







感想
介绍
分类是监督学习的一种形式,我们用带有类标记或者类输出的训练样本训练模型(也就是通过输出的结果监督被训练的模型)。
分类模型适用于很多情形,一些常见的例子如下:
· 预测互联网用户对在线广告的点击概率,这本质上是一个二分类问题(点击或者不点击);
· 检测欺诈,这同样是一个二分类问题(欺诈或者不是欺诈);
· 预测拖欠贷款(二分类问题);
· 对图片,视频或者声音分类(大多情况下是多分类,并且有许多不同的类别);
· 对新闻,网页或者其他内容标记类别或者打标签(多分类);
· 发现垃圾邮件,垃圾页面,网络入侵和其他恶意行为(二分类或者多分类);
· 检测故障,比如计算机系统或者网络的故障检测;
· 根据顾客或者用户购买产品或者使用服务的概率对他们进行排序(这可以建立分类模型预测概率并根据概率从大到小排序);
· 预测顾客或者用户中谁有可能停止使用某个产品或服务。
上面仅仅列举了一些可行的用例。实际上,在现代公司特别是在线公司中,分类方法可以说是机器学习和统计领域使用最广泛的技术之一。
1.分类模型的种类
这里讨论Spark中常见的三种分类模型:线性模型,决策树和朴素贝叶斯模型。线性模型,简单而且相对容易扩展到非常大的数据集;巨册书是一个强大的非线性技术,训练过程计算量大并且较难拓展(MLib会替我们考虑拓展性的问题),但是在很多情况下性能很好;朴素贝叶斯模型简单,易训练,并且具有高效和并行的优点(实际中,模型训练只需要遍历所有数据集一次)。当采用合适的特征工程,这些模型在很多应用中都能达到不错的性能。而且,朴素贝叶斯模型可以作为一个很好的模型测试基准,用于比较其他模型的性能。
Spark的MLib库提供了基于线性模型,决策树和朴素贝叶斯的二分类模型,以及基于决策树和朴素贝叶斯的多分类模型。
1.1线性模型
线性模型的核心思想是对样本的预测结果(通常称为目标或者因变量)进行建模,即对输入变量(特征或者自变量)应用简单的线性预测函数。
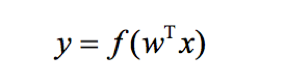
这里y是目标变量,w是参数向量(也称为权重向量),x是输入的特征向量。
实际上,通过简单改变连接函数f,线性模型不仅可以用于分类还可以用于回归。标准的线性回归使用对等连接函数(identity link,即直接使用y=fwTx),而线性分类器使用上面提到的连接函数(f)。
在线广告的例子。例子中,如果网页中展示的广告没有被点击,则目标变量标记为0(在数学表示中通常使用-1),如果发生点击,则目标变量标记为1.每次曝光的特征向量由曝光事件相关的变量组成(比如用户,网页,广告和广告客户,以及设备类型,事件,地理位置等其他因素相关的特征)。
于是,我们要训练一个模型,将给定输入的特征向量(广告曝光)映射到预测的输出(点击或者未点击)。对于一个新的数据点,我们将得到一个新的特征向量(此时不知道预测的目标输出),并将其与权重向量进行点积。然后对点积德结果应用连接函数,最后函数的结果便是预测的输出(在一些模型中,还会将输出结果与设定的阈值进行判断后得到预测结果)。
给定输入数据的特征向量和相关的目标值,存在一个权重向量能够最好对数据进行拟合,拟合的过程即最小化模型输出与实际值的误差。这个过程称为模型的拟合,训练或者优化。
具体来说,我们需要找到一个权重向量能够最小化所有训练样本的损失函数计算出来的损失(误差)之和。损失函数的输入是给定的训练样本的权重向量,特征向量和实际输出,输出是损失。实际上,损失函数也被定义为连接函数,每个分类或者回归函数会有对应的损失函数。
本章介绍MLib提供的两个适合二分类模型的损失函数。第一个是逻辑损失(logistic loss),等价于逻辑回归模型。第二个是合页损失(hinge loss),等价于线性支持向量机(SVM)。这里的SVM严格上不属于广义线性模型的统计框架,但是当制定损失函数和连接函数时在使用方法上相同。
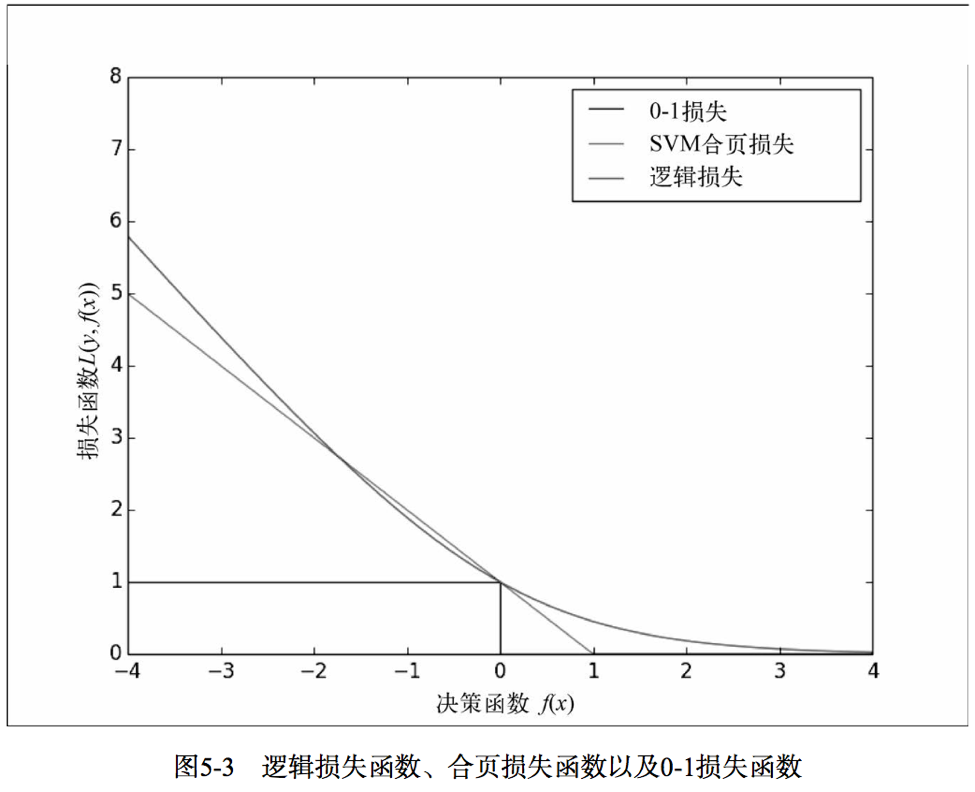
图5-3展示了与0-1损失相关的逻辑损失和合页损失。对二分类来说,0-1损失的值在模型预测正确时为0,在模型预测错误时为1,实际中,0-1损失并不常用,原因是这个损失函数不可微分,计算梯度非常困难并且难以优化。而其他的损失函数作为0-1损失的近似可以进行优化。
1.逻辑回归
逻辑回归是一个概率模型,也就是说该模型的预测结果的阈值为[0,1]。对于二分类来说,逻辑回归的输出等价于模型预测某个数据点属于正类的概率估计。逻辑回归是线性分类模型使用最广泛的一个。
逻辑回归的连接函数为逻辑连接:
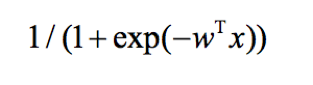
逻辑回归的损失函数是逻辑损失:
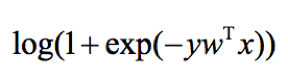
其中y是实际的输出值(正类为1,负类为-1).
这里推导一下上面的损失函数:
logistic回归的本质是:

对于训练样例集:
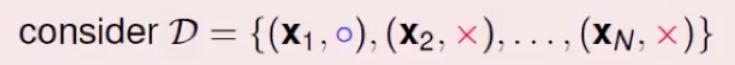
我们的预测输出是f,逻辑回归输出是h,我们要做的事让h的输出和f越接近越好,我们用极大似然估计,即让正确输出的概率做所有可能的输出概率中最大。即让下面的式子最大化。

逻辑回归用的是sigmoid函数,他有一个对称性质:

由于所有求解中,P(x1),P(x2)…都是一样的,求解时可不用考虑,因此可以进一步化简:
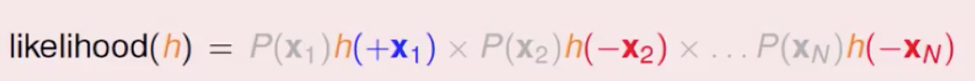
由于y取+1和-1,我们可以进一步简化:

逻辑回归主要训练的事权值,因此,我们把w带进去,来求取使得式子最大的w的值。
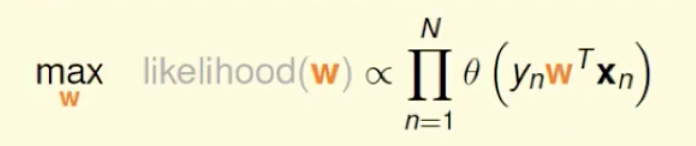
为了计算方便,对式子取log对数,然后乘以一个符号,这样就变成了
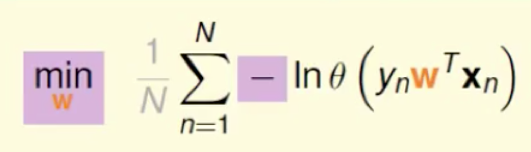
N为样本集的个数,对所有的优化式子都以一样,加了是为了做scale:
把sigmoid函数带进去得到:
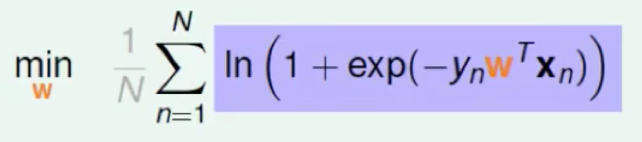
这样就得到上面的损失函数了,推导过程不简单,如有不清楚的话,可以留言哈。
2. 线性支持向量机
SVM在回归和分类方面是一个强大且流行的技术。和逻辑回归不同,SVM并不是概率模型,但是可以基于模型对正负的估计预测类别。
SVM的连接函数是一个对等连接函数,因此预测的输出表示为:
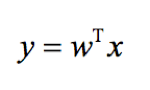
因此,当wTx的估计值大于等于阈值0时,SVM对数据点标记为1,否则标记为0(其中阈值是SVM可以自适应的模型参数)。
SVM的损失函数被称为合页损失,定义为:
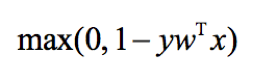
SVM是一个最大间隔分类器,它试图训练一个使得类别尽可能分开的权重向量。在很多分类任务中,SVM不仅表现得性能突出,而且对大数据集的拓展是线性变化的。
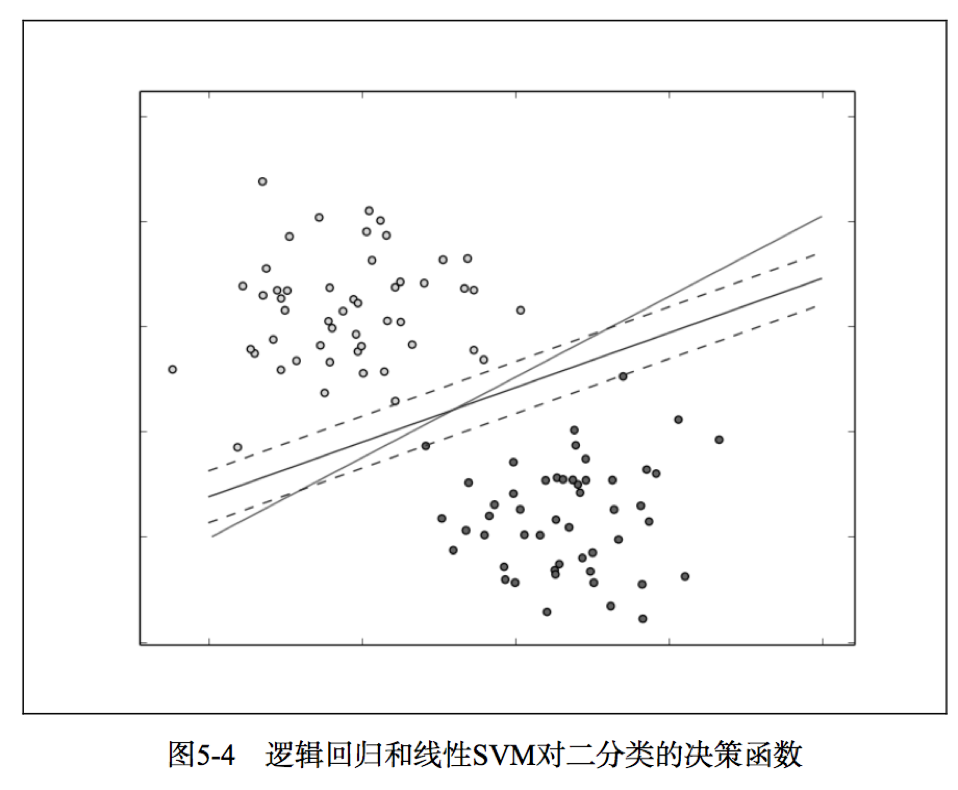
如图可以看出SVM可以有效定位到最靠近决策函数的数据点,中间与虚线平行的是SVM分类器,不平行的是逻辑回归的。
SVM的求解很复杂,浅析的话,可以参考我前面的SVM博客。有兴趣的话可以自行推导一下,我用了差不多两周的时间推导了一下SVM,有什么问题的话,可以私聊,和我探讨一下,以后有时间了写一篇完整的SVM推导。
1.2 朴素贝叶斯模型
朴素贝叶斯是一个概率模型,通过计算给定数据点的某个类别的概率进行预测。朴素贝叶斯模型假定每个特征分配到某个类别的概率是独立分布的(假定各个特征之间条件独立)。
基于这个假设,属于某个类别的概率表示为若干概率乘积的函数,其中这些概率包括某个特征在给定某个类别的条件下出现的概率(条件概率),以及该类别的概率(先验概率)。这样使得模型训练非常直接且易于处理。类别的先验概率和特征的条件概率可以通过数据的频率估计得到。分类过程就是在给定特征和类别概率的情况下选择最可能的类别。
另外还有一个关于特征分布的假设,即参数的估计来自数据。MLib实现了多项朴素贝叶斯,其中假设特征分布是多项分布,用以表示特征的非负概率统计。
朴素贝叶斯的原理非常简单,我这里不做过多的解释了。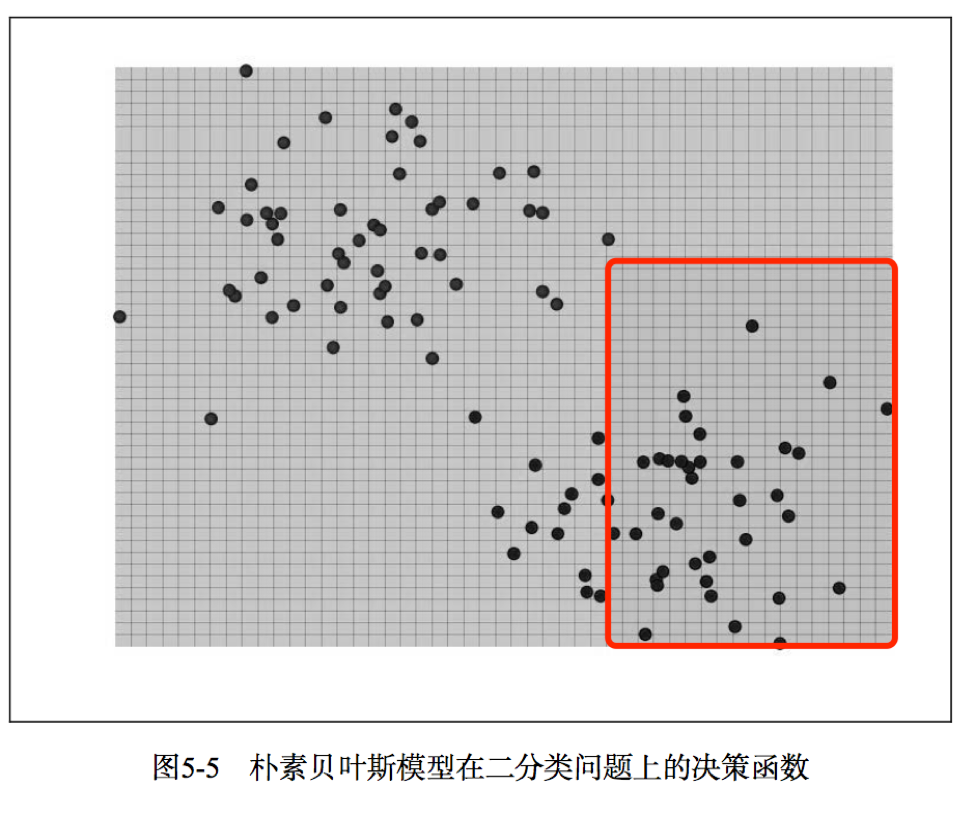
图5-5展示了朴素贝叶斯在二分类样本上的决策函数。
1.3 决策树
决策树是一个强大的非概率模型,它可以表达复杂的非线性模式和特征相互关系。决策树在很多任务上表现出的性能很好,相对容易理解和解释,可以处理类属或者数值特征,同时不要求输入数据归一化或者标准化。决策树非常适合应用集成方法,比如多个决策树的集成,称为决策树森林。
决策树模型就好比一棵树,叶子代表值为0或1的分类,树枝代表特征。如图5-6所示,二元输出分别是“待在家里”和“去海滩”,特征则是天气。
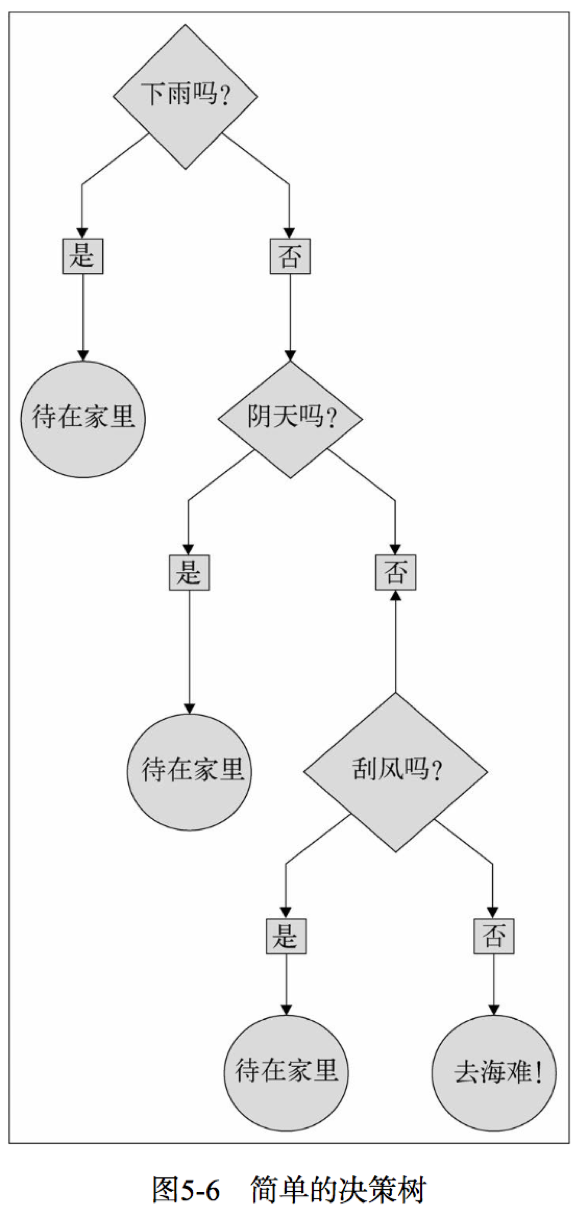
决策树算法是一种自上而下始于根节点的方法,在每一步骤中通过评估特征分裂的信息增益,最后选出分割数据集最优的特征。信息增益通过计算节点不纯度(即节点标签不相似或不同质的程度)减去分割后的两个字节点不纯度的加权和。对于分类任务,这里有两个评估方法用于选择最好分割:基尼不纯合熵。
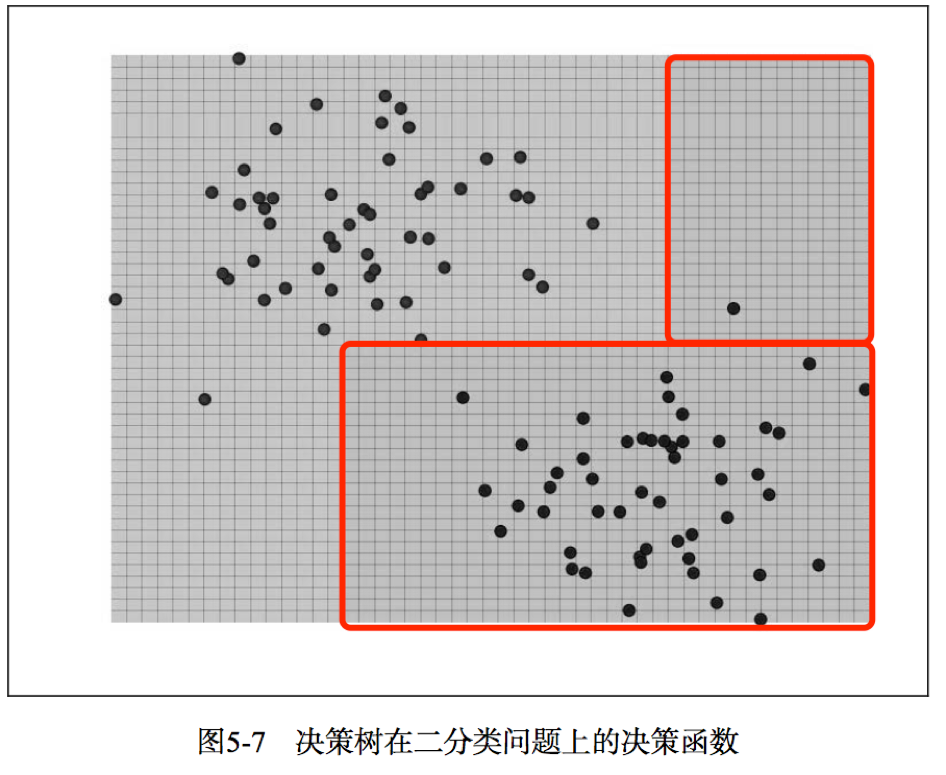
如图5-7所示,可以看出决策树能够适应复杂和非线性的模型。
2. 从数据中抽取合适的特征
对于分类和回归等监督学习方法,需要将目标变量和特征向量放在一起。
MLib中的分类模型通过LabeledPoint对象操作,其中封装了目标变量和特征向量:
虽然在使用分类模型的很多样例中会碰到向量格式的数据集,但在实际工作中,通常还需要从原始数据中抽取特征。这包括封装数值特征,归一或者正则化特征,以及使用1-of-k编码表示类属特征。
从Kaggle/StumbleUpon evergreen分类数据集中抽取特征
//删除文件第一行的列头名称
sed 1d train.tsv > train_noheader.tsv
//启动spark shell
./bin/spark-shell –-driver-memory 4g
val rawData = sc.textFile("/Users/eric/Documents/Spark/spark-machine-learning-book/train_noheader.tsv")
val records = rawData.map(line => line.split("\t"))
records.first()
//把额外的“去掉,用0替换那些缺失数据
val data = records.map { r =>
val trimmed = r.map(_.replaceAll("\"", ""))
val label = trimmed(r.size - 1).toInt
val features = trimmed.slice(4, r.size - 1).map(d => if (d ==
"?") 0.0 else d.toDouble)
LabeledPoint(label, Vectors.dense(features))
}
//对数据进行缓存,并统计数据样本
data.cache
val numData = data.count
//数值数据中包含负特征值,朴素贝叶斯要求特征值非负,因此需要处理
val nbData = records.map { r =>
val trimmed = r.map(_.replaceAll("\"", ""))
val label = trimmed(r.size - 1).toInt
val features = trimmed.slice(4, r.size - 1).map(d => if (d == "?") 0.0 else d.toDouble).map(d => if (d < 0) 0.0 else d)
LabeledPoint(label, Vectors.dense(features))
}
3. 训练分类模型
现在我们已经从数据集中提取了基本的特征并且创建了RDD,接下来开始训练各种模型,为了比较不同模型的性能,我们将训练逻辑回归,SVM,朴素贝叶斯和决策树。MLib大多数情况下会设置明确的默认值,但实际上,最好的参数配置需要通过评估技术来选择,这个后续章节会讨论。
在Kaggle/StumbleUpon evergreen 的分类数据集中训练分类模型
import org.apache.spark.mllib.classification.LogisticRegressionWithSGD
import org.apache.spark.mllib.classification.SVMWithSGD
import org.apache.spark.mllib.classification.NaiveBayes
import org.apache.spark.mllib.tree.DecisionTree
import org.apache.spark.mllib.tree.configuration.Algo
import org.apache.spark.mllib.tree.impurity.Entropy
val numIterations = 10
val maxTreeDepth = 5
val lrModel = LogisticRegressionWithSGD.train(data, numIterations)
val svmModel = SVMWithSGD.train(data, numIterations)
val nbModel = NaiveBayes.train(nbData)
val dtModel = DecisionTree.train(data, Algo.Classification, Entropy, maxTreeDepth)4.使用分类模型
现在我们有四个在输入标签和特征下训练好的模型,接下来看看如何使用这些模型进行预测。我们使用同样的训练数据来解释每个模型的预测方法。
在Kaggle/StumbleUponevergreen数据集上进行预测
这里给出逻辑回归的模型的预测,其他的模型的预测雷同
val dataPoint = data.first
val prediction = lrModel.predict(dataPoint.features)
val trueLabel = dataPoint.label
val predictions = lrModel.predict(data.map(lp => lp.features))
predictions.take(5)
















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











