





近内存计算和内存计算这两个术语有时可以互换使用,而且容易混淆。本章旨在阐明各种近内存计算方法和内存计算方法的分类,并对每一类memory-driven方法的显著特征进行比较。此外,可计算的内存设备可以实现为分立的加速器设备或作为取代当前内存层次结构中的内存模块。我们将探讨每一种方法带来的好处和挑战。
Chapter2.1
根据计算结果产生的位置进行分类
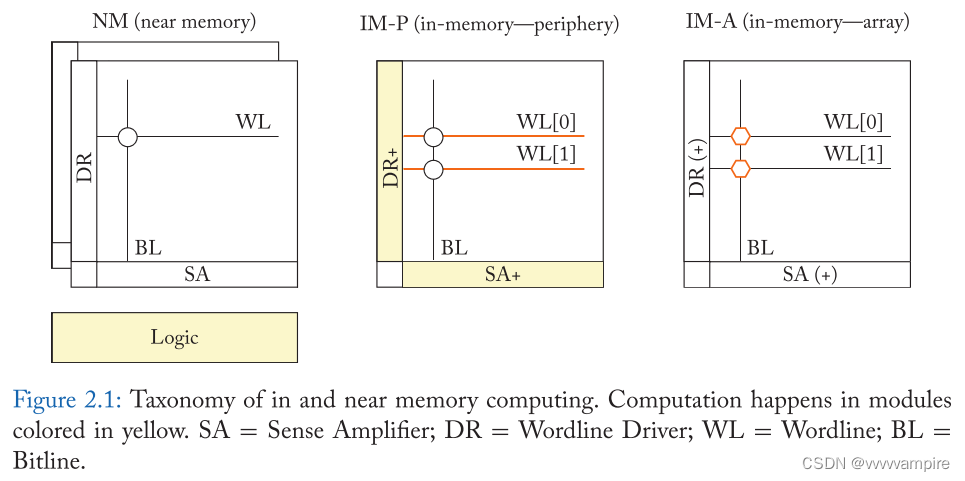
PIM作为一种克服冯·诺伊曼架构内存带宽限制的替代方法引起了研究人员的注意。其核心思想是将计算单元放在主存储器(DRAM)中,使计算单元和存储单元在物理上紧密结合在一起。这类经典的PIM方法将在3.1节中进一步解释。传统的PIM方法在将计算单元集成到DRAMdie中面临着几个关键的挑战。然而,自2010年代以来,商业上可用的3D堆叠存储器的出现,使人们对PIM产生了新的兴趣。例如,美光的混合存储立方体(HMC)在DRAM层的堆栈下包含一个逻辑层,倡导很有希望能够在逻辑层中实现自定义逻辑。第3.2节讨论了三维堆叠内存上下文中的PIM。
PIM现在经常被称为近内存计算(nearmemory computing),以避免与内存计算混淆(in-memory computing),内存计算是一种以内存为中心的计算的新范式,我们将在下一节中对其进行定义。近内存架构与传统Von Neumann架构的关键区别如下。
1. 计算逻辑被放置在内存附近,通常使用高带宽电路集成技术 (eg,2.5D和3D集成) 来利用内存内部可用的大的内存访问带宽。
2. 存储单元、存储阵列和外围电路提供对存储单元中数据的基本读写访问,它们通常保持完整。
2.5D集成电路采用硅中介层(silicon interposer)或有机中介层(silicon interposer)连接memory die和逻辑die,相对于传统的线路板上的PCB(printed circuit board)具有较高的布线密度和功效。3D集成使用层间连接技术,如硅穿孔(Through Silicon Via,TSV)和微凸体堆叠dram层(microbump to stackDRAM layers)。两者都有助于提供大的内部内存带宽和技术友好性,因为逻辑die可以使用不同的流程技术优化逻辑,激发在堆叠内存中的PIM。此外,访问存储单元的基本架构和协议也没有改变。因此,它节省了构建一个全新的存储设备的巨大设计成本。由于这些原因,一些近内存计算设备已经商业化。
Tips:
可以为PIM实现一个通用内核以提供灵活的处理。这是不正确的,因为
•在这些系统中可用的内存带宽是很高,以至于具有数十个核的通用多核处理器是利用3d PIM的一个糟糕候选。
•许多用命令式编程语言编写的应用程序利用了时间和空间的局部性,这让它们从缓存层次结构中获得了大量的好处。PIM很少有这样的缓存结构。pim的宽内存带宽可以被一类可以显露并行性或需要大带宽的应用程序更好地利用。
•与CPU芯片相比,PIM中可以分配给逻辑的区域较小。由于工艺技术的不同,PIM中的逻辑成本通常比一般逻辑die的成本更大。
•散热要求对于通用内核通常是具有挑战性的。
In-memory Computing
In-memory计算是一种以内存为中心的计算新范式,它继承了PIM和近内存计算的思想。近内存计算实现的逻辑电路独立于内存结构,而内存计算则密切地涉及到计算中的存储单元、存储阵列和外围电路。通常需要对它们进行结构上的修改或附加的特殊电路来支持计算。历史上,内存计算被认为是一种经济上不可行的设计。修改内存单元会给内存设计增加不可忽略的再投资成本,其技术已经深度优化到当前内存架构的统一单元结构上。此外,修改后的单元设计的结果将大大降低密度,这可能会对以内存为中心的架构提出挑战,以证明其性能与面积(或性能与成本)之间的权衡。
随着非易失性存储器(non-volatile memories,nvm)的出现,内存中计算的概念被重新审视。某些nvm具有理想的物理特性,可以在模拟领域执行计算,从而可以实现在内存中进行计算的同时对内存阵列的设计更改最小。此外,存储单元的非易失性本质解决了dram单元的中断读访问(disruptive read access)问题(迫使in-dram computing需要在计算前计算执行复制操作 ?)。另一方面,模拟领域的内存中计算仍然是一种风险性的技术。例如,由于工艺变化和扩展电流路径而存在的非理想性可能会影响计算结果。此外,数字到模拟转换(DAC)和模拟到数字转换(ADC)的成本将变得难以承受,因为更多的bits被用于模拟信号的转换。
与此同时,研究人员重新审视了为当前memory substrates设计的内存计算,即SRAM、DRAM和NAND闪存。他们解决了上述挑战,并利用了这些记忆的成熟技术。一些研究工作提出了NVMs可靠性的数字化计算。内存中计算方法可以进一步细分为两类,in-memory (array) 和 in-memory (periphery) 。与近内存方法相比,内存中计算能够实现对数据的大带宽访问。它不仅被用来解决内存墙问题,还被用于大规模并行处理。
- In-memory(array):使用特殊的计算操作在内存阵列中产生计算结果进行计算。IM-A架构可以提供最大的带宽和能源效率,因为操作发生在存储阵列内。IM-A还可以为简单的操作提供最大的吞吐量。另一方面,复杂的函数可能导致高延迟。此外,IM-A通常需要为这种特殊的计算操作重新设计存储单元,扩展正常的位线和字线结构。由于cells和阵列的设计和布局是针对特定的电压和电流进行大量的优化,因此cell和阵列访问方法的任何更改都需要进行大量的重新设计和表征工作。此外,为了支持IM-A计算,有时需要修改外围电路(例如,执行读写操作所需的逻辑电路,如字线驱动程序和感测放大器 word-line drivers and sense-amplifiers)。因此,IM-A包括 (a)内存阵列发生重大变化的IM-A (b)内存阵列发生重大变化而外围电路发生微小变化的IM-A。
- In-memory(periphery):在外围电路中产生计算结果。IM-P方法又可以分为数字IM-P方法和模拟IM-P方法,前者只处理数字信号,后者在模拟域中进行计算。修改后的外围电路可以进行正常读/写以外的操作,例如与不同的cell交互或加权读电压。这些修改包括支持字线驱动程序中的多行激活,以及支持multi-level激活和传感的DACs/ADCs。它们的计算范围从逻辑运算到算术运算,比如向量矩阵乘法中的点积。虽然结果是在外围电路中产生的,内存阵列依旧执行大量的计算。外围电路的变化可能需要阵列的电流/电压,而这些电流/电压与传统存储器中使用的电流/电压不同。因此,IM-P可以使用略微不同的单元设计,以保证稳健性。用于支持复杂功能的外围的额外电路可能会导致高成本。
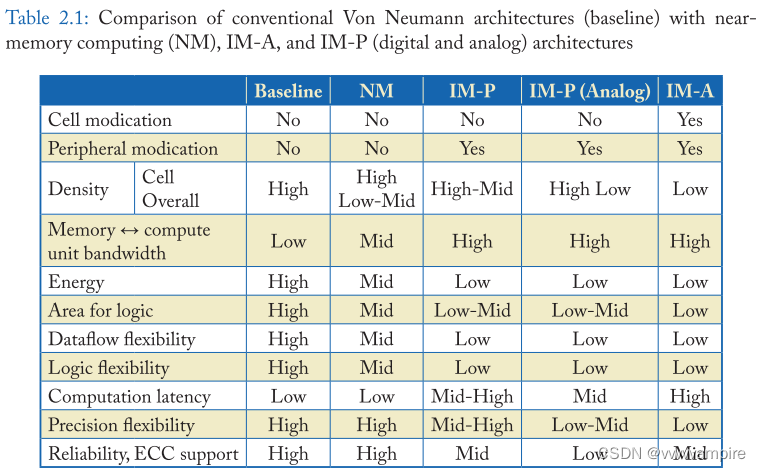
- cells和外围电路的修改:baseline和NM架构使用内存系统,因此不需要修改。IM-P为特殊的计算操作修改外围电路,而IM-A可能需要修改cells。
- 密度:由于内存阵列被大量优化,当macro的memory array 被使用时,cells密度是最高的。重要的是,当使用logic友好的内存基板(如SRAM、eDRAM)或先进的集成技术(如3D堆叠)时,整体密度(array+peripheral)对on-die逻辑的敏感度较低。一些经典的NM架构使用DRAM工艺技术在同一块DRAM芯片中实现逻辑。这样的设计可以显著地减少总体的存储密度。IM-P可能面临与NM相同的问题,但通常需要比NM更少的更改。这是因为大量的计算发生在内存数组中,需要在外设中添加更小的元素来实现与NMs相同的处理元素;因此,密度的影响较小。IM-P(模拟)具有较高的单元存储密度,但它往往在使用ADCs时需要更大的外设面积。
- 内存和计算单元之间的带宽:当计算单元远离内存时,内存带宽会减少。此外,计算单元需要支持广泛的并行性,以跟上大的带宽。因此,计算带宽要求与内存带宽高度相关。
- 能源:与计算的能源相比,数据交付消耗了大量的能源。一般来说,如果数据传输越少,消耗的能源就越少。
- 面积:面积可以解释为(a)需要做一个算术运算的逻辑区域(如加法),和(b)可用于逻辑实现的die区域。baseline和NM架构要求逻辑(a)的标准面积,但可以提供大的die面积(b) 和灵活的逻辑实现。IMs将存储阵列重新用于计算,因此需要较少的逻辑(a)面积,但其可用的die面积(b)有限。
- 数据流灵活性:一些应用程序需要非均匀的内存访问,如随机访问和间接访问(如mem[addr[i]])。为了实现这种不规则的访问,计算单元需要对内存内容具有全局可访问性。NM和IMs可能只能访问内存地址空间的一个有限区域,而远程访问会导致内存节点或内存阵列之间昂贵的all-to-all通信。
- 逻辑灵活性:逻辑的面积预算限制了可以实现的逻辑复杂性。IM-A通常每个单元只有几个额外的二极管,而IM-P每个位线有几十个门。IMs使用基本操作的组合,或求助于外部处理单元来补充操作。IM使用基本操作的组合,或求助于外部处理单元来补充操作。
- 计算延时: 由于逻辑复杂度的限制,IMs经常执行迭代操作来执行一个算术操作,从而导致较大的计算延迟。另一方面,IMs通常有一个大的计算带宽,可以补偿延迟的问题。
- 精度灵活性: 基线和NM架构可以实现任何精度的算术逻辑,包括浮点。数字IM方法可以将几个位的运算结合起来,组成任意精度的逻辑。它通常需要跨行或跨列的多个比特单元的交互,所以它们通常被归入IM-P。IM-P(模拟)可以在每个位线上以更高的位精度运行。虽然模拟计算的位精度受到许多电路因素的限制,如电容和ADC分辨率,但多个结果可以组成产生任意的整数精度。然而,为浮点精度进行扩展是具有挑战性的。
- 可靠性和ECC支持: 内存容易受到各种错误源的影响,如硬错误(如单元故障)和软错误(如宇宙辐射引起的比特翻转)。内存使用纠错码(error correcting codes ECC)来保护自己免受这些错误的影响,但是我们很少有与内存计算兼容的ECC工作。此外,模拟领域的计算会导致模拟噪音的增加。一些模拟IM-P架构使用每个单元的少量比特来增加噪声余量,或者使用aggressive(易出错的)单元配置来实现容错工作负载,如机器学习,该模型可以被训练来容忍这种错误和噪声。
Chapter2.2
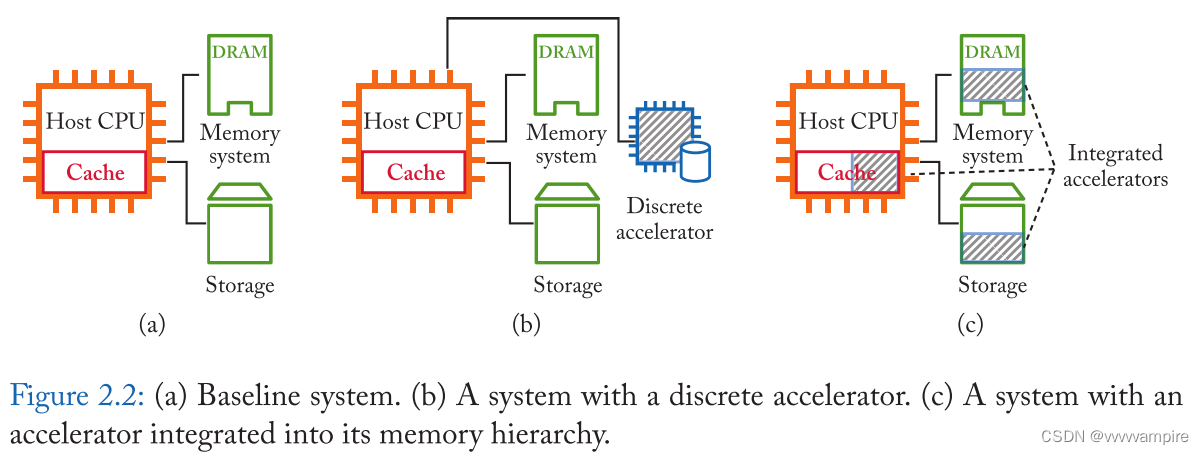
以内存为中心的体系结构在内存模块中结合了内存和计算的角色。也就是说,NM或IM内存模块既可以设计为分立加速器,也可以在现有的内存层次结构中作为集成到内存模块中的加速器.
一个分立的加速器可以不受限制地完全访问其内存空间,类似于一个scratchpad memory(注1)。离散的内存空间将加速器与操作系统的分页策略、一致性协议、数据加扰(注2)和地址加扰(注3)相解耦。它还为灵活的数据安排提供了一个控制。特别是,大多数IM架构需要在特定arrya的特定列内对准操作数,或转置输入,以位串联(bit-serial)方式处理它。分立加速器可以支持这些特定架构的数据布局而不需要太复杂。用户接口可以以库函数调用的形式提供,并与它们的驱动相连,类似于ASIC加速器。分立加速器的一个重要缺点是它们仍然需要通过外部链接(如PCIe)从内存层次中加载数据,这可能是一个瓶颈。这个问题在商业化的加速器中也持续存在:GPU通过PCIe总线将数据复制到主机内存中,需要花费非同寻常的时间。这种数据加载成本可以通过在一段时间内重复使用数据来摊销。因此,能够实现高性能的应用往往仅限于那些高重复使用或每字节高GOPs(Giga Operations per second 表示每秒可进行10亿次操作)的应用。
集成加速器是绕过内存墙的理想选择。然而,在存储器层次结构的每一层都有许多现有的方案和约束,这些方案和约束是为了访问性能和安全性而实施的,这使得设计一个成熟的集成NM/IM系统具有挑战性。例如,为了在计算前将SRAM子阵列中的操作数对齐,给它们分配足够的地址是不够的;它们需要与特定的方式相关联。DRAM使用各种扰乱技术,而且获得操作数访问的虚拟地址也需要通过操作系统的页表。NAND闪存使用闪存转换层(flash translation layer FTL),它增加了另一层地址转换,并被封装在flash设备中。许多NVM的写入耐久性有限,而这些转换层对损耗平衡(wear-leveling)有帮助。它们的干扰最终会缩短存储单元的寿命。一个集成系统需要与这些现有的框架相处,包括操作系统和编程模型,但我们还没有一个完整的解决方案。
分立加速器和集成加速器并不是相互排斥的选择。可以有一个两者的混合方法。例如,我们可以在现有的内存层次中创建一个scratchpad内存。它仍然需要从相同或更低层次的内存中复制数据,但与使用共享总线(如PCIe)导入和导出数据相比,可以期待更高的内存带宽。驱动程序还可以在计算后随时释放指定的scratchpad内存,这样它就可以作为一个标准的内存空间来使用。
注:
1.SRAM有两种组织结构,片上缓存(cache)和片上便签存储器(scratch pad memory,SPM),结构对比如下: Cache适合构建对实时性要求不高,存在复杂计算应用的系统,而SPM更适合构建对实时性、面积、功耗要求高,不包含复杂计算应用的系统。
2.正常情况下,内存数据线上的流量不是均匀分布的,可能集中出现0或1。由于能量集中,增加了发生软错误的可能性。因此通过一种Hash编码机制将真实数据转化为更加平滑的数流,降低错误发生的概率。由于将内存地址作为编码的输入之一,这种机制还可以检测内存地址包含偶数bit错误的情况。

3.地址加扰意味着从存储器外部应用的逻辑地址序列与物理内部地址序列不同。地址加扰的一个非常常见的原因是通过地址解码器中的共享。















 9069
9069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









