输入的向量长度分别为用户的数量,item的数量,输出都是隐式空间的维度latent dim
self._embedding_user_gmf = torch.nn.Embedding(num_embeddings=self._num_users, embedding_dim=self._latent_dim_gmf)
self._embedding_item_gmf = torch.nn.Embedding(num_embeddings=self._num_items, embedding_dim=self._latent_dim_gmf)
# 全连接层
self._fc_layers = torch.nn.ModuleList()
for idx, (in_size, out_size) in enumerate(zip(config['layers'][:-1], config['layers'][1:])):
self._fc_layers.append(torch.nn.Linear(in_size, out_size))
# 激活函数
self._logistic = nn.Sigmoid()
@property
def fc_layers(self):
return self._fc_layers
@property
def embedding_user_gmf(self):
return self._embedding_user_gmf
@property
def embedding_item_gmf(self):
return self._embedding_item_gmf
@property
def embedding_user_mlp(self):
return self._embedding_user_mlp
@property
def embedding_item_mlp(self):
return self._embedding_item_mlp
def saveModel(self):
torch.save(self.state_dict(), self._config['model_name'])
@abstractmethod
def load_preTrained_weights(self):
pass
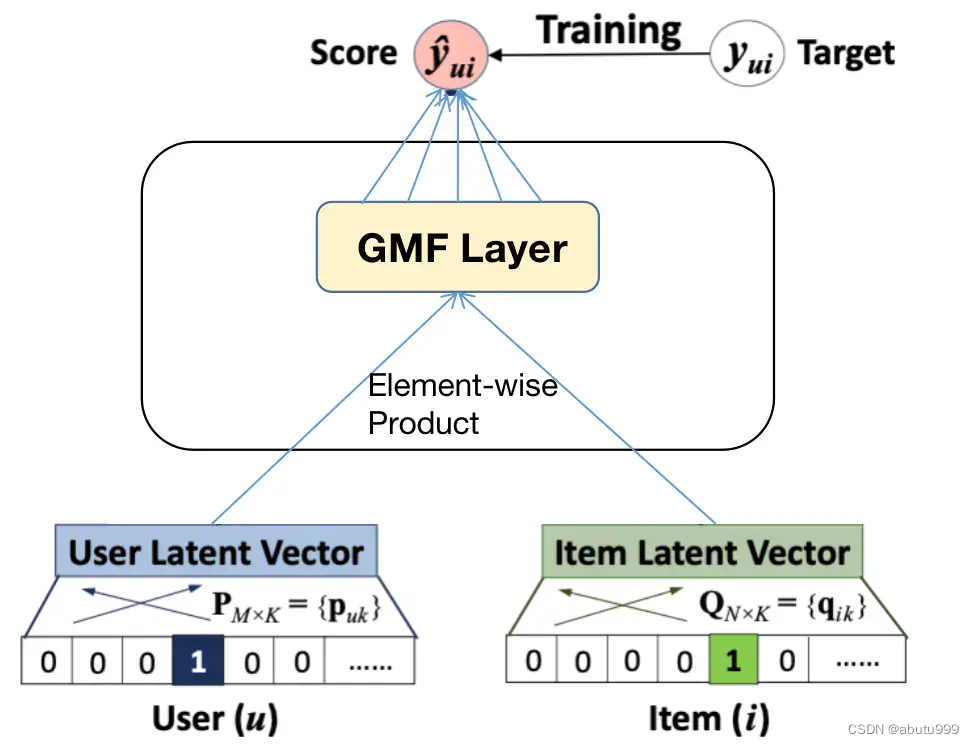
GMF模型(广义矩阵分解)
p
u
p_u
pu为用户u的潜在向量,$q_i为物品i的潜在向量。
则,神经协同网络的第一层映射函数为:
ϕ
1
(
p
u
,
q
i
)
=
p
u
⊙
q
i
\phi_1(p_u,q_i) = p_u \odot q_i
ϕ1(pu,qi)=pu⊙qi
然后将此向量映射到输出层:
y
^
u
,
i
=
a
o
u
t
(
h
T
(
p
u
⊙
q
i
)
)
\hat{y} _{u,i} =a_{out}(h^T( p_u \odot q_i))
y^u,i=aout(hT(pu⊙qi))
如果把
a
o
u
t
a_{out}
aout看作恒等函数,
h
h
h全为1的单位向量,就变成了MF模型。
class GMF(NCF,nn.Module):
def __init__(self, config, latent_dim_gmf):
nn.Module.__init__(self)
NCF.__init__(self, config = config, latent_dim_gmf=latent_dim_gmf)
# 创建线性模型,输入:潜在特征向量, 输出:len =1
self._affine_output = nn.Linear(in_features=self.latent_dim_gmf, out_features=1)
@property
def affine_output(self):
return self._affine_output
def forward(self, user_indices, item_indices):
user_embedding = self._embedding_user_gmf(user_indices)
item_embedding = self._embedding_item_gmf(item_indices)
# 将user_embedding和user_embedding进行逐元素相乘
element_product = torch.mul(user_embedding, item_embedding)
# 通过s神经元
logits = self._affine_output(element_product)
rating = self._logistic(logits)
def load_preTrained_weights(self):
pass
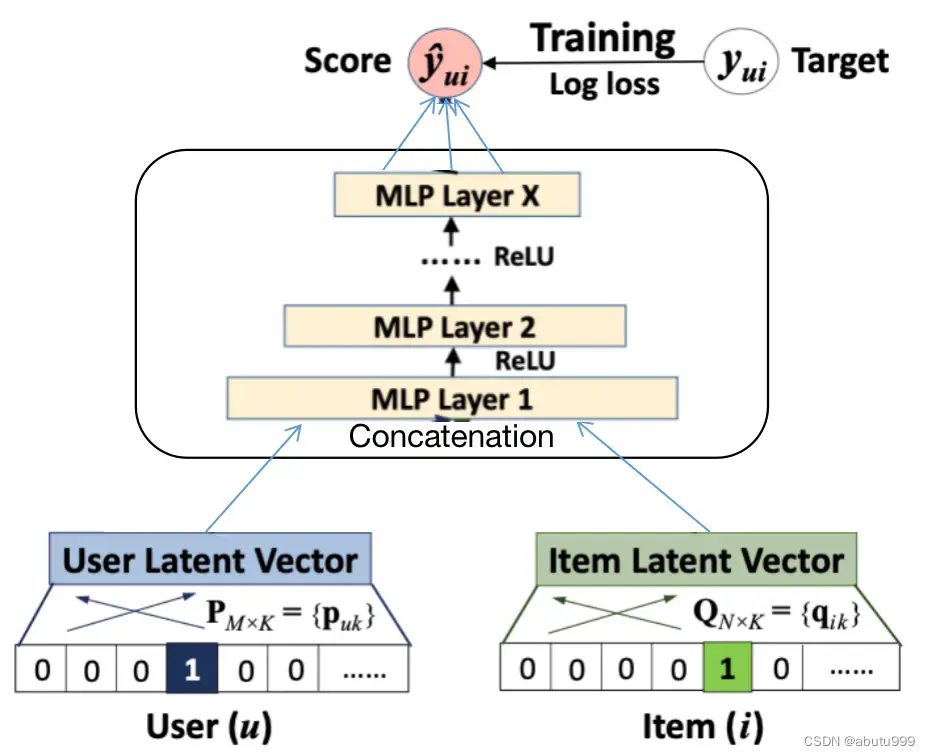
MLP模型
简单的结合是不足以说明用户和物品之间的潜在特征。为了解决这个问题,我们需要向量连接的基础上增加隐藏层,可以使用标准的MLP来学习用户和物品潜在特征之间的相互作用。
在经过Embedding层后,将得到的用户和物品的潜在向量做连接(concatenation),即:
z
1
=
ϕ
1
(
p
u
,
q
i
)
=
[
p
u
q
i
]
z_1 = \phi_1(p_u, q_i) = \begin{bmatrix} p_u \\ q_i \end{bmatrix}
z1=ϕ1(pu,qi)=[puqi]
接着将模型通过一层层感知层,激活函数选择ReLU函数。
ϕ
2
(
z
1
)
=
a
2
(
W
2
T
z
1
+
b
2
)
\phi_2(z_1) = a_2(W_2^{T}z_1 + b_2)
ϕ2(z1)=a2(W2Tz1+b2)
以此类推。
到最后:
y
^
u
i
=
σ
(
h
T
ϕ
L
(
z
L
−
1
)
)
\hat{y}_{ui} = \sigma{(h_T\phi_L(z_{L-1}))}
y^ui=σ(hTϕL(zL−1))
class MLP(NCF, nn.Module):
def __init__(self, config, latent_dim_mlp):
nn.Module.__init__(self)
NCF.__init__(self, config = config, latent_dim_mlp= latent_dim_mlp)
self._affine_output = torch.nn.Linear(in_features=config['layers'][-1], out_features=1)
@property
def affine_output(self):
return self._affine_output
def forward(self, user_indices, item_indices):
user_embedding = self._embedding_user_mlp(user_indices)
item_embedding = self._embedding_item_mlp(item_indices)
# 把潜在向量进行连接
vector = torch.cat([user_embedding, item_embedding],dim=-1)
for idx, _ in enumerate(range(len(self._fc_layers))):
vector = self._fc_layers[idx](vector)
vector = torch.nn.ReLU()(vector)
logits = self._affine_output(vector)
rating = self._logistic(logits)
return rating
def load_preTrained_weights(self):
config = self._config
gmf_model = GMF(config, config['latent_dim_gmf'])
if config['use_cuda'] is True:
gmf_model.cuda()
# 加载GMF模型参数到指定的GPU上
state_dict = torch.load(self._config['pretrain_gmf'])
#map_location=lambda storage, loc: storage.cuda(device=self._config['device_id']))
#map_location = {'cuda:0': 'cpu'})
gmf_model.load_state_dict(state_dict, strict=False)
self._embedding_item_mlp.weight.data = gmf_model.embedding_item_gmf.weight.data
self._embedding_user_mlp.weight.data = gmf_model.embedding_user_gmf.weight.data
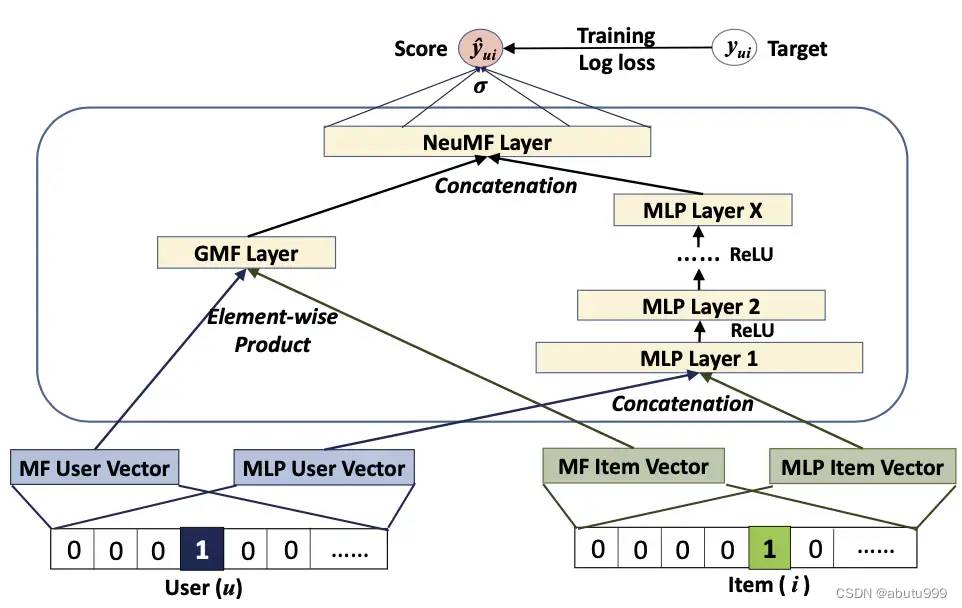
NeuMF模型
GMF应用了线性内核来模拟潜在的特征交互;MLP使用了非线性内核从数据中学习潜在特征,那么自然而然地想到,我们可以将这两个模型融合在NCF框架下。
为了使得融合模型具有更大的灵活性,我们允许GMF和MLP学习独立的Embedding,并结合两种模型的最后的输出。
对左边的GMF模型:
ϕ
G
M
F
=
p
u
G
⊙
q
i
G
\phi^{GMF} = p_u^G \odot q_i^G
ϕGMF=puG⊙qiG
即 GMF模型的用户潜在向量和物品潜在向量做内积
对右边的MLP模型:
ϕ
M
L
P
=
a
L
(
W
L
T
(
a
L
−
1
(
.
.
.
a
2
(
W
2
T
[
p
u
M
q
i
M
]
+
b
2
)
.
.
.
)
)
+
b
L
)
\phi^{MLP} = a_L(W_L^T(a_{L-1}(...a_2(W_2^T\begin{bmatrix} p_u^M \\ q_i^M \end{bmatrix} + b_2)...)) + b_L)
ϕMLP=aL(WLT(aL−1(...a2(W2T[puMqiM]+b2)...))+bL)
综合MLP和GMF模型得到:
y
^
u
i
=
σ
(
h
T
[
ϕ
G
M
F
ϕ
M
L
P
]
)
\hat{y}_{ui} = \sigma(h^T \begin{bmatrix} \phi^{GMF} \\ \phi^{MLP} \end{bmatrix} )
y^ui=σ(hT[ϕGMFϕMLP])















 610
610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









