







NNDL 实验五 前馈神经网络(1)二分类任务
4.1 神经元
神经网络的基本组成单元为带有非线性激活函数的神经元,其结构如如图4.2所示。神经元是对生物神经元的结构和特性的一种简化建模,接收一组输入信号并产生输出。

4.1.1 净活性值
假设一个神经元接收的输入为x∈RD,其权重向量为w∈RD,神经元所获得的输入信号,即净活性值z的计算方法为
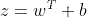
其中b为偏置。
为了提高预测样本的效率,我们通常会将N个样本归为一组进行成批地预测。
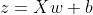
其中X∈RN×D为N个样本的特征矩阵,z∈RN为N个预测值组成的列向量。
使用torch计算一组输入的净活性值。代码实现如下:
import torch
# 2个特征数为5的样本
X = torch.rand([2, 5])
# 含有5个参数的权重向量
w = torch.rand([5, 1])
# 偏置项
b = torch.rand([1, 1])
# 使用'torch.matmul'实现矩阵相乘
z = torch.matmul(X, w) + b
print("input X:", X)
print("weight w:", w, "\nbias b:", b)
print("output z:", z)
实验结果:
input X: tensor([[0.4926, 0.0998, 0.9980, 0.1906, 0.3584],
[0.9125, 0.0939, 0.6280, 0.3257, 0.0792]])
weight w: tensor([[0.5445],
[0.4561],
[0.4649],
[0.3186],
[0.8939]])
bias b: tensor([[0.8112]])
output z: tensor([[1.9700],
[1.8174]])
【思考题】加权求和与仿射变换之间有什么区别和联系?

加权相加就是对数据在整体评估中占的重要作用设定比例,所有数的比例加起来应为1,然后将各数分别乘以各自的加权比例再相加。
Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。
仿射变换,又称仿射映射,是指在几何中,一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间。
仿射变换是在几何上定义为两个向量空间之间的一个仿射变换或者仿射映射由一个非奇异的线性变换(运用一次函数进行的变换)接上一个平移变换组成。
在有限维的情况,每个仿射变换可以由一个矩阵A和一个向量b给出,它可以写作A和一个附加的列b。一个仿射变换对应于一个矩阵和一个向量的乘法,而仿射变换的复合对应于普通的矩阵乘法,只要加入一个额外的行到矩阵的底下,这一行全部是0除了最右边是一个1,而列向量的底下要加上一个1。
仿射变换保留了:
1.点之间的共线性,例如通过同一线之点 (即称为共线点)在变换后仍呈共线。
2.向量沿着一线的比例,例如对相异共线三点与 的比例同于及。
3.带不同质量的点之质心。
4.1.2 激活函数
净活性值z再经过一个非线性函数f(⋅)后,得到神经元的活性值a。
a=f(z),(4.3)
激活函数通常为非线性函数,可以增强神经网络的表示能力和学习能力。常用的激活函数有S型函数和ReLU函数。
4.1.2.1 Sigmoid 型函数
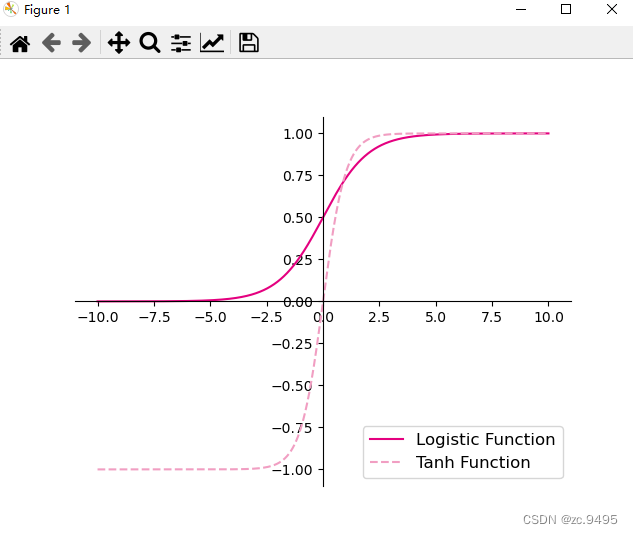
Sigmoid 型函数是指一类S型曲线函数,为两端饱和函数。常用的 Sigmoid 型函数有 Logistic 函数和 Tanh 函数,其数学表达式为
Logistic 函数:
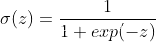
Tanh 函数:
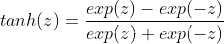
Logistic函数和Tanh函数的代码实现和可视化如下:
import matplotlib.pyplot as plt
# Logistic函数
def logistic(z):
return 1.0 / (1.0 + torch.exp(-z))
# Tanh函数
def tanh(z):
return (torch.exp(z) - torch.exp(-z)) / (torch.exp(z) + torch.exp(-z))
# 在[-10,10]的范围内生成10000个输入值,用于绘制函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), logistic(z).tolist(), color='#e4007f', label="Logistic Function")
plt.plot(z.tolist(), tanh(z).tolist(), color='#f19ec2', linestyle ='--', label="Tanh Function")
ax = plt.gca() # 获取轴,默认有4个
# 隐藏两个轴,通过把颜色设置成none
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# 调整坐标轴位置
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
plt.legend(loc='lower right', fontsize='large')
plt.savefig('fw-logistic-tanh.pdf')
plt.show()
实验结果:
4.1.2.2 ReLU型函数
常见的ReLU函数有ReLU和带泄露的ReLU(Leaky ReLU),数学表达式分别为:
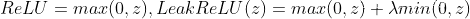
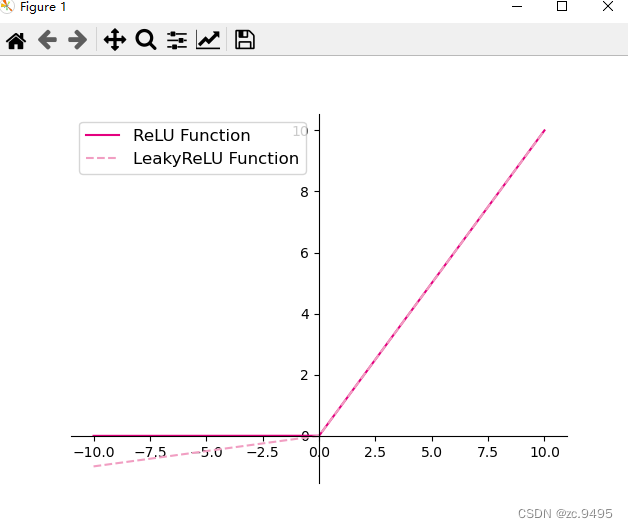
可视化ReLU和带泄露的ReLU的函数的代码实现和可视化如下:
# ReLU
def relu(z):
return torch.max(z, torch.tensor(0.))
# 带泄露的ReLU
def leaky_relu(z, negative_slope=0.1):
# 当前版本paddle暂不支持直接将bool类型转成int类型,因此调用了paddle的cast函数来进行显式转换
a1 = ((z>0).to(torch.float32) * z)
a2 = ((z<=0).to(torch.float32) * (negative_slope * z))
return a1 + a2
# 在[-10,10]的范围内生成一系列的输入值,用于绘制relu、leaky_relu的函数曲线
z = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(z.tolist(), relu(z).tolist(), color="#e4007f", label="ReLU Function")
plt.plot(z.tolist(), leaky_relu(z).tolist(), color="#f19ec2", linestyle="--", label="LeakyReLU Function")
ax = plt.gca()
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
plt.legend(loc='upper left', fontsize='large')
plt.savefig('fw-relu-leakyrelu.pdf')
plt.show()
实验结果:
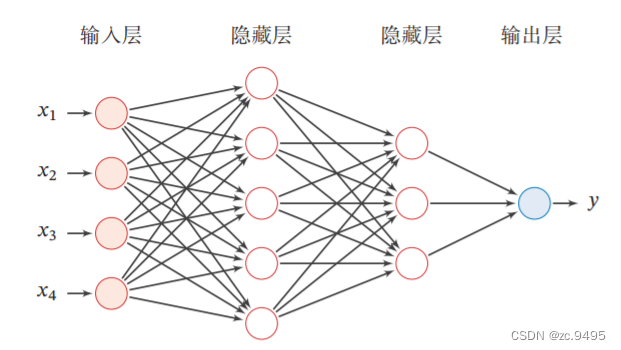
4.2 基于前馈神经网络的二分类任务
前馈神经网络的网络结构如图4.3所示。每一层获取前一层神经元的活性值,并重复上述计算得到该层的活性值,传入到下一层。整个网络中无反馈,信号从输入层向输出层逐层的单向传播,得到网络最后的输出 a(L)。
4.2.1 数据集构建
这里,我们使用第3.1.1节中构建的二分类数据集:Moon1000数据集,其中训练集640条、验证集160条、测试集200条。
该数据集的数据是从两个带噪音的弯月形状数据分布中采样得到,每个样本包含2个特征。
from nndl.dataset import make_moons
# 采样1000个样本
n_samples = 1000
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.5)
num_train = 640
num_dev = 160
num_test = 200
X_train, y_train = X[:num_train], y[:num_train]
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:]
y_train = y_train.reshape([-1,1])
y_dev = y_dev.reshape([-1,1])
y_test = y_test.reshape([-1,1])
实验结果:
outer_circ_x.shape: torch.Size([500]) outer_circ_y.shape: torch.Size([500])
inner_circ_x.shape: torch.Size([500]) inner_circ_y.shape: torch.Size([500])
after concat shape: torch.Size([1000])
X shape: torch.Size([1000, 2])
y shape: torch.Size([1000])
4.2.2 模型构建
为了更高效的构建前馈神经网络,我们先定义每一层的算子,然后再通过算子组合构建整个前馈神经网络。
假设网络的第l层的输入为第l−1层的神经元活性值a(l−1),经过一个仿射变换,得到该层神经元的净活性值z,再输入到激活函数得到该层神经元的活性值a。
在实践中,为了提高模型的处理效率,通常将N个样本归为一组进行成批地计算。假设网络第l层的输入为A(l−1)∈RN×Ml−1,其中每一行为一个样本,则前馈网络中第l层的计算公式为
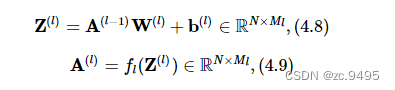
其中Z(l)为N个样本第l层神经元的净活性值,A(l)为N个样本第l层神经元的活性值,W(l)∈RMl−1×Ml为第l层的权重矩阵,b(l)∈R1×Ml为第l层的偏置。
4.2.2.1 线性层算子
from nndl.op import Op
# 实现线性层算子
class Linear(Op):
def __init__(self, input_size, output_size, name, weight_init=np.random.standard_normal, bias_init=torch.zeros):
"""
输入:
- input_size:输入数据维度
- output_size:输出数据维度
- name:算子名称
- weight_init:权重初始化方式,默认使用'paddle.standard_normal'进行标准正态分布初始化
- bias_init:偏置初始化方式,默认使用全0初始化
"""
self.params = {
}
# 初始化权重
self.params['W'] = weight_init([input_size, output_size])
# 初始化偏置
self.params['b'] = bias_init([1, output_size])
self.inputs = None
self.name = name
def forward(self, inputs):
"""
输入:
- inputs:shape=[N,input_size], N是样本数量
输出:
- outputs:预测值,shape=[N,output_size]
"""
self.inputs = inputs
outputs = torch.matmul(self.inputs, self.params['W']) + self.params['b']
return outputs
4.2.2.2 Logistic算子
class Logistic(Op):
def __init__(self):
self.inputs = None
self.outputs = None
def forward(self, inputs):
"""
输入:
- inputs: shape=[N,D]
输出:
- outputs:shape=[N,D]
"""
outputs = 1.0 / (1.0 + torch.exp(-inputs))
self.outputs = outputs
return outputs
4.2.2.3 层的串行组合
class Model_MLP_L2(Op):
def __init__(self, input_size, hidden_size, output_size):
# 线性层
self.fc1 = Linear(input_size, hidden_size, name="fc1")
# Logistic激活函数层
self.act_fn1 = Logistic()
self.fc2 = Linear(hidden_size, output_size, name="fc2")
self.act_fn2 = Logistic()
self.layers = [self.fc1, self.act_fn1, self.fc2, self.act_fn2]
def __call__(self, X):
return self.forward(X)
# 前向计算
def forward(self, X):
z1 = self.fc1(X)
a1 = self.act_fn1(z1)
z2 = self.fc2(a1)
a2 = self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









