






使用场景:
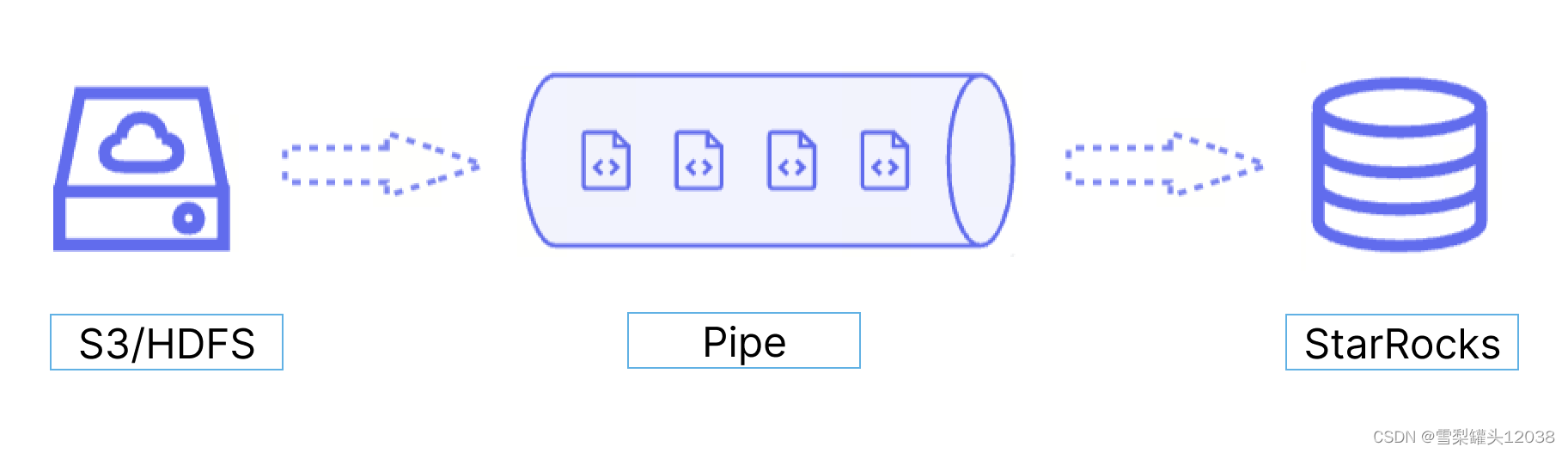
Pipe 会按文件数量或大小,自动对目录下的文件进行拆分,将一个大的导入作业拆分成多个较小的串行的导入任务,从而降低出错重试的代价。另外,在进行持续性的数据导入时,也推荐使用 Pipe,它能监听远端存储目录的文件变化,并持续导入有变化的文件数据
Pipe 还支持文件唯一性判断,避免重复数据导入。在导入过程中,Pipe 会根据文件名和文件对应的摘要值判断数据文件是否重复。如果文件名和文件摘要值在同一个 Pipe 导入作业中已经处理过,后续导入会自动跳过已经处理过的文件。注意,HDFS 使用 LastModifiedTime 作为文件摘要
版本:
3.2 版本起
支持格式:
Parquet 和 ORC 文件格式
文件导入顺序:
Pipe 导入操作会在内部维护一个文件队列,分批次从队列中取出对应文件进行导入。Pipe 并不能保证文件的导入顺序和文件上传顺序一致,因此可能会出现新的数据早于老的数据导入
工作原理:
创建语句:
CREATE [OR REPLACE] PIPE [db_name.]<pipe_name>
[PROPERTIES ("<key>" = "<value>"[, "<key> = <value>" ...])]
AS <INSERT_SQL>
参数说明
db_name:Pipe 所属的数据库的名称
pipe_name:Pipe 的名称。该名称在 Pipe 所在的数据库内必须唯一
INSERT_SQL:INSERT INTO SELECT FROM FILES 语句,用于从指定的源数据文件导入数据到目标表
PROPERTIES:用于控制 Pipe 执行的一些参数包括
- AUTO_INGEST:是否启用自动增量导入。取值范围:TRUE 和 FALSE
- POLL_INTERVAL:自动增量导入的轮询间隔
- BATCH_SIZE:导入批次大小。如果参数取值中不指定单位,则使用默认单位 Byte
- BATCH_FILES:导入批次文件数量。
示例:
CREATE PIPE pipe_hdfs_info01
PROPERTIES
(
"AUTO_INGEST" = "TRUE"
)
AS
INSERT INTO pipe_hdfs_info
SELECT * FROM FILES
(
"path" = "hdfs://192.168.219.102:9000/user/root/starrocks/insert_from_hdfs02.parquet",
"format" = "parquet",
"hadoop.security.authentication" = "simple",
"username" = "root",
"password" = "123456"
);
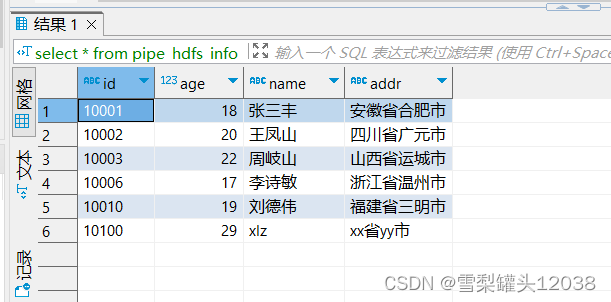
查询
















 2782
2782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









