







1. 引言
此项目笔者主要发过三篇文章,分别对应本项目的三层逻辑,即:
- 信息获取(包括公司代码,公司简称,年份,年报地址)
 https://zhuanlan.zhihu.com/p/631300189
https://zhuanlan.zhihu.com/p/631300189- 目标信息下载并转义(下载目标区间的年报并转为txt格式)
- 目标信息数据分析(对目标区间年报进行文本分析)
用简单的流程图表示如下:
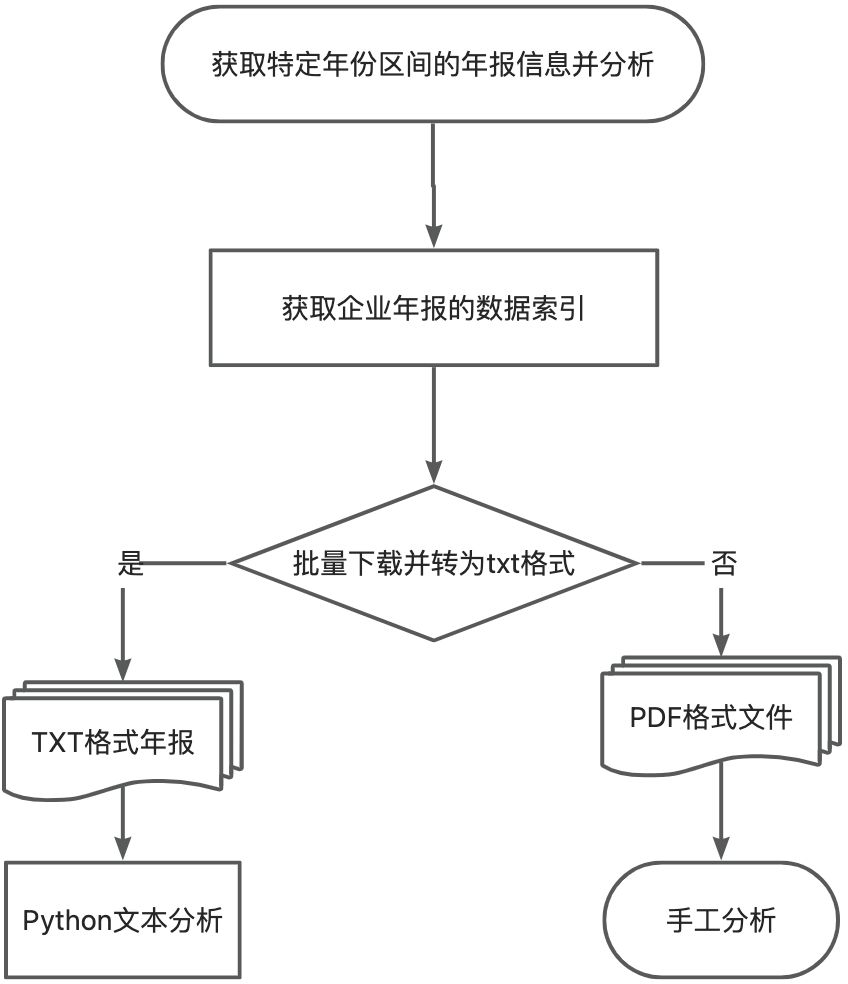
本文主要是对该项目进行总结,以方便读者更好的理解,并对代码进行了更新,提供了更多参数和接口,方便对代码进行修改实现多样化需求。
当然!既然已经做了这么多工作,笔者顺便进行流量一些常用的分析,如参考吴非企业数字化转型的数据,不敢私藏,也分享给大家!
⭐️项目代码已及时更新至网盘与github,相关资源的具体获取方式请查查看文末~
 https://github.com/legeling/Corporate-annual-report-analysis-and-crawling
https://github.com/legeling/Corporate-annual-report-analysis-and-crawling2. 更新内容
2.1获取企业基本数据
新特性:
- ✅全新接口,更全面的获取数据
- ✅更友好的进度显示
- ✅更多可选参数,支持年份区间下载
参数部分代码:
if __name__ == '__main__':
# 全局变量
# 排除列表可以加入'更正后','修订版'来规避数据重复或公司发布之前年份的年报修订版等问题,
exclude_keywords = ['英文', '摘要','已取消','公告']
global counter
global sum
counter = 1 # 计数器
setYear = 2022 #设置下载年份
Flag = True #是否开启批量下载模式
if Flag:
for setYear in range(2004,2022):
counter = 1 # 计数器
main(setYear)
print(f"----{setYear}年下载完成")
else:
main(setYear)
print(f"----{setYear}年下载完成")如代码中所示,目前提供修改排除变量名,指定年份或者年份区间下载。
以及先进的下载进度显示:当前年份下载进度 8.33 %,手动滑稽。
2.2年报批量下载并转格式
新特性:
- ✅可选择是否删除年报PDF原文件
- ✅支持自定义命名结果文件夹
- ✅提供区间年份的批量处理
参数代码:
if __name__ == '__main__':
# 是否删除pdf文件,True为是,False为否
flag_pdf = True
# 是否批量处理多个年份,True为是,False为否
Flag = False
if Flag:
#批量下载并转换年份区间
for year in range(2004,2022):
# ===========Excel表格路径,建议使用绝对路径,务必请自行修改!!!!!!!===========
file_name = f"/Users/文档/MyProgram/PycharmProjects/财报数据/年报/年报链接_{year}【公众号:凌小添】.xlsx"
# 创建存储文件的文件夹路径,如有需要请修改
pdf_dir = f'年报文件/{year}/pdf年报'
txt_dir = f'年报文件/{year}/txt年报'
main(file_name,pdf_dir,txt_dir,flag_pdf)
print(f"{year}年年报处理完毕,若报错,请检查后重新运行")
else:
#处理单独年份:
#特定年份的excel表格,请务必修改。
year = 2022
file_name = f"/Users/文档/MyProgram/PycharmProjects/财报数据/年报/年报链接_{year}【公众号:凌小添】.xlsx"
pdf_dir = f'年报文件/{year}/pdf年报'
txt_dir = f'年报文件/{year}/txt年报'
main(file_name, pdf_dir, txt_dir, flag_pdf)
print(f"{year}年年报处理完毕,若报错,请检查后重新运行")其中file_name为文章1中得到的excel表格路径,请务必按照自己电脑的路径修改,建议使用绝对路径,并注意文件名格式是否一致。
flag_pdf为是否删除pdf文件的开关,打开后会删除下载的pdf文件以节省空间。
Flag为是否开启批处理,注意,若开启批处理,请务必注意路径和文件名格式。
⚠️注意事项:
程序使用logging模块输出日志,请先安装并配置,如果需要直接输出,请修改代码中的输出部分从logging.info或logging.error修改为print
2.3文本分析(重大更新)
新特性:
- ✅支持自选关键词,定制你需要的结果
- ✅更友好的路径管理
- ✅支持指定年份的统计
- ✅新增数据暂存功能,防止数据丢失
- ✅新增统计总字数的功能
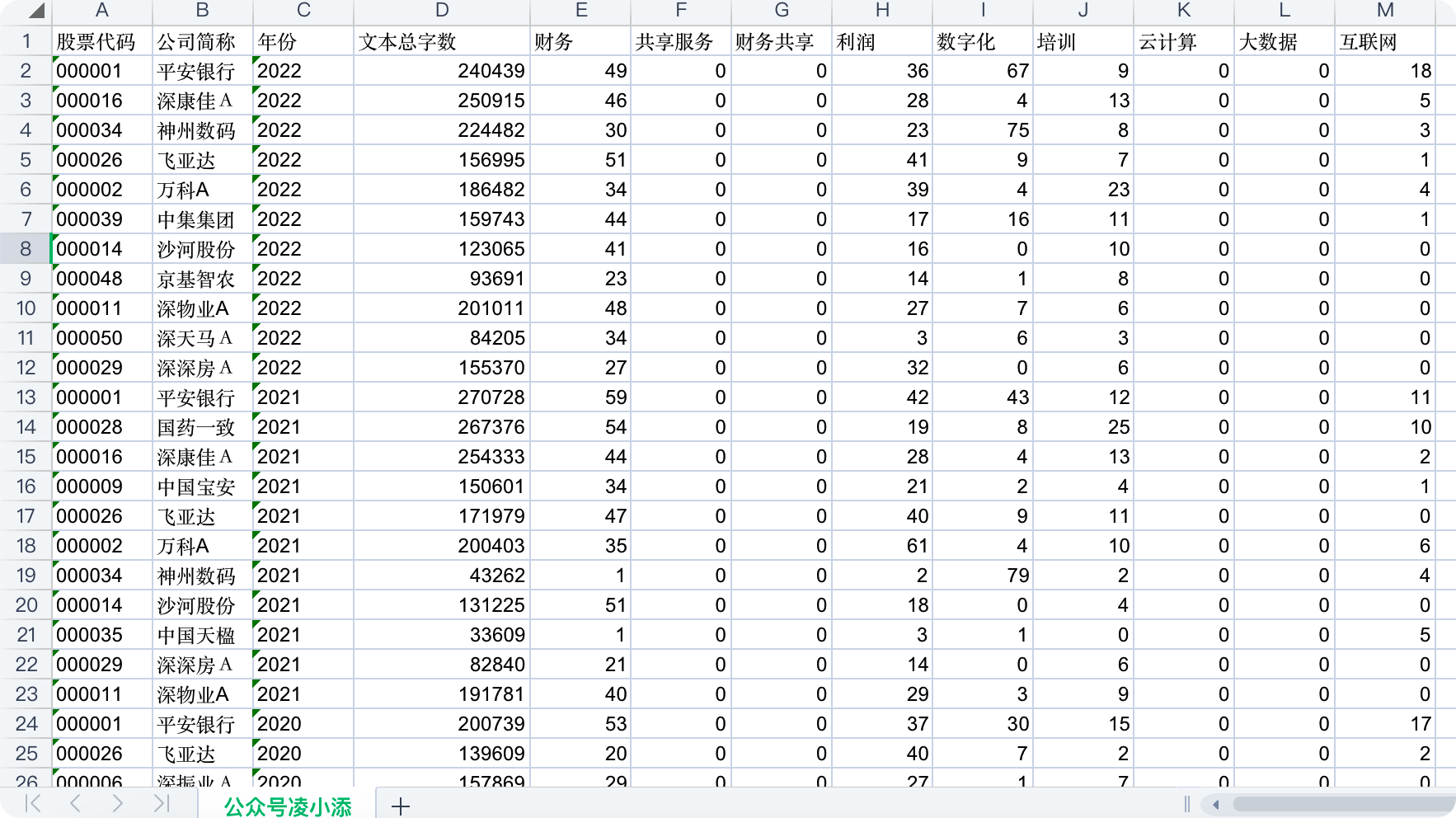
运行结果:
参数代码:
if __name__ == '__main__':
# 设置要提取的关键词列表
keywords = [
'人工智能', '商业智能', '图像理解','投资决策辅助系统']
# !!!!!注意,请务必将各个年份的年报 文件夹 放到一个大的 文件夹 中,并填入此文件夹的内容,请不要存放其他非年报文件。
# 输入根文件夹路径,建议输入绝对路径,如“D:/python项目/上市公司爬虫/年报文件夹”
root_folder = "D:/python项目/上市公司爬虫/年报文件夹"
# 输入年份区间
start_year = "2010"
end_year = "2022"
# 输入处理结果的文件名
name = "词频分析结果.xlsx"
# 暂存数目大小,每处理size个数据会自动保存一次以防数据丢失
size = 100
# 处理文件夹中的所有txt文件,并将结果存储到Excel表格中
try:
if start_year > end_year:
print("起始年份不能大于中止年份!!!!!")
else:
process_files(root_folder, keywords, start_year, end_year)
except Exception as e:
print("文件处理失败!!")
print(str(e))
#!!!注意:如果程序运行无反应,多半是路径和txt文件命名问题!
# 推荐文件名命名格式:“600519_贵州茅台_2019.txt”
# 本代码亦支持如下格式:“600519-贵州茅台2019年年度报告.txt”其中,keywords为要统计的关键词,folder_path为文件夹路径,你可以将下载下的各年份年报文件解压后放放置到新的文件夹,并将folder_path设置为"包含年报的文件夹路径"即可。
正常运行后的结果如图所示:

statr_year为筛选的年份,若选择单独年份只需让两者均为特定年份即可。
⚠️注意事项:
- 请确保在运行代码之前已安装所需的依赖库,如
jieba、xlwt - 文件夹路径
(folder_path)中可以包含多个文件夹,但文件夹中务必包含要处理的文本文件txt,不要将压缩包直接放入! - 如果程序运行无反应,多半是路径和txt文件命名问题!文件名命名格式为:“600519_贵州茅台_2019.txt”,若代码能力较佳,可自行修改正则表达式以适应各种不同格式。
- 本代码新增了暂存功能,程序未运行完毕时即可得到Excel文件,但在程序运行完毕前尽量不要对该文件进行操作以防异常。
3. 具体应用
目前很多学者都使用文本挖掘的方式来构建某些特定的变量,例如:
从变量设计的技术实现上来看,本文通过Python爬虫功能归集整理了上海交易所、深圳交易所全部A股上市企业的年度报告,并通过Java PDFbox库提取所有文本内容,并以此作为数据池供后续的特征词筛选。在企业数字化转型特征词的确定上,本文基于学术领域和实业领域进行了分项讨论
本文参考吴非的方法,选择企业数字化转型(DCG)作为研究目标,并参考如图所示的关键词。
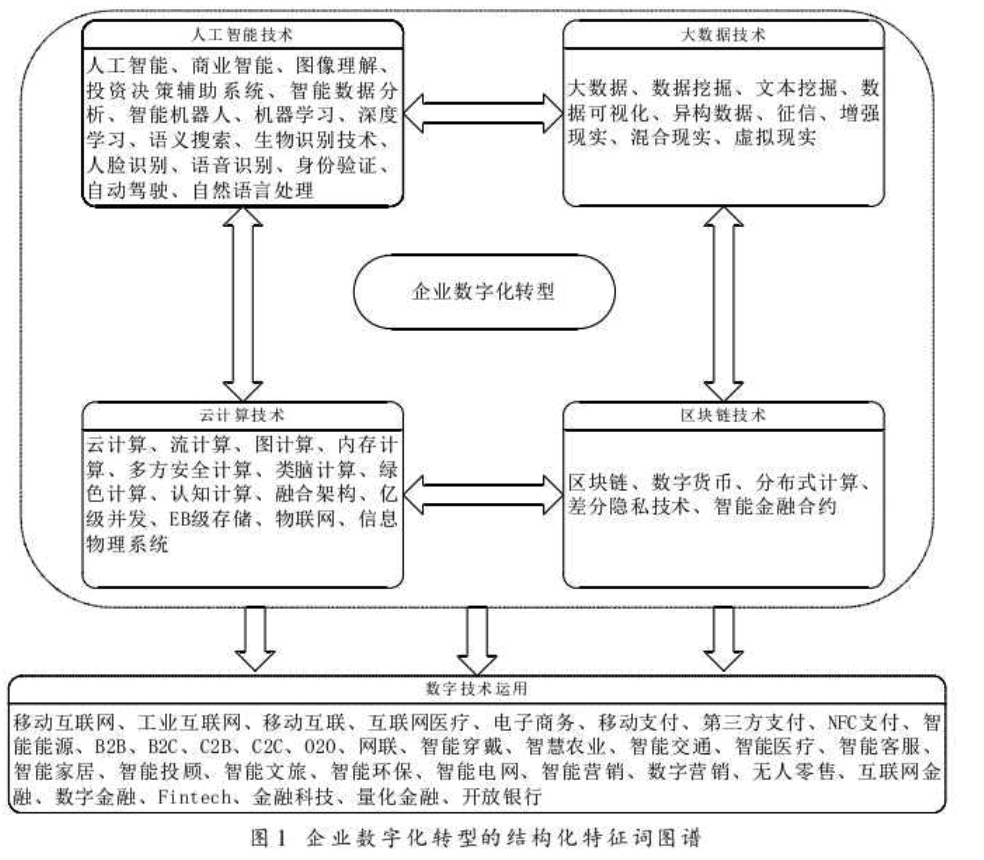
参考如图所示的75个关键词,本文得到了2010-2022年数字化转型词频的Excel文件,共计四万多条数据,不藏私,直接分享给大家!详见文末。
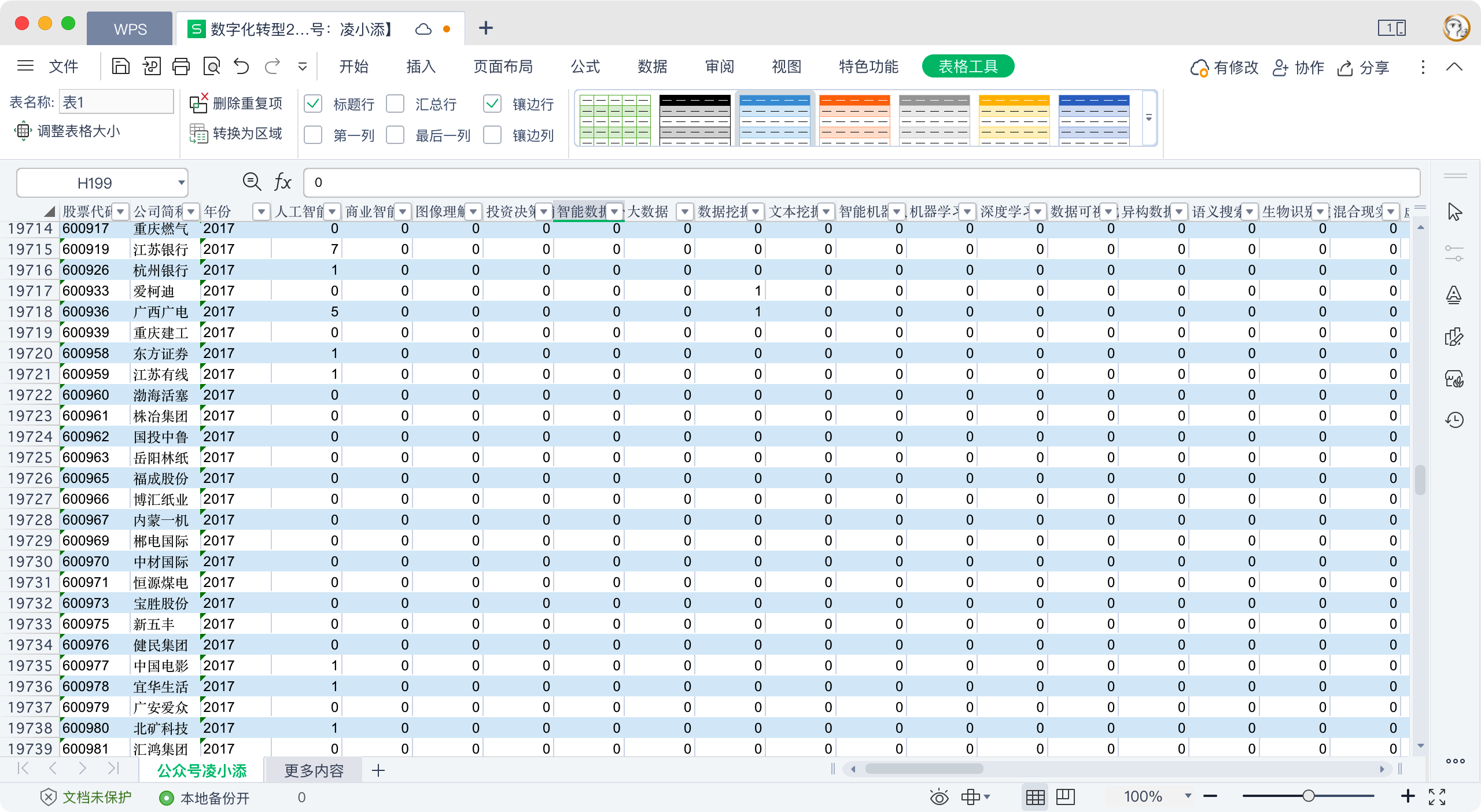
而关于如何计算DCG吴非所著文章如图所示,本文不做探讨。

4. 小结
到这里,这个项目基本结束,笔者之前共发表了三篇文章,分别涵盖了项目的三个关键步骤。这些步骤包括信息获取、目标信息下载并转义以及目标信息数据分析。本文通过简单的流程图为读者梳理。
在本文中,笔者对代码进行了更新,提供了更多参数和接口,并简单介绍了各参数,使得代码更加灵活,满足不同的需求。总而言之,通过这个项目的详细介绍和更新的代码,我希望能够帮助读者更好地理解和操作。
⭐️ 项目代码已及时更新至网盘,网盘链接获取请于评论区留言,若想及时获取,请关注公众号“凌小添”并回复关键词数字化,即可获数字化转型关键词分析成品资源。
资源列表:
- ⭐️项目完整代码(已更新)
- ⭐️2004-2022年上市公司TXT版年报
- ⭐️2010-2022年数字化转型词频
- ⭐️常用控制变量及相关数据
如果你有任何问题或需要进一步的帮助,欢迎随时交流~


















 2450
2450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











