






一、Self-attention
运作过程简述:输入一定长度的向量序列,输出同样数量的向量,并且输出的每个向量都会考虑整个sequence的信息。

Self-attention可以叠加很多次,和FC交替使用。
- Self-attention:处理整个sequence的资讯。
- FC:专注于处理某一位置的资讯。

运作过程-图示详解:输入一定长度的向量序列,输出同样数量的向量,并且输出的每个向量都会考虑整个sequence的信息。
- input:a1,a2,a3,a4
- output:b1,b2,b3,b4 (每个bi都是考虑了所有的ai产生)。并不需要依序产生,b1,b2,b3,b4同时计算
举例如何产生b1:根据a1,找出sequence里与a1相关的其他向量,即哪些向量和判断a1是哪个class/regression数值时所需要用到的。用 α 表示每个向量与a1的关联程度

Self-attention如何决定两个向量之间的关联性?即如何计算attention

在Self-attention中计算向量的关联性:
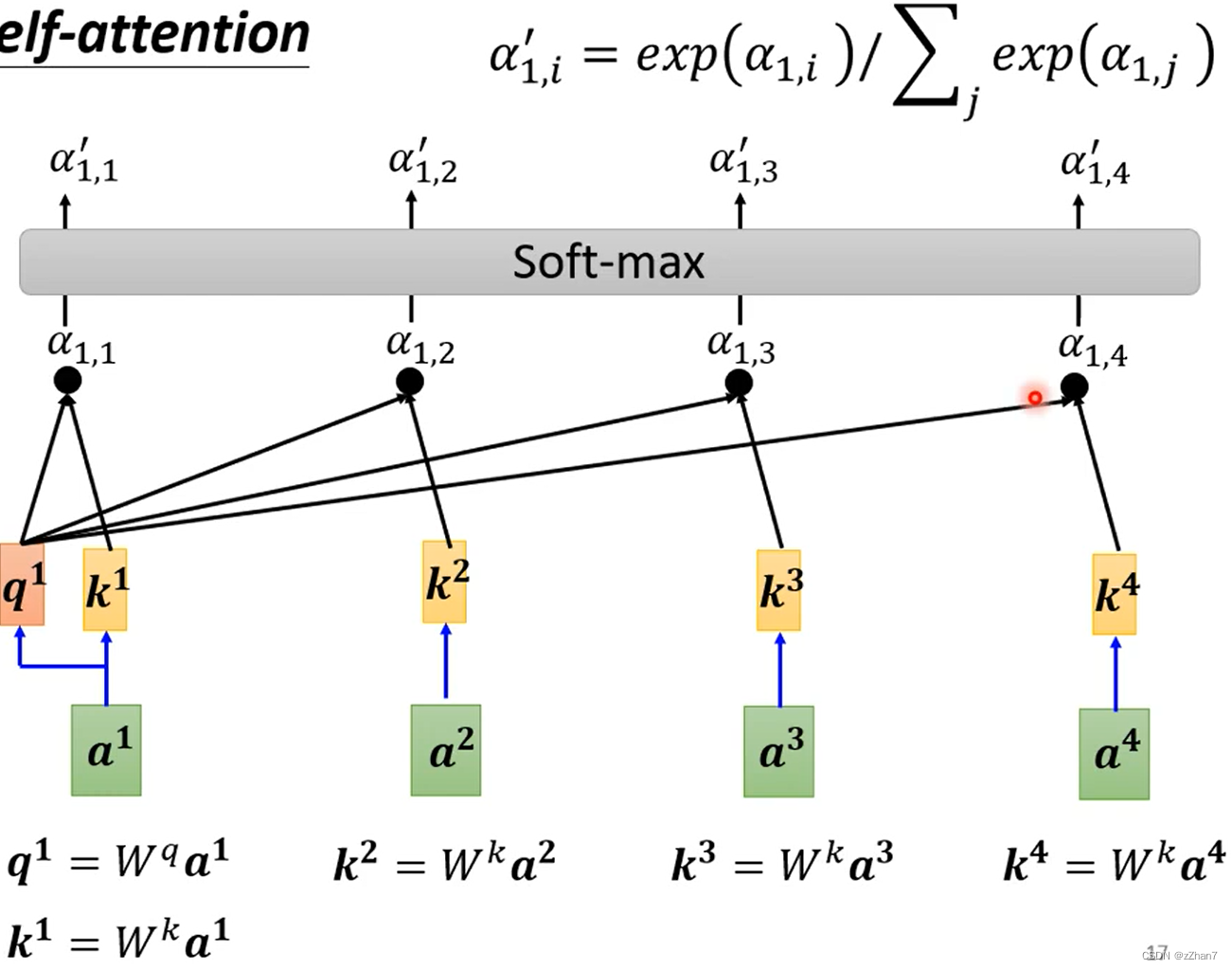
α:attention score,表示各向量与a1的关联性。
α' :经过softmax后,相当于权重,用于抽取sequence中与a1相关的重要资讯。

某向量的attention score越大,该向量的v就越接近抽取出的结果b
运作过程-公式详解:

Self-attention输入是I,输出是O
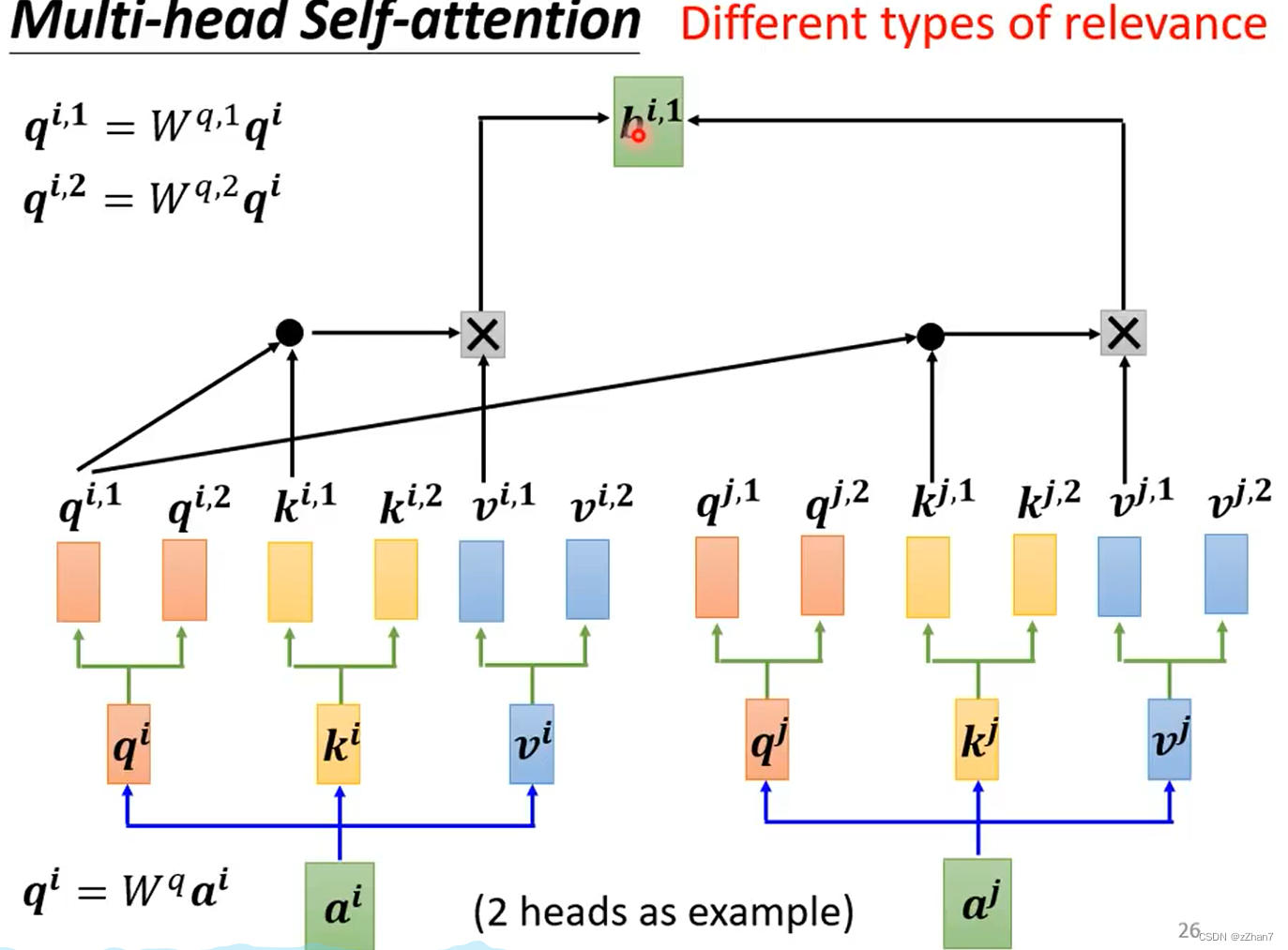
二、Multi-head Self-attention
相关性:Self-attention用q去找相关的k
因为相关性是具有多种不同的定义与形式,需要有不同的q,每个q负责不同种类的相关性。
三、Positional Encoding
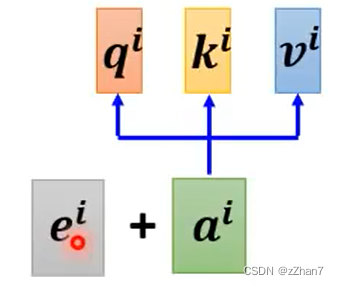
Self-attention没有考虑位置的信息。
如何在Self-attention考虑位置的信息???为每个位置设定一个唯一的位置向量 ei
四、Self-attention在图像方面的应用
之前,把一张图片看成一个很长的向量
其实,一张图片也可看做是一个vector set,即把每一个pixel看作一个三维向量

Self-attention & CNN
- CNN可看作简化版的Self-attention
因为CNN只考虑卷积核大小内部的资讯,而Self-attention考虑的是整张图片资讯
- Self-attention可看作复杂化的CNN
CNN中的卷积核大小是人决定的,而Self-attention自己找出与相关的像素,类似于自动学出卷积核的形状















 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









