






FPGA 系列文章
- 如果你想学习有关FPGA的专业术语,可以参考这一篇:FPGA专业术语介绍
- 接下来列举一些我在项目中遇到的指令吧 ヽ(ˋ▽ˊ)ノ
vitis-hls指令优化小结
循环展开与优化指令
pragma HLS unroll
unroll指令能够将循环完全展开或部分展开。完全展开循环会在 RTL 内为每个循环迭代创建一份循环主体副本,使得整个循环可以并行。部分展开循环允许指定因子 N 以创建 N 份循环主体副本,并相应减少循环迭代。
使用unroll指令部分展开循环,不用保证循环边界已知,但如果要完全展开循环,在编译时循环边界必须已知,因为编译器需要知道它创建副本的数量。
以一段简单的for循环代码为例:
for(int i = 0; i < 8; i++) {
a[i] = b[i] + c[i];
}
当没有添加任何优化指令时,硬件上运行这段代码需要花费8个时钟周期,这是万万不能令人接受的。unroll指令能够帮助我们在在 RTL 设计中创建循环主体的多个副本,使得运行这段代码只耗费1个时钟周期:
for(int i = 0; i < 8; i++) {
#pragma HLS unroll
a[i] = b[i] + c[i];
}
这段代码与下面的代码是等效的,vitis-hls会将这些语句并行执行:
a[0] = b[0] + c[0];
a[1] = b[1] + c[1];
a[2] = b[2] + c[2];
a[3] = b[3] + c[3];
a[4] = b[4] + c[4];
a[5] = b[5] + c[5];
a[6] = b[6] + c[6];
a[7] = b[7] + c[7];
虽然我们一直可以手动执行循环展开,但是利用工具为我们执行循环展开明显更容易,它使代码更易阅读,并且可以减少编码错误。
unroll指令默认是全部展开的,但也可以通过设置factor参数的方式部分展开循环,例如以下代码:
for(int i = 0; i < X; i++) {
#pragma HLS unroll factor=2
a[i] = b[i] + c[i];
}
按照因子2展开的循环可以将代码有效变换为如下所示代码:
for(int i = 0; i < X; i += 2) {
a[i] = b[i] + c[i];
if (i+1 >= X) break;
a[i+1] = b[i+1] + c[i+1];
}
为了保证逻辑,需要在中间加入if判断逻辑,这会使得整个电路的控制逻辑变得复杂。但假如我们已经知道指定的展开因子(在此示例中为 2)是最大迭代计数 X 的整数因子,那么我们就可以使用skip_exit_check 参数手动移除掉if判断逻辑:
for(int i = 0; i < X; i++) {
#pragma HLS unroll factor=2 skip_exit_check
a[i] = b[i] + c[i];
}
这样一来,代码就可以有效的变换成我们想要的代码了:
for(int i = 0; i < X; i += 2) {
a[i] = b[i] + c[i];
a[i+1] = b[i+1] + c[i+1];
}
由于项目中片上资源还是比较充足的,因此除非遇到边界不确定的情况,否则我很少使用到factor这个参数,对于小循环直接全部展开,而对大循环使用pipeline优化。
pragma HLS loop_flatten
loop_flatten指令允许把嵌套循环平铺为已改善时延的单一循环层级,举一个简单的例子:
void foo (int num_samples, int result, int a, int b) {
loop_1:
for(int i = 0; i < num_samples; i++) {
loop_2:
for(int j = 0; j < 2; j++) {
#pragma HLS loop_flatten
result = a + b;
}
}
}
在这个例子中,无论是从loop_1移动到loop_2,还是从loop_2移动到loop_1,都需要额外花费一个时钟周期的时间。loop_flatten指令能够通过嵌套循环平铺的方式将loop_1与loop_2作为单一循环,节省时钟周期。
只有在完美循环嵌套或半完美循环嵌套时,才能够使用loop_flatten指令!!
完美循环嵌套
- 仅限最内层循环才包含循环主体内容。
- 在循环语句之间不指定任何逻辑。
- 所有循环边界均为常量。
半完美循环嵌套
- 仅限最内层循环才包含循环主体内容。
- 在循环语句之间不指定任何逻辑。
- 最外层的循环边界可采用变量。
非完美循环嵌套
- 当内层循环具有变量边界或者循环主体未完全包含在内层循环内时,请尝试重构代码或者将循环主体中的循环展开以创建完美循环嵌套。
还是上面的例子,当内层循环具有变量边界时,它就是一个非完美循环嵌套:
void foo (int num_samples, int result, int a, int b) {
loop_1:
for(int i = 0; i < num_samples; i++) {
loop_2:
for(int j = 0; j < num_samples; j++) { // 内层循环具有变量边界
#pragma HLS loop_flatten
result = a + b;
}
}
}
循环主体未完全包含在内层循环内时,它同样是一个非完美循环嵌套:
void foo (int num_samples, int result, int a, int b) {
loop_1:
for(int i = 0; i < num_samples; i++) {
loop_2:
result = a;// 循环主体未完全包含在内层循环内
for(int j = 0; j < 2; j++) {
#pragma HLS loop_flatten
result = a + b;
}
result = b;// 循环主体未完全包含在内层循环内
}
}
loop_flatten指令同样可以用于多个嵌套循环之中,需要将loop_flatten指令应用于循环层级的最内层循环的循环主体,所有内层循环均需要使用常量,并且循环语句之间不能指定任何逻辑:
void foo (int num_samples, int result, int a, int b) {
loop_1:
for(int i = 0; i < num_samples; i++) {
loop_2:
for(int j = 0; j < 2; j++) {
loop_3:
for(int k = 0; k < 2; k++) {
#pragma HLS loop_flatten
result = a + b;
}
}
}
}
pragma HLS loop_merge
和loop_flatten指令类似,连续循环之间同样需要耗费额外的时钟周期。loop_merge指令能够将连续循环合并到单个循环内,以缩短总体时延、增加共享,并提升逻辑最优化。
合并循环的规则是:
- 如果循环边界为变量,则值(迭代数)必须相同。
- 如果循环边界为常量,那么最大常量值用作为合并循环的边界。
- 具有变量边界的循环与具有常量边界的循环无法合并。
- 要合并的循环之间的代码不得产生不同结果(例如loop_1的代码声明a=1,loop2的代码声明a=2,这是不允许的,因为合并完之后语句会并行执行)
- 多次执行此代码应生成相同结果(允许使用a=b,不允许使用 a=a+1,个人理解,合并过后的循环执行次数可能和原来不一样,HLS会自动进行优化)
- 包含 FIFO 读取的循环无法合并。合并会更改读取顺序。从 FIFO 或 FIFO接口执行读取必须始终按顺序进行。
这里仅举一个能够成功合并的例子:
void foo (int num_samples, int a, int b) {
#pragma HLS loop_merge
loop_1:
for(int i=0;i< num_samples;i++) {
a = 1;
}
loop_2:
for(int j=0;j< num_samples;j++) {
b = 2;
}
}
由于这条指令的应用条件十分苛刻,因此很少使用。一般直接通过代码重构的方式对连续循环进行优化。
流水线指令
pragma HLS pipeline
通过流水线提高性能是计算机架构设计的8个伟大思想之一,不管是硬件设计还是软件设计,流水线设计(pipeline)都能够用更多的资源来实现高速。流水线设计的具体内容在我看到的这篇博客【FPGA中流水线的原因和方法】中讲的很明白,这里不再赘述。
在HLS中,pipeline指令单指函数内部的流水,举一个简单的例子:
void func(int m, int n, int o){
for(int i = 2; i >= 0; i--){
#pragma HLS pipeline ii = 1
op_Read;
op_Compute;
op_Write;
}
}
我们可以使用II参数指定期望的流水线启动时间间隔,HLS工具会尝试满足此请求,但根据数据之间的依赖关系,最终的II可能会更大。
以下是官方示意图:

pragma HLS dataflow / pragma HLS stream
dataflow指令通常和stream指令一起使用,可以启用任务级流水打拍,允许函数和循环在其操作过程中重叠,增加 RTL 实现的并发度,并增加设计的整体吞吐量。在功能上,任务级流水线和函数内部的流水十分相似。
举一个简单的例子:
void top(int a, int b, int c,int d){
# pragma HLS dataflow
func_A(a,b,i1);
func_B(c,i1,i2);
func_C(i2,d);
}
以下是官方示意图:

为什么有pipeline指令,还需要用到任务级流水线?
假如一个函数用到的资源过多,那么单个函数内的走线就会过长,这会导致时序违规。
以下行为可能阻止或限制 Vitis HLS 可在数据流模型内执行的重叠:
- 在数据流区域中间读取函数输入或写入函数输出。
- 单一生产者使用者违例。
- 任务的有条件执行。
- 含多个退出条件的循环
由于篇幅原因,这里就不细讲了,详情可以参考Vitis高层次综合用户指南 (UG1399)
阵列优化指令
pragma HLS array_partition
array_partition指令能够将阵列分区为更小的阵列或者独立元素,并提供下列特性:
- 生成包含多个小型存储器或多个寄存器(而不是一个大型存储器)的 RTL。
- 有效增加存储器读写端口数量。
- 可能改善设计吞吐量。
- 需要更多存储器实例或寄存器。
对于array_partition指令,常用的参数有四个,这里直接把文档的内容贴过来:
variable=<name>
必要实参,用于指定要分区的阵列变量。
type=<type>
(可选)指定分区类型。默认类型为 complete。支持以下类型:
- cyclic
循环分区会通过交织来自原始阵列的元素来创建更小的阵列。该阵列按循环进行分区,具体方式是在每个新阵列中放入一个元素,然后回到第一个阵列以重复该循环直至阵列完全完成分区为止。例如,如果使用 factor=3:
- 向第 1 个新阵列分配元素 0。
- 向第 2 个新阵列分配元素 1。
- 向第 3 个新阵列分配元素 2。
- 向第 4 个新阵列分配元素 3。
- block
块分区会从原始阵列的连续块创建更小阵列。这样可将阵列有效分区为 N 个相等的块,其中 N 为 factor=实参定义的整数。
- complete
完全分区可将阵列分解为多个独立元素。对于一维阵列,这对应于将存储器解析为独立寄存器。这是默认<type>。
factor=<int>
指定要创建的更小的阵列数量。对于 complete 型分区,不指定该因子。对于 block 和 cyclic 型分区,需指定 factor=。
dim=<int>
指定要分区的多维阵列的维度。针对含N维的阵列,指定范围介于0到N之间的整数。
- 如果使用0值,则使用指定的类型和因子选项对多维阵列的所有维度进行分区。
- 任意非零值均表示只对指定维度进行分区。例如,如果使用的值为 1,则仅对第 1 个维度进行分区。
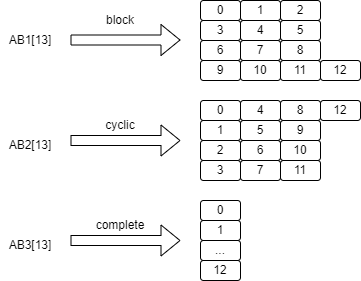
对于一维数组,给定如下代码:
int AB1[13];
int AB2[13];
int AB3[13];
#pragma HLS array_partition variable=AB1 type=block factor=4
#pragma HLS array_partition variable=AB2 type=cycle factor=4
#pragma HLS array_partition variable=AB3 type=complete
array_partition指令能够将阵列转换为下图所示形式:
pragma HLS array_reshape
array_reshape指令与array_partition指令的功能类似,能够重构阵列,并提供对数据的并行访问。对于一维数组,给定如下代码:
void foo (...) {
int array1[N];
int array2[N];
int array3[N];
#pragma HLS array_reshape variable=array1 type=block factor=2 dim=1
#pragma HLS array_reshape variable=array2 type=cycle factor=2 dim=1
#pragma HLS array_reshape variable=array3 type=complete dim=1
...
}
array_reshape指令能够将阵列转换为下图所示形式:
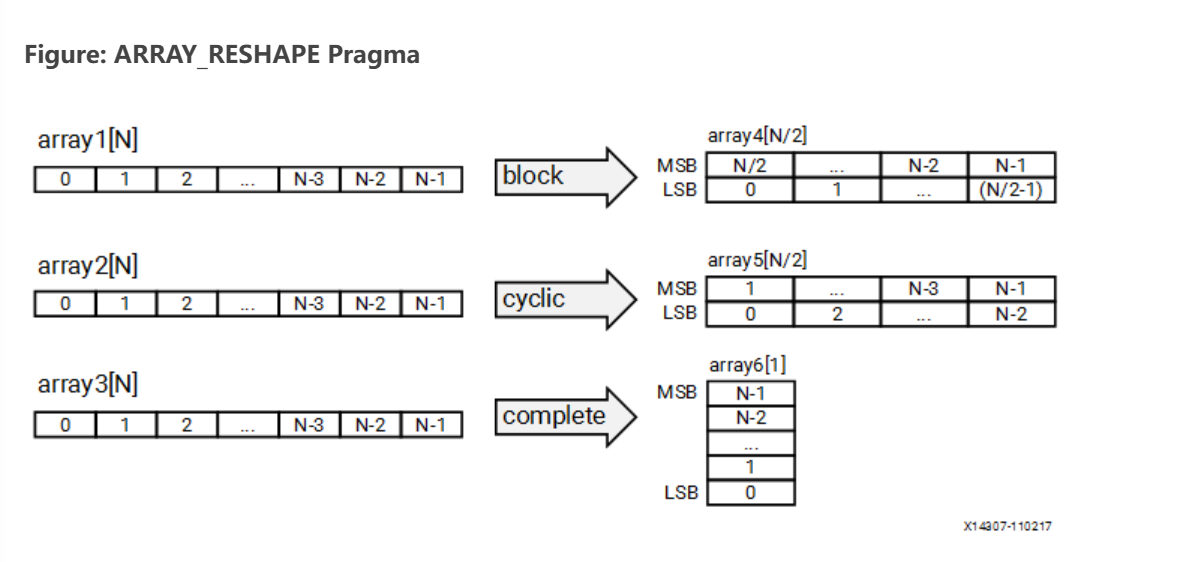
看到这里有些读者可能就有点困惑了,这张图和array_partition的示意图十分类似,那为什么有了array_partition指令,还需要array_reshape指令呢?
先简单概括一下二者的区别:
- array_partition指令更加灵活。
- array_reshape指令更加节约资源,并且在时序较差的情况下有奇效。
接下来举一个二维数组的例子,对于二维数组,最经典的设计莫过于矩阵乘法了,给定如下代码:
void matrixmul(int A[N][M], int B[M][P], int AB[N][P]) {
#pragma HLS array_reshape variable=A complete dim=2
#pragma HLS array_reshape variable=B complete dim=1
/* for each row and column of AB */
row: for(int i = 0; i < N; ++i) {
col: for(int j = 0; j < P; ++j) {
#pragma HLS PIPELINE II=1
/* compute (AB)i,j */
int ABij = 0;
product: for(int k = 0; k < M; ++k) {
ABij += A[i][k] * B[k][j];
}
AB[i][j] = ABij;
}
}
}
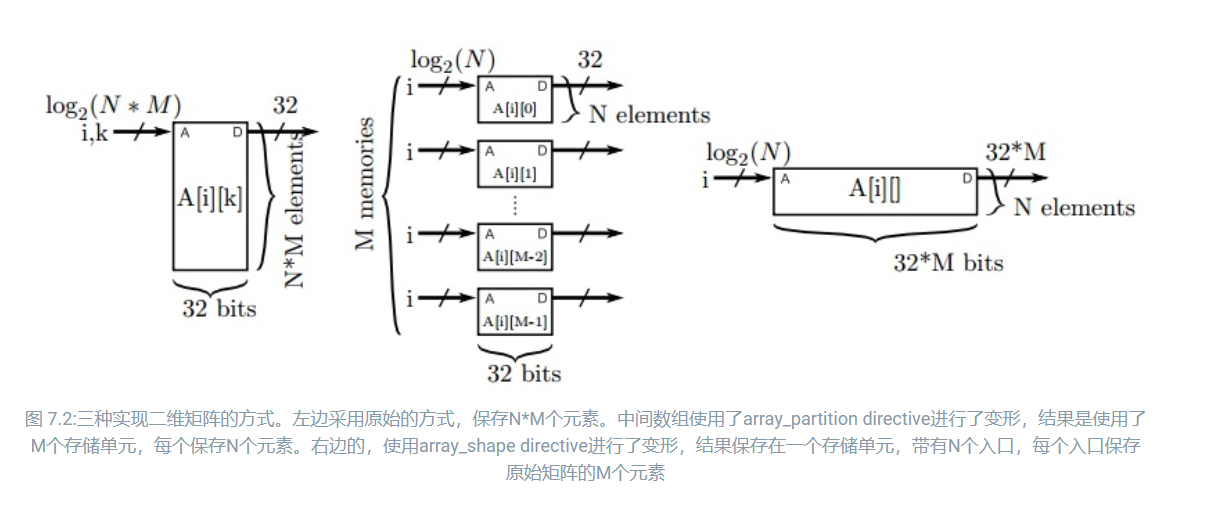
上面的代码使用了array_reshape指令提高了一个时钟周期内可以读取的数组元素个数,当然使用array_partition也是可以的,它们支持相同的操作,可以循环和阻塞分块或者根据多维度的数据进行不同维度的分块。
但是!!!在使用array_reshape的时候,所有的元素在变换后的数组中共用同一个地址,而array_partition变换后数组中地址是不相关的。
- array_partition虽然灵活,每个独立的小空间更小,但可能会导致存储资源使用不充分。
- array_reshape会形成大的存储块,这样可能更容易高效地映射到FPGA 的资源上。
假设板卡上最小的BRAM是18Kbits,可以支持不同深度和宽度的组合,那么对于维度是[1024][4] 的4-bit数组:如果使用array_partition指令,就会使用4个BRAM将数组配置为4个 1Kbit x 4,每个BRAM都没有被充分利用;但如果使用array_reshape指令,就会使用1个BRAM将数组配置为1个4Kbit x 4。
这是《FPGA并行编程》中的示意图,直观的表明了两个指令之间的区别:














 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









