





7.3 Modern-Day DRAM Standards
1.JEDEC-Style
(1)数据总线比较宽:在现代PC中系统中,它是64位宽,在高性能系统中它可以更宽。
(2)地址总线的宽度随着存储在单个DRAM设备中的比特数而增长; 今天典型的地址总线大约有15位宽。
(3)控制总线由行和列选通、输出使能、时钟、时钟使能和其他类似信号组成,这些信号从存储器控制器连接到系统中的每个DRAM。
(4)最后,有一个芯片选择网络,它在系统中使用每个DRAM秩一个唯一的线,从而在系统中以最大的物理存储器量进行扩展。 芯片选择用于启用多个DRAM,从而允许它们从总线读取命令,并从总线读取/写入数据。
SDRAMS和早期的异步DRAMS的主要区别是系统中存在一个时钟信号,所有动作(命令和数据传输)都是根据它来计时的。 异步DRAMS使用RAS和CAS信号作为选通。也就是说,选通直接导致DRAM从总线采样地址和/或数据,而SDRAMS使用时钟作为选通,RAS和CAS信号只是命令,它们本身通过时钟选通及时从总线采样。 使用规则的(即,周期性的)自由运行时钟而不是不太规则的RAS和CAS选通来定时传输的原因是更容易实现更高的速率; 当使用常规选通对传输进行定时时,可以减少定时不确定性,因此可以增加数据速率。
注意,任何常规定时信号都可以用于以这种方式实现更高的数据速率; 自由时钟不是必要的。 在DDR SDRAMS中,写请求的数据传输部分几乎忽略了时钟:DRAM对输入数据的采样不是针对时钟,而是针对称为DQS的单独的常规信号。 这意味着可以完全省去自由运行的时钟,其结果将非常接近IBM的切换模式。
SDRAMS使用突发数据的概念来提高带宽。 然而,SDRAM芯片不是使用CAS信号的连续切换来突发数据,而是只要求CAS被发送一次信号,并且作为响应,随着时钟的切换及时发送或接收由可编程模式寄存器中保持的值指示的比特数。一旦SDRAM接收到一个行地址和一个列地址,它就会突发对应于存储在寄存器中的突发长度值的列数。 例如,如果模式寄存器被编程为四个脉冲串长度,那么DRAM将自动将四列连续数据脉冲串到总线上。 这样就不需要切换CAS来响应微处理器请求而获得数据突发。 因此,由于减少了命令总线的使用,存储器系统中的潜在并行性增加(即,它提高了)-存储器控制器可以在它本来会切换CAS的那些周期期间向其他存储体发出其他请求。
2. Rambus
3,其他技术
(1)可编程的CAS延迟
- Use fi xed CAS latency parts.
- Explicitly identify the CAS latency in the read or write command.
- Program CAS latency by blowing fuses on the DRAM.
- Scale CAS latency with clock frequency.
(2)可编程的burst长度
在JEDEC风格的DRAM系统中,将突发长度设置为不同值的能力对于系统设计人员是方便的,也可以是系统的性能。 DRAM系统的选定参数(如请求延迟、突发长度、总线组织、总线速度和总线宽度)之间的许多微妙的交互作用可能会导致系统的性能发生显著变化,即使这些参数发生微小的变化[Cuppu&Jacob2001]。 DRAMS的突发长度的微调能力使设计者能够在给定预期工作量的情况下,为其系统提供更好的参数组合。 在大多数系统中,突发长度在系统初始化时设置一次,以后不再设置[Lee 2002,Baker 2002,Kellogg 2002,Rhoden 2002,Sussman 2002]。 替代技术包括以下方面:
- Use a short, fi xed burst length.
- Explicitly identify the burst length in the read or write command.
- Program the burst length by blowing fuses on the DRAM.
- Use a long, fi xed burst length coupled with the burst-terminate command.
- Use a BEDO-style protocol where each CAS pulse toggles out a single column of data.
(3)Dual-Edged Clocking
替代技术包括
- Use two or more interleaved memory banks on-chip and assign a different clock signal to each bank (e.g., use two or more out-of-phase clocks).
- Keep each DRAM single data rate, and inter- leave banks on the module (DIMM).
- Increase the number of pins per DRAM.
- Increase the number of pins per module.
- Double the clock frequency.
- Use simultaneous bidirectional I/O drivers.
A.在交错存储器系统中,数据总线使用的频率比任何一个DRAM存储体所能支持的频率都快; 控制电路在多个存储体之间来回切换以实现该数据速率。 使用双边缘时钟(例如,在不使用时钟的两个边缘来发送/接收数据的情况下将SDRAM的存储器带宽增加一倍或三倍甚至四倍)的替代方案是(分别)为每个DRAM指定两个、三个或四个独立的bank,并为每个存储体分配其自己的时钟信号。 存储器控制器将向DRAM发送一个请求,该请求将与分配给该存储体的时钟同步地传递到每个存储体。 因此,与其他bank相比,每个bank收到的请求将略微提前或延迟。 有两种方法可以创建不同的时钟信号:第一种实现将需要额外的DRAM引脚(每个bank一个CK引脚); 后者需要DRAM上的时钟产生和同步逻辑。
1.驱动每个不同存储体的不同时钟信号可以由存储器控制器产生(或DRAM之外的任何实体)。 因此,如果有两个交错的存储体,存储器控制器将发送两个时钟信号; 如果有四个交错的存储体,存储控制器将发送四个时钟信号; 诸如此类。
2.DRAM可以接收一个时钟信号,延迟并将其内部分配给自己的各个存储体。 因此,如果有两个交错的存储体,DRAM将把输入的时钟信号分成两种方式,延迟第二个半相位; 如果有四个交错组,DRAM将输入时钟信号分成四种方式,第二个时钟延迟四分之一个相位,第三个时钟延迟二分之一个相位,最后一个时钟延迟三个相位; 诸如此类。
B.在banks上交错存储 而不是增加单个DRAM的带宽,可以说唯一重要的地方是在DIMM层面。因此,我们可以采用SDRAM部件,并创建一个DDR DIMM规范,其中模块内电路采用单个输入时钟并交错两个或更多组DRAM(就内存控制器而言是透明的)。Kentron [2002]表明,这肯定是在我们的限制范围内,即使是在非常高的数据速率下;他们目前采用DDR部件并在模块层面上透明地交错,以实现四倍数据速率的DIMM。
C.增加DRAM数据宽度以实现更高的DRAM带宽,近年来的趋势不仅是提高DRAM速度,而且增加数据输出管脚的数量; X32零件现在很常见。 从x4到x8再到x16,以此类推,每增加一倍DRAM的数据速率。 通过将现有部件的数据宽度增加一倍来使数据速率增加一倍需要非常少的工程诀窍。 它只需要增加更多的引脚并将到每个单独DRAM的数据总线的宽度翻倍。 请注意,数据引脚的数量已从20世纪80年代末的x1增加到今天的x32,而在同一时期内,数据速率已从16 MHz增加到今天DDR SDRAM中的400 MHz时钟。 因此,JEDEC可以简单地把它们的重量更多地放在这一趋势后面,并通过增加引脚输出来增加带宽。 这种方法的优点是,它与以前的替代方案--在模块级交错多个存储体--结合得非常好,因为将DRAM的数据宽度增加一倍,就减少了实现DIMM数据宽度所需的DRAM部件数量,从而有效地将可放置在DIMM上的独立存储体数量增加一倍。 如果DRAM引脚输出增加,那么每个DIMM需要更少的DRAM来创建PC兼容系统中的64位数据总线标准。 这将在DIMM上为更多的DRAM留出额外的空间,这些DRAM可以组成额外的bank来实现交错系统。
D.增加模块数据宽度. 如前所述,人们可以认为DIMM带宽比单个DRAM的带宽更重要。 因此,可以简单地增加存储器总线的数据宽度(DIMM和存储器控制器之间的导线数量)以增加带宽,而根本不必增加单个DRAMs的时钟速度。 缺点是增加了去偏斜电路的成本。
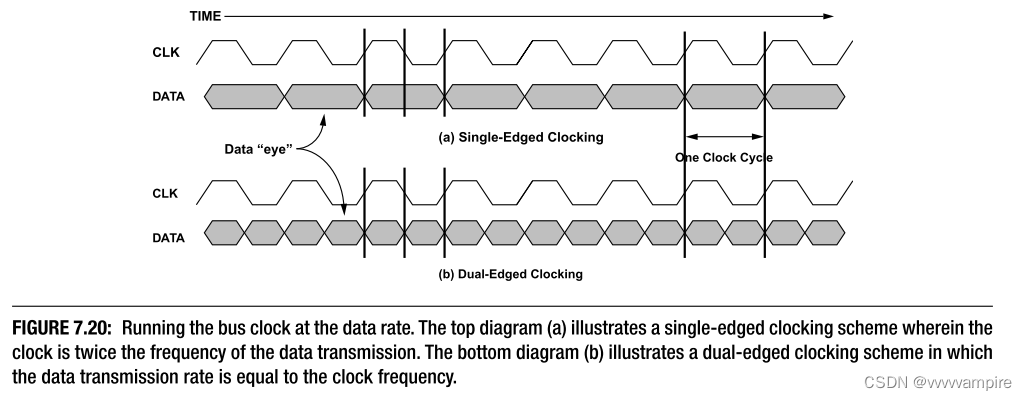
E.将时钟频率提高一倍,替代使用dual-edged时钟的另一种方法是使用single-edged时钟,并简单地加快时钟速度。 单边缘时钟方案比双边缘时钟方案有几个优点(参见图7.20)。 图7.20所示的一个优点是存在更多的时钟边沿,用于将数据驱动到总线上,并将数据采样到总线外。 另一个优点是时钟不需要像在双边时钟方案中那样对称。 单边时钟的占空比不需要为50%,因为双边时钟需要为50%,上升和下降时间(即压摆率)不需要匹配,因为双边时钟需要匹配。 因此,可以在单边时钟方案中以比双边时钟方案少得多的努力实现相同速度的时钟。 这种替代方案的缺点是,它需要更多的工程工作,而不是简单地拓宽内存总线或增加DRAM上的数据引脚数量。
E.使用同时双向I/O。以与时钟相同的速率运行数据可以使DRAM的带宽比以前的单边时钟设计增加一倍,而不会增加数据引脚的数量。 另一种选择是使用同时双向I/O,其中可以在完全相同的时间进行从DRAM的读和到DRAM的写; 也就是说,两个数据值(读数据和写数据)同时在总线上,这是可用带宽的有效倍增。 使用同时双向I/O不需要额外的数据引脚。 这种方案需要在DRAM侧进行结构改变以同时适应读和写,并且这些改变很可能类似于增强型存储器系统的ESDRAM设计[ESDRAM 1998],它是为DDR2[Davis et al.2000b]提出的。 ESDRAM在感测放大器后放置一个缓冲区,该缓冲区保存整个DRAM行用于读取,并允许并发写到DRAM阵列; 一旦读取的数据在缓冲器中,就不再需要读出放大器。
(4)On-Chip PLL/DLL
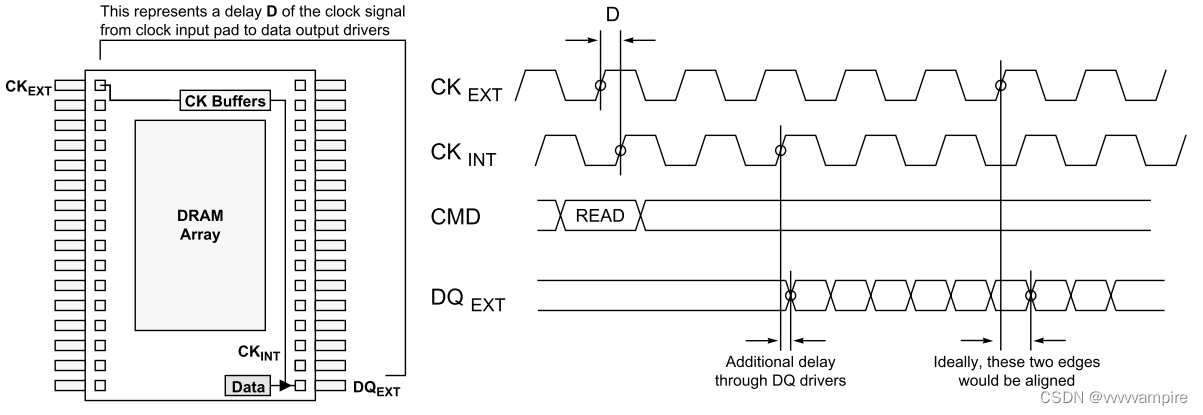
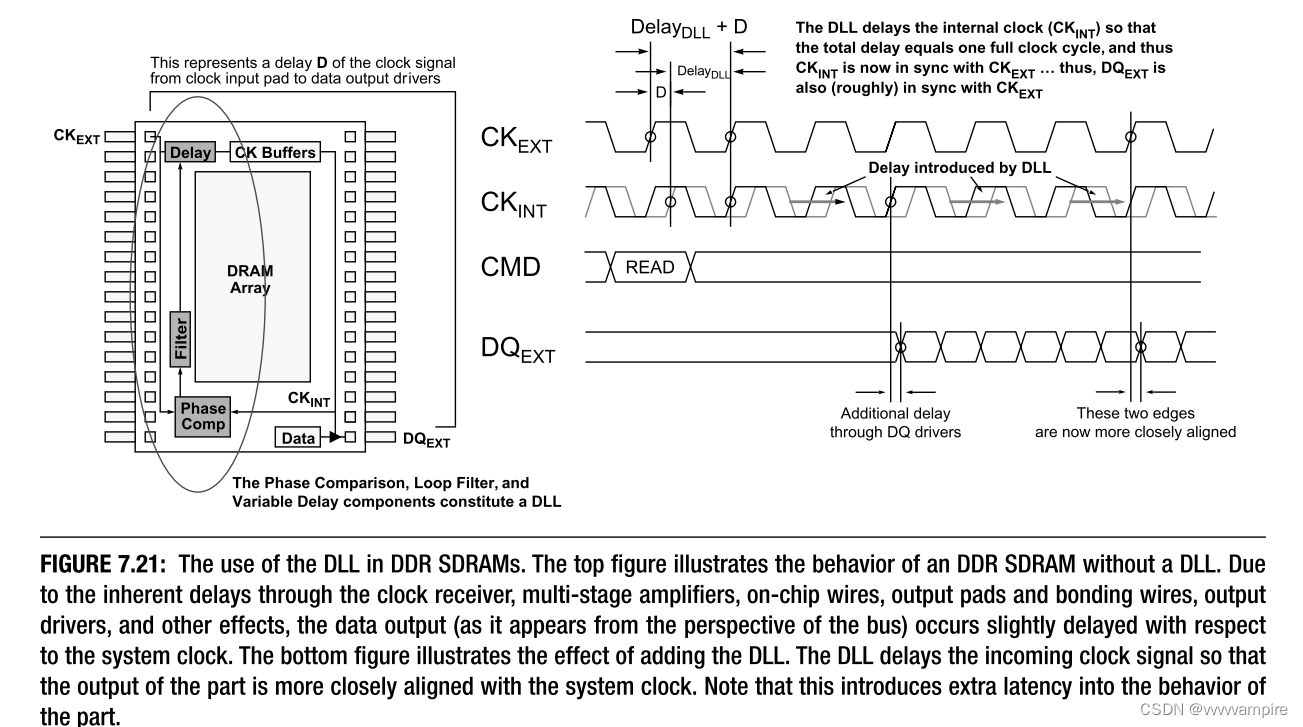
DDR SDRAMS使用片上DLL电路,以确保DRAM将其数据和DQS信号传输到存储器控制器,尽可能接近系统时钟的下一个适当边沿。 它的使用是特定的,因为DDR中的时钟速率足够高,足以保证相对强的方法来减少定时偏斜的动态变化的影响。 替代技术包括以下方面:
- Achieve high bandwidth using more DRAM pins or module pins, not clock frequency.
- Use a Vernier method to measure and account for dynamic changes in skew.
- Put the DLL on the memory controller.
- Use off-chip (on-module) DLLs.
- Use asynchronous DRAM, for example, toggle mode or BEDO.
A.在DRAM、DIMM或内存系统级别上,有许多方法可以实现更高的带宽,而不是上一节所述的更宽、更快,而且许多实现更高带宽的方法比提高时钟速度更容易实现。 DLL的使用仅取决于所需的时钟速度的增加。 因此,可以通过增加DRAM或DIMM数据宽度来放弃片上DLL的使用。
B.将DLL移到内存控制器上。因为DLL只在DRAM上用于将传出数据和DQS信号与全局时钟同步,以便于内存控制器[Lee 2002,Rhoden 2002,Karabotsos 2002,Baker 2002,Macri 2002],所以可以将该功能移到内存控制器本身。 存储器控制器可以维持两个时钟:例如,第一可以与全局时钟同步,第二可以延迟90°。 输入的DQS和数据信号可以被赋予可变延迟,延迟量由存储器控制器上的DLL/PLL控制,以便DQS信号将与延迟的时钟同相。 这种安排可以对齐输入数据,以便eye将集中在全局时钟信号上,全局时钟信号可以用来采样数据。 该方案的缺点是,当时钟速度增加到很高的速率时,不同DIMM之间的时序差异将变得明显。 因此,系统中的每个DIMM将需要存储器控制器的两个时钟之间的不同相移,这将意味着存储器控制器将需要为每个DIMM保持单独的定时结构。
C.将DLL移到DIMM上,另一种方法是将DLL放在DDR模块上,而不是DDR设备本身上。 Sun多年来一直使用这种替代方法[Becker2002,O'Donnell2002,Prein2002,Walker2002]。 此外,它在本质上类似于IBM在其高速切换模式DRAM中使用的片外驱动机制[Kalter1990a,b]。 如前所述,DDR SDRAM上的DLL的唯一功能是将传出的DQ和数据信号与全局时钟同步。 这在模块上同样容易实现,尤其是在模块被buffered或registered的情况下(这简单地意味着模块有本地存储器来保存指定给模块DRAMs的命令和地址)。 请注意,目前工程师通常禁用DDR的片上DLL以实现更高的性能--片上DLL是一种便利,而不是必需[Rhoden2002,Kellogg2002,Macri 2002]。 模块级DLL是完全可行的; 即使退出DRAM的数据与全局时钟完全不同步,模块也可以使用其DLL来延迟clock/s、命令和地址,以便DRAM的输出与全局时钟同步。 但是,这可能会以额外的CAS延迟周期为代价。
7.4 Fully Buffered DIMM: A Compromise of Sorts
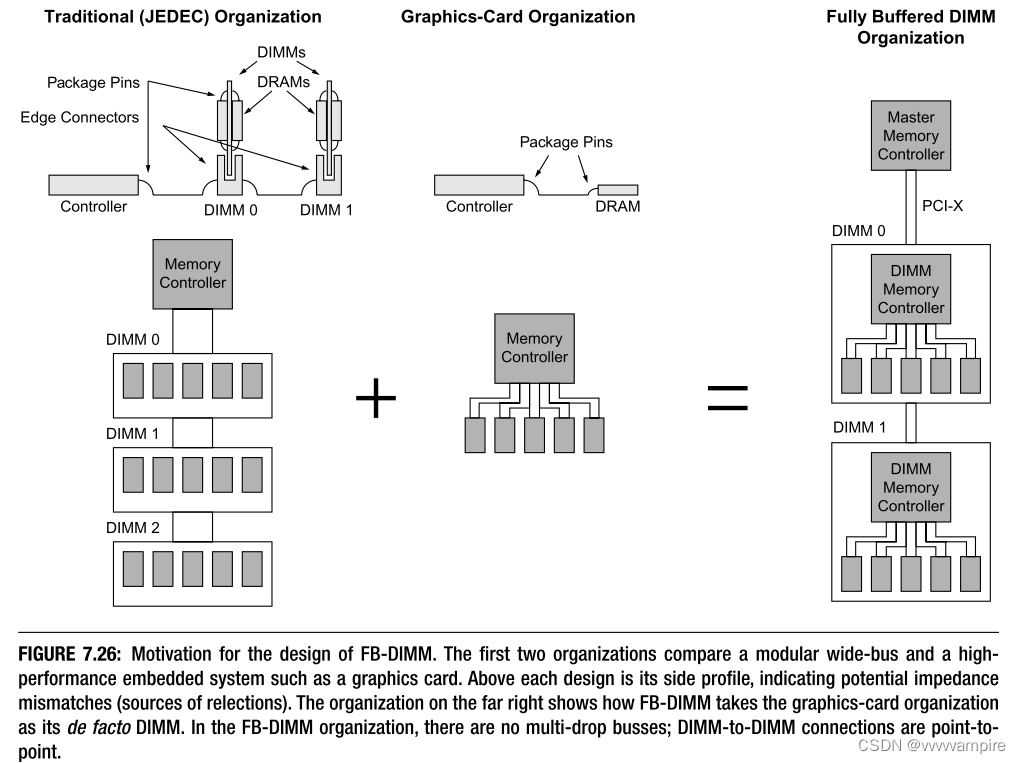
DRAM产业的一个有趣的发展是最近推出的全缓冲DIMM(FB-DIMM)。 这是英特尔开发的系统级DRAM组织,在FI RST看来,有点像传统JEDEC宽总线设计和类似Rambus的窄总线设计之间的妥协。 第14章详细介绍了FB-DIMM。 在这里,我们将简单地介绍它,并提出一个发展的动力。 系统设计者面临的一个重要趋势最终是FB-DIMM或类似的东西。 随着DRAM技术的发展,通道速度的提高是以牺牲通道容量为代价的。 SDR SDRAMs可以用八个DIMM填充一个通道。 DDR SDRAMs以更高的数据速率工作,并将每个通道的DIMM数量限制在四个。 DDR2 SDRAMs以更高的数据速率工作,并将每个通道的DIMM数量限制在两个。 DDR3有望将每个通道的DIMM数量限制在一个。 这是一个不可逾越的限制:对于服务器设计者来说,这是至关重要的,因为服务器的性能通常取决于内存的容量。趋势很明显:要提高数据速率,就必须减少总线上的下降数量。图形子系统的设计者很早就知道这一点,因为每一代DRAM都使用与商品DIMM相同的DRAM技术,但图形卡以明显更高的数据速率运行它们的DRAM,因为它们使用点对点连接。请注意,这在营销意义上是可能的,因为显卡是事实上的嵌入式系统。用户并不期望通过添加更多的内存来升级他们的显卡;而是更换整个显卡。
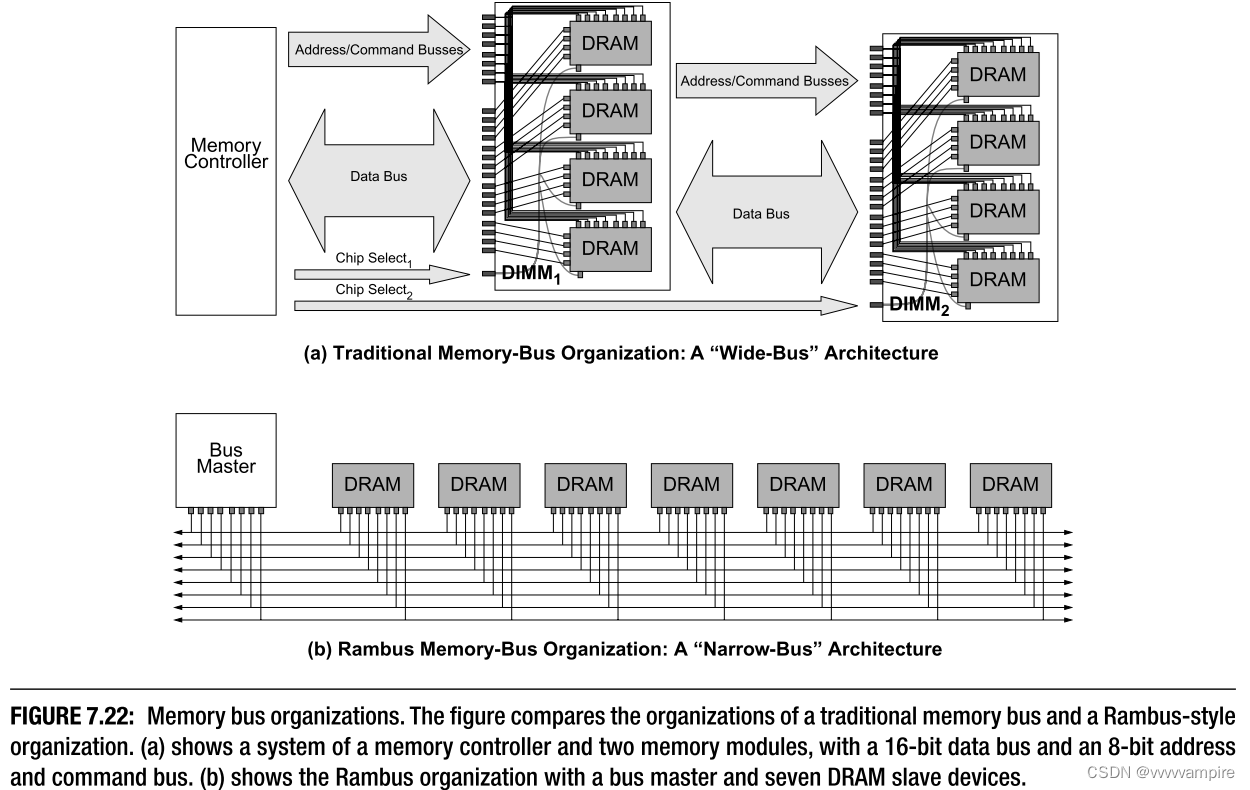
因此存在一个明显的两难问题:未来的设计者希望同时增加信道容量和数据速率。 一个人怎么能同时提供两者呢? 模块化组织和图形卡组织之间的关系如图7.26所示,它描述了图形卡典型的DRAM总线组织旁边的多点DRAM总线。 图形卡组织使用与多滴组织相同的DRAM技术,但它也使用DRAM和存储器控制器之间的点对点焊接连接,因此可以达到更高的速率。 如何利用这一点在不牺牲信道容量的情况下提高数据速率? 一个解决方案是重定义一项——在一个未来系统中,把图形卡的arrangement称为 "DIMM"。这显示在图的右侧,这正是FB-DIMM中发生的事情:内存控制器被移到DIMM上,系统中的所有连接是点对点的。基于PCI-X标准,连接主内存控制器和DIMM级内存控制器(称为高级内存缓冲器,或AMB)的通道是非常狭窄和非常快速的。此外,每个DIMM到DIMM的连接是一个点对点的连接,使整个通道成为事实上的多跳存储和转发网络。FB-DIMM架构将通道长度限制为8个DIMM,模块间总线的宽度很窄,需要的引脚数量大约是传统组织的三分之一。其结果是,FB-DIMM组织可以处理大约24倍于传统的基于DDR3的系统的存储容量(假设DDR3系统确实将被限制为每个通道一个DIMM),而不牺牲任何带宽,甚至为增加模块内带宽留出空间(注意,FB-DIMM模块应该能够达到与图形卡组织相同的性能)。
7.5 Issues in DRAM Systems, Briefly
1.每一代DRAM的带宽改善都以channel容量为代价,但也以访问粒度为代价。 DRAM设计者通过一种以空间换时间的技巧来提高DRAM I/O引脚的数据速率,而不必提高DRAM核心的速度。 DDR提高了相对于单数据速率(SDR)的速度,它采用了2N预取结构,即从DRAM内核中提取的比特数是原来的两倍。 接口一侧的带宽增加与另一侧的带宽增加相匹配; I/O端的速度是原来的两倍,而核心端的宽度是原来的两倍(在DRAM的I/O端,比特的传输速度是原来的两倍;在核心端,单个周期内获取的比特数是原来的两倍)。 DDR2通过移动到4N预取再次提高速度; DDR3有望实现8N预取。 在每种情况下,DRAM可以读或写的最小位数增加两倍。 这意味着处理器需要在每次操作中将读写的数据量增加一倍,但问题仍然是,在SRAM设计者说足够:每块128 B之前,一个缓存块将扩展多远? 256 b? 1 KB?
2.信号完整性与系统组织之间存在直接联系; 对系统组织的改变可以有效地改善或降低信号完整性。 总线拓扑结构也是如此。 例如,单向总线的设计者不需要关心周转时间,即当双向总线的主控器改变时对吞吐量的限制。 一个相关的问题是所使用的时间约定。 当拓扑发生变化时,可能需要更改定时约定以跟上。 例如,单向总线使用源同步时钟会更好地工作,但源同步时钟不像全局时钟方案那么简单。
3.引脚的成本正成为一个主要问题; 管芯上的晶体管或电容器的成本正在以惊人的速度降低,而封装成本下降的速度却没有那么快。 显而易见的结论是,在未来,DRAM设计将远比晶体管计数更关心引脚数。 唯一的方法是重新考虑协议,允许在用于数据和控制(地址、命令等)的引脚之间进行权衡,以减少器件中所需的引脚数量,而不同时减少器件的数据带宽(例如,通过简单地减少封装上的数据引脚数量)。
4.DRAMS传统上并没有考虑到设计的大部分功率或散热。 例如,DRAMS通常没有散热器,DIMM也没有。 然而,随着现代芯片间信令速率超过每引脚1 Gbps(就像现在的FB-DIMMs一样),功耗和散热都成为严重的问题。 以前的DIMM显示出1 W量级的功耗,而现在的FB-DIMM的功耗几乎是它的10倍。 将此功能与25倍数量的FB-DIMM(三倍多的通道,每通道8倍多的DIMM)相结合,您现在有一个显著的热量问题。 现代blade-服务器是一种流行的设计选择和工作方式,因为系统中只有少数几个组件会耗散热量,而DRAM从来不是其中之一。 现在,DRAM子系统有可能使blade-服务器的设计复杂化
5.目前,未来DRAM设计的主要焦点已经放在通过提高引脚速率来增加带宽上。 这只适用于有限的设计窗口。 特别是,它过于强调优化设备,而对优化系统不够。 这正是导致了概述一章中描述的系统问题的狭隘思维类型:仅在设备级别思考的设计者可能会产生系统级别的问题,就像仅在系统级别思考的设计者可能会产生设备级别的问题一样。 解决方案不是微不足道的,因为它需要面对经济争论。 DRAM是一种试图满足许多不同需求的设备。 设计解决方案必须在DIMM组织中工作,就像直接焊接到主板上一样,与微处理器一对一地交谈。 换句话说,在许多情况下,设备就是系统。 如何将这两种观点结合起来将是一个持续的问题。















 432
432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









