







Darknet 官网给出了使用已经训练好的网络结构yolo去进行实时的检测的教程
链接:https://pjreddie.com/darknet/yolo/
在安装完darknet之后,我们来试着运行一些图像检测的例子吧。
还没不知道如何安装的可以去之前的博客查看Darknet安装教程:
http://blog.csdn.net/vvyuervv/article/details/72869026
首先要说明的是,darknet官网给出的例子是使用yolo(you only look once)网络结构来对图像进行检测的。Yolo比常见的rcnn 、fast-rcnn、faster-rcnn、SSD要快,但是快的同时损失了精度。
这里给出两个效果的对照表
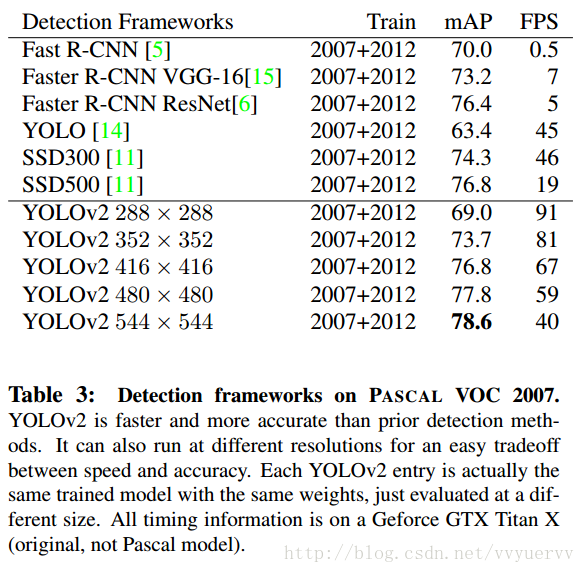
该表来自yolo的paper
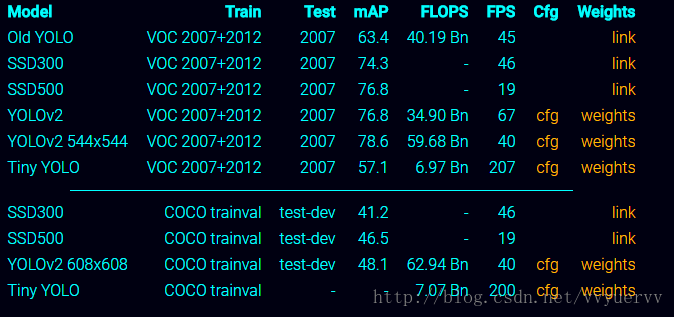
该表来自darknet官网。
由于Yolo是一个速度较快的图像检测结构,所以将其用于实时检测具有非常好的效果。Faster-rcnn虽然精度很高,但不具有实时性,所以用作实时检测的效果要不yolo差。
关于yolo的paper的具体内容,我会在之后的博客中再进一步详解,这里不再深入。本篇博客以跑通官网给出的例子为主。
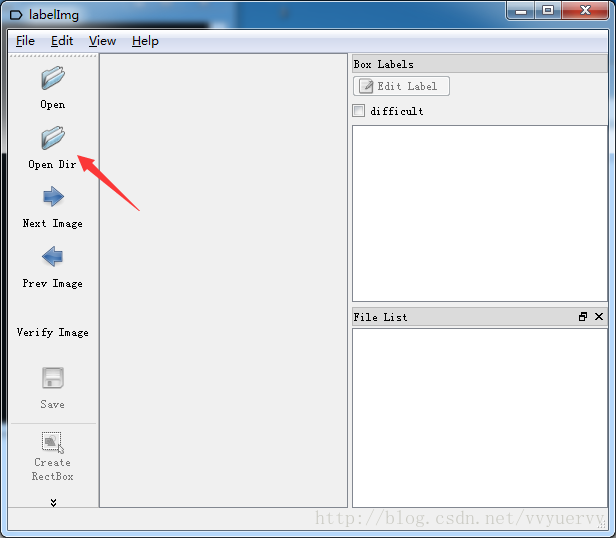
第一步:数据标注
有了自己的图像数据以后就要对图像进行标注了,常用的软件是labelimg。下载后可以直接运行,无需安装,选择打开文件夹后就可以批量导入图片了。打开后Ctrl+R选择默认存储路径(设置默认存储路径后,生成的标记文件实xml文件,切直接下一张就自动保存了,如果不设置,生成的标记文件实lif格式的文件,且需要手动保存),w开始画标签,d表示下一张图片,a表示上一张图片。
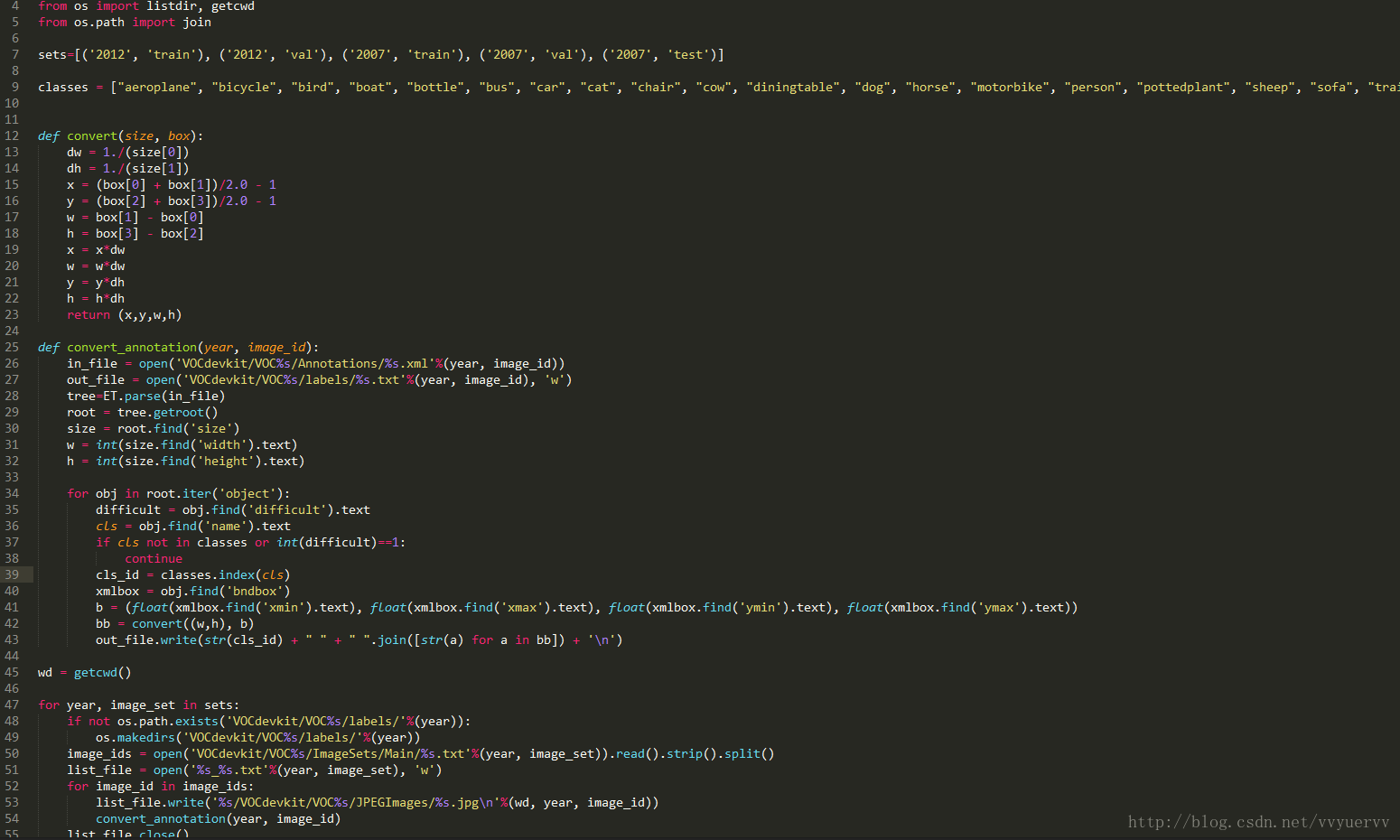
第二步:生成TXT文件
标记完后会生成每张图片对应的xml文件,也就是每张图片的label文件,我们需要提取其中的一些boundingbox的信息。
在darknet的scripts文件夹下有一个voc_label.py的文件,这个是针对voc图片集的xml生成对应图片TXT文件的脚本,根据自己的情况进行修改,生成自己的图像数据的TXT文件数据。TXT文件的内容每行都是 这种形式,且坐标和长宽都应该是归一化后的数值。
在运行voc_label.py 脚本时还会生成一个train.txt文件,改文件里存放的是每张图片的绝对路径。Train.txt是训练时需要的文件。
生成txt文件后,记得将原图像和txt文件放到同一个文件夹下。
第三步:创建一个.names文件
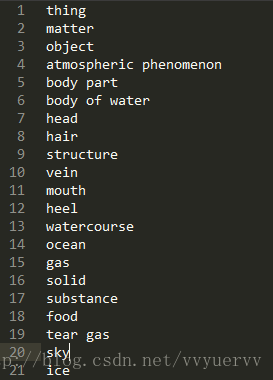
文件命名任意,例如my.names 该文件里存放的是类型的名称,每一类另起一行。
第四步:修改.data文件
之后我们修改darknet下cfg文件中的voc.data文件,当然我们也可以自己创建一个.data文件。
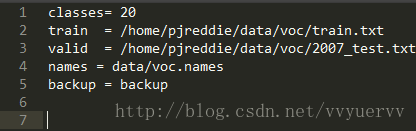
classes= 1 #训练数据的类别数目,我这里只有一类,所以这里是1
train = <path-to-voc>/train.txt #上面1.2步骤生成的train文件路径
valid = <path-to-voc>test.txt #上面1.2步骤生成的val文件路径
names = data/voc.names #上面2.1步骤创建的names文件路径
backup = backup #这是训练得到的model的存放目录,建议自己修改。根据我们实际的文件路径和类别等相关信息,对.data文件进行修改。
第五步:修改.cfg文件
假设我们使用yolo_voc.cfg网络来进行训练,我们需要到darknet/cfg/文件夹下找到yolo_voc.cfg文件进行修改。当然,使用不同的网络,要修改对应的.cfg文件。
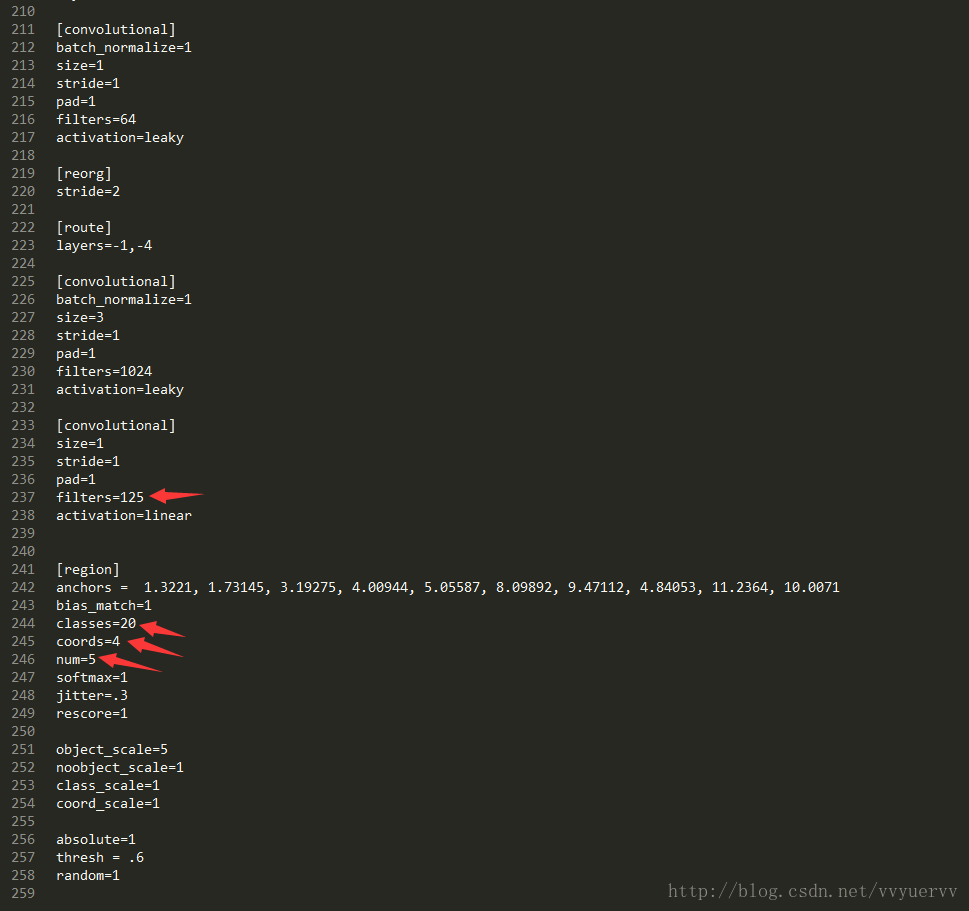
该文件有两处需要修改的地方:
第一处:[region]层中classes改成你的类别数,图片中的信息使用的是voc的数据集,有20类,所以classes=20。
第二处:[region]层上方的[convolution]层中,filters的数量改成(classes+coords+1)*NUM。上图是(20+4+1)*5=125
第六步:修改src/yolo.c文件
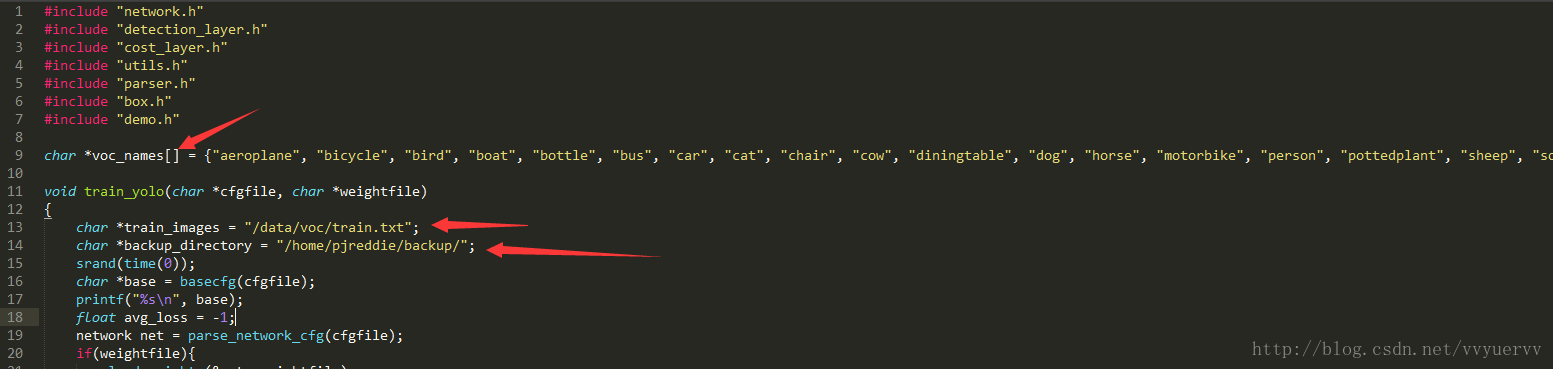
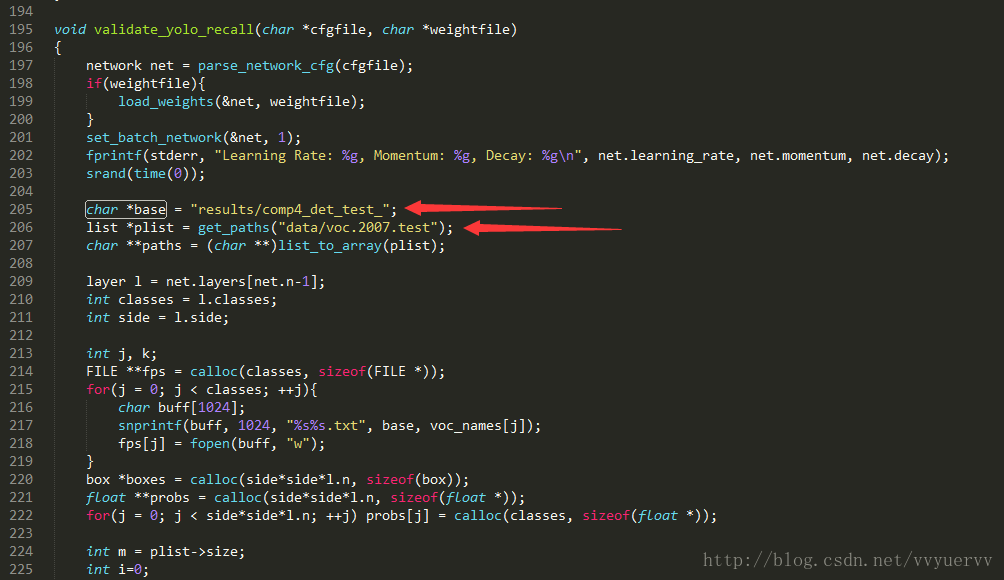
1)在文件的开始部分,也就是上图的第9行,将类别名称改成自己数据集的类别名称。
2)在文件的第13行,将训练图像的路径修改成我们在第三步生成的train.txt的文件路径。
3)在文件的第14行,将backup的路径修改为你自己想设定的存量训练权重的路径。
4)在validate_yolo()函数中,也就是上图的第117行,将路径修改为自己指定的路径。
5)在文件的第119行,将路径修改为可由第三步生成的验证集val.txt的路径。
6)在validate_yolo_recall()函数中,也就是上图的第205和206行,其修改与4)、5)的改法相同。
7)在test_yolo()函数中,有处调用draw_detections函数,也就是上图中的第318行,将其最后的参数20修改为自己训练集的类别数。
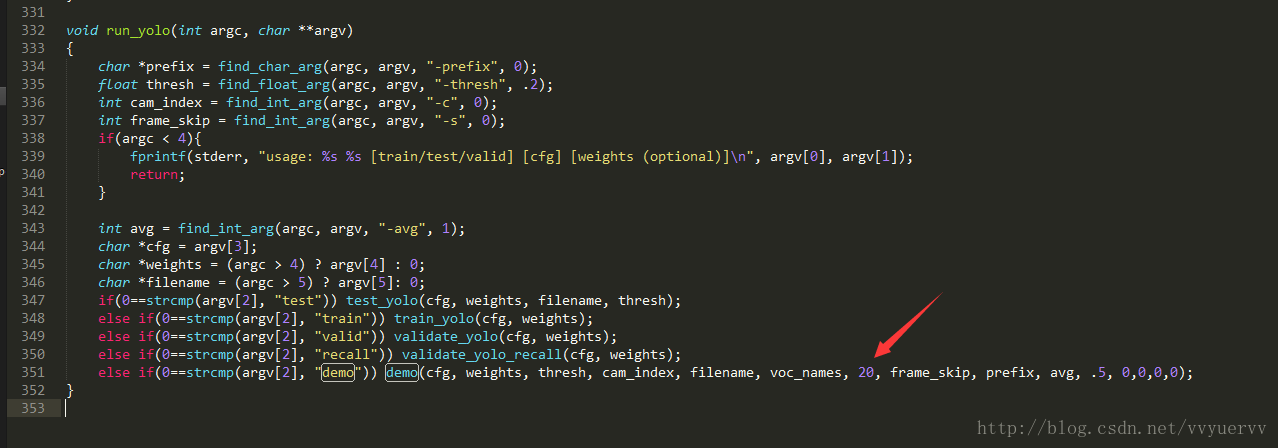
8)在文件的最后,run_yolo()函数中最后一行,也就是上图中的第351行,需要调用demo()函数,将其参数中的20修改为自己数据集的类别数。
第七步:修改src/detector.c文件
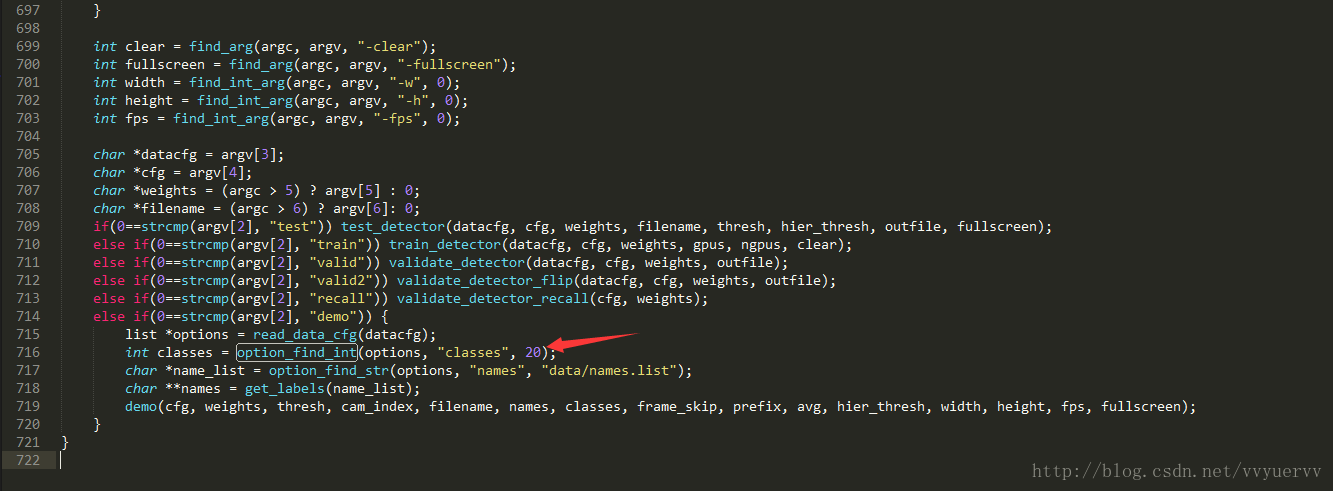
在文件的最后有个option_find_int函数,也就是上图的第716行,将其参数中的20修改为你自己数据的类别数。
有博客上讲到需要修改list *plist = get_paths(),将其内容修改为第三步生成的train.txt 文件的文件路径,但是我在文件中找到了4出该函数的调用,不确定如何修改。
也有博客上讲到需要修改src/yolo_kernels.cu文件,将draw_detections函数最后一个参数由20改成你的类别数。但是我没有找到该文件。
第八步:重新编译darknet
cd <darknet_root>
make clean
make -j 上述准备做完后便可以开始训练了。
第九步:训练
为了加速训练,我们可以先下载官网提前训练好的模型,或者使用我们之前已经训练过的模型,对现在的训练进行fine-tuning.
1../darknet detector train cfg/voc.data cfg/yolo-voc.cfg darknet19_448.conv.23
这里使用的是和官网相同的代码。进入darknet根目录下后,会有一个darknet可执行文件./darknet表示运行该文件,train表示此次为训练,也可以换成其他参数,例如test表示测试。之后跟随的是.data文件的路径,也就是我们第四步所修改的文件。再接着跟的是.cfg
文件,该文件里存放的是网络结构的定义,也就是我们第五步修改的文件。最后一个参数是我们下载的预训练好的模型。执行上述命令后,便开始训练。如何我们有多块GPU,也可以在最后加上-gpus 0,1。这表示使用第0块和第1块GPU。默认只使用第0块。
第十步:测试
测试有很多种形式,有测试单张图片的,有测试已有视屏的,有测试摄像头实时检测场景的,预测测试集,还有就是统计测试集合测试效果。
测试单张图片:
./darknet detector test cfg/voc.data cfg/yolo-voc.cfg final_voc.weights your_img_path.jpg
运行上述代码后,会在data文件夹下找到预测后的图片。
测试已有视屏:
./darknet detector demo cfg/voc.data cfg/yolo-voc.cfg final_voc.weights your_video_path.mp4
测试时会直接弹出一个窗口播放视屏,可以看是实时检测视屏的效果。
测试摄像头实时检测场景:
./darknet detector demo cfg/voc.data cfg/yolo-voc.cfg final_voc.weights
和测试已有视屏类似,运行该命令后,会调用摄像头,弹出一个窗口显示摄像头拍摄实时场景,并做实时检测。
预测测试集:
./darknet detector valid cfg/voc.data cfg/yolo-voc.cfg final_voc.weights
统计测试集合测试效果:
./darknet detector recall cfg/voc.data cfg/yolo-voc.cfg final_voc.weights
最后两个测试没有试过,所以不太清楚展出效果是什么样的。
至此,所有的训练过程都已完成。















 3835
3835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









