







章节内容
上一节完成:
- HOSTS 配置(非常重要!坑多!)
- ROOT权限开启(重要)
- SSH KEY 生成
- SSH 三台云服务器 免登陆
- 分发脚本编写和测试
背景介绍
这里是三台公网云服务器,每台 2C4G,搭建一个Hadoop的学习环境,供我学习。
之前已经在 VM 虚拟机上搭建过一次,但是没留下笔记,这次趁着前几天薅羊毛的3台机器,赶紧尝试在公网上搭建体验一下。
注意,如果你和我一样,打算用公网部署,那一定要做好防火墙策略,避免不必要的麻烦!!!
请大家都以学习为目的,也请不要对我的服务进行嗅探或者攻击!!!
但是有一台公网服务器我还运行着别的服务,比如前几天发的:autodl-keeper 自己写的小工具,防止AutoDL机器过期的。还跑着别的Web服务,所以只能挤出一台 2C2G 的机器。那我的配置如下了:
- 2C4G 编号 h121
- 2C4G 编号 h122
- 2C2G 编号 h123

请确保上一节内容全部完毕和跑通!!!
Hadoop 分发
我们之前只配置 h121 节点的内容,但是h122和h123机器上还没有环境。
需要借助我们上节的工具来完成一键分发。
rsync-script /opt/servers/hadoop-2.9.2
注意!!!这里只是分发过去了,但是 JAVA_HOME 和 HADOOP_HOME 环境变量等内容还是需要自己配置的!!!
注意!!!这里只是分发过去了,但是 JAVA_HOME 和 HADOOP_HOME 环境变量等内容还是需要自己配置的!!!
注意!!!这里只是分发过去了,但是 JAVA_HOME 和 HADOOP_HOME 环境变量等内容还是需要自己配置的!!!
单机启动
确保之前的所有内容都可以跑通,那么激动人心的时刻来了!!!
节点分配
这里需要再放一次节点的分配图,方便大家查看:

目前 登录到 h121 节点上。
初始格式化
NameNode 节点初始化,别的机器不需要执行
这步是必须的!!!
这步是必须的!!!
这步是必须的!!!
hadoop namenode -format
等待一会儿之后,如果出现如图的内容,那代表你已经顺利格式化
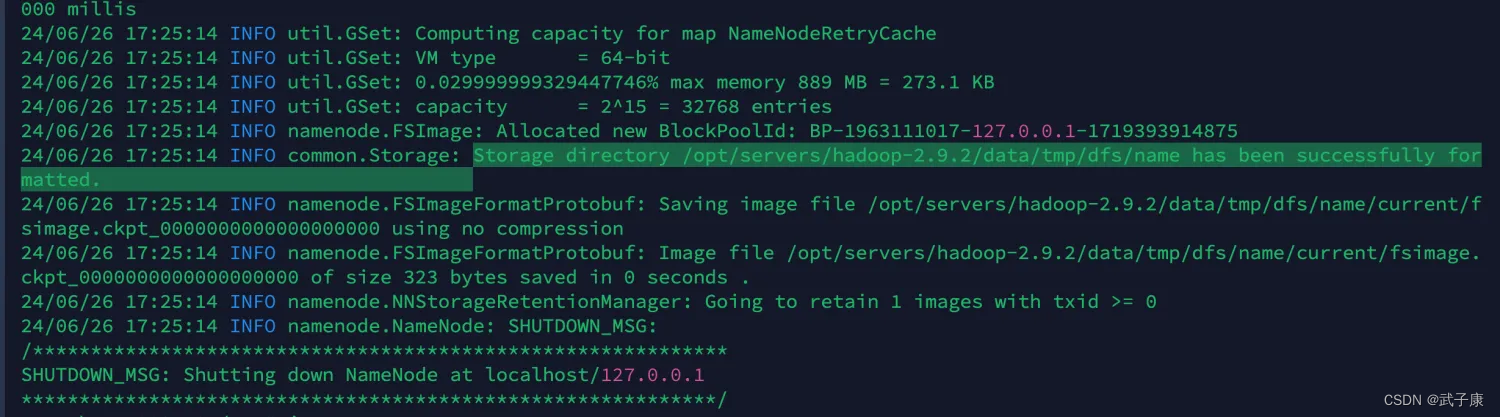
可以看到,控制台中给我们的路径:
/opt/servers/hadoop-2.9.2/data/tmp/dfs/name
可以查看一下当前初始化的结果:
cd /opt/servers/hadoop-2.9.2/data/tmp/dfs/name
ls

NameNode
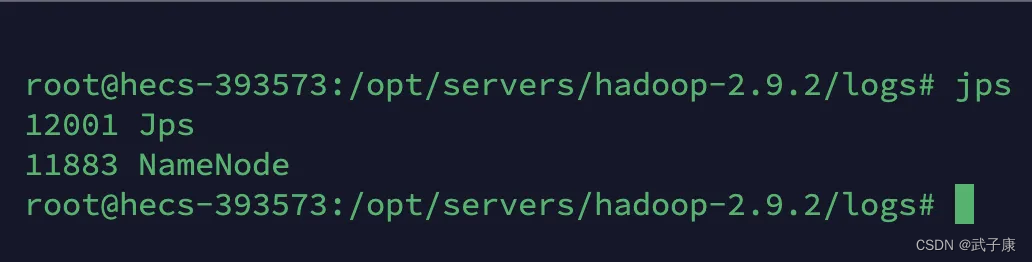
启动最关键的节点 NameNode:
hadoop-daemon.sh start namenode
jps
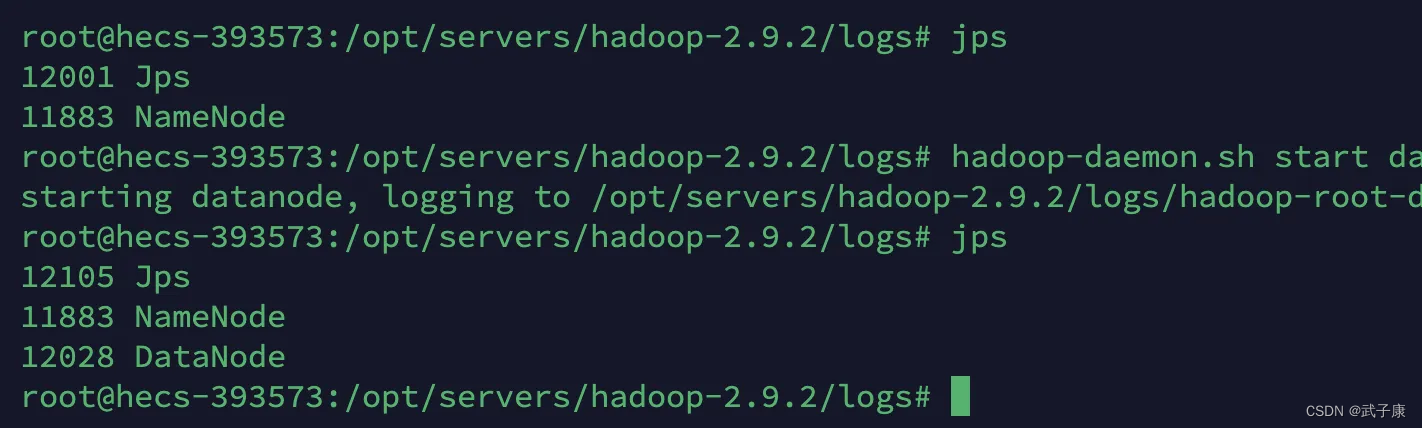
DataNode
h121和h122和h123都启动 DataNode
hadoop-daemon.sh start datanode
jps
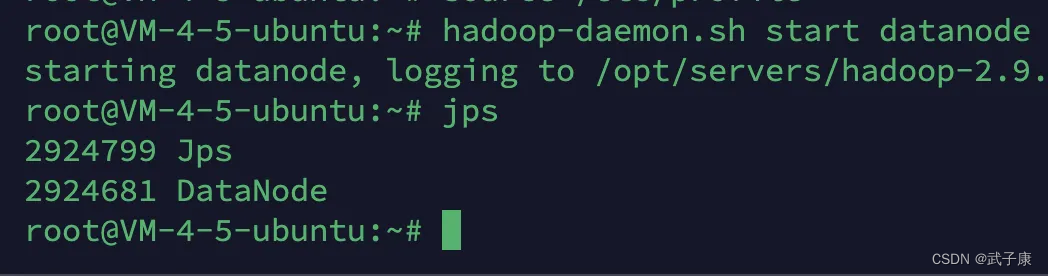
h121
h122
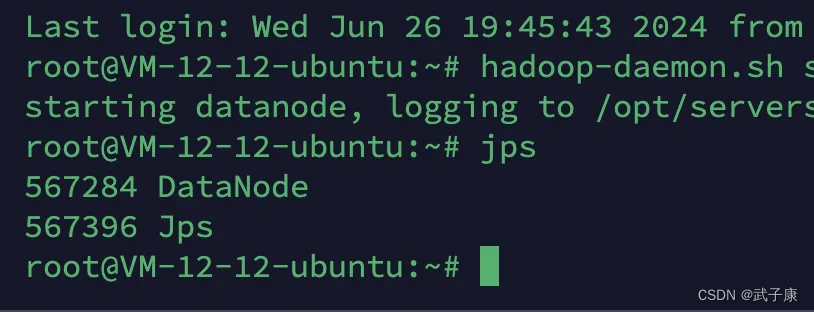
h123
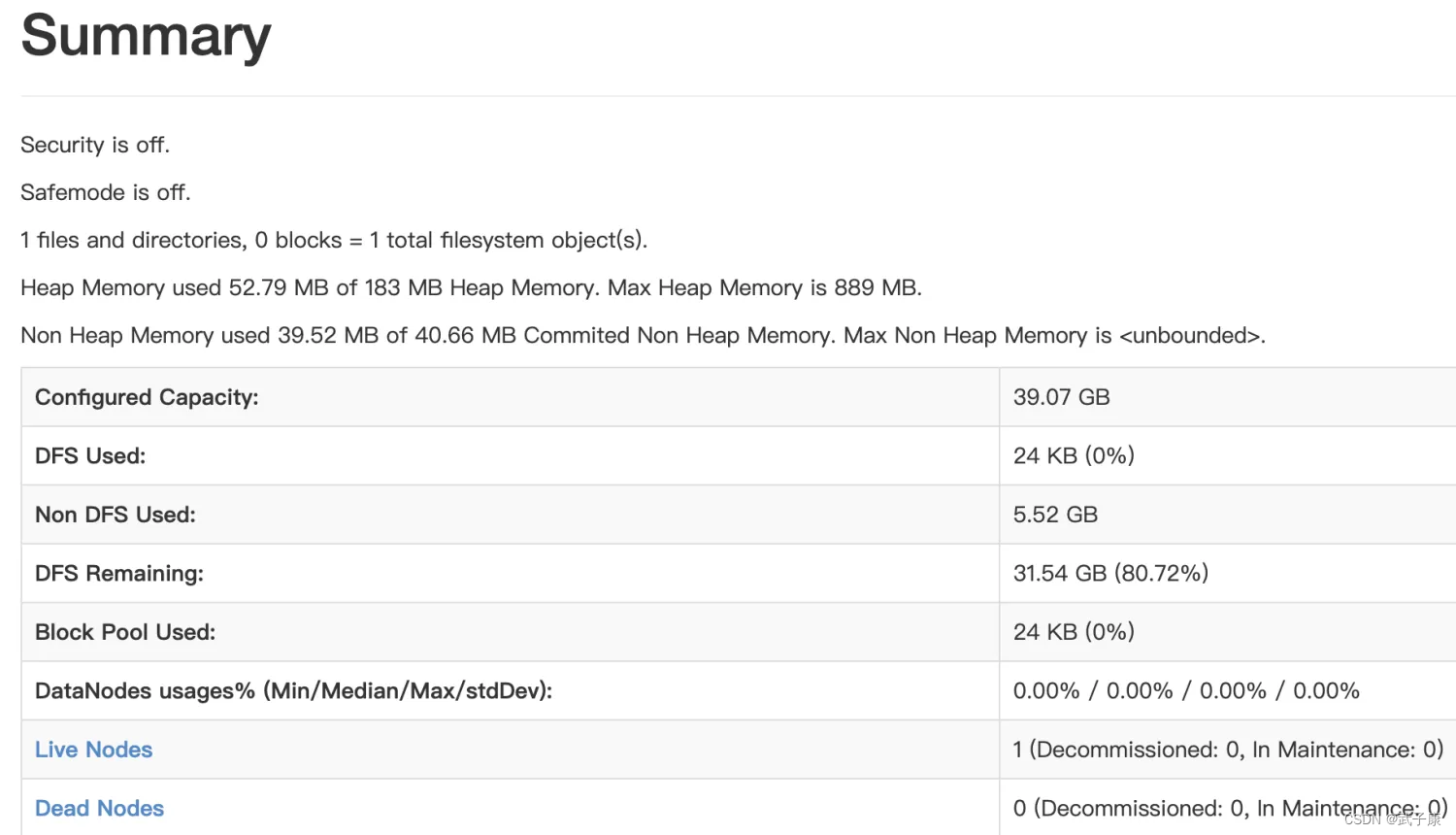
访问服务
顺利启动后,我们查看WEB UI界面
http://h121.wzk.icu:50070/dfshealth.html#tab-overview
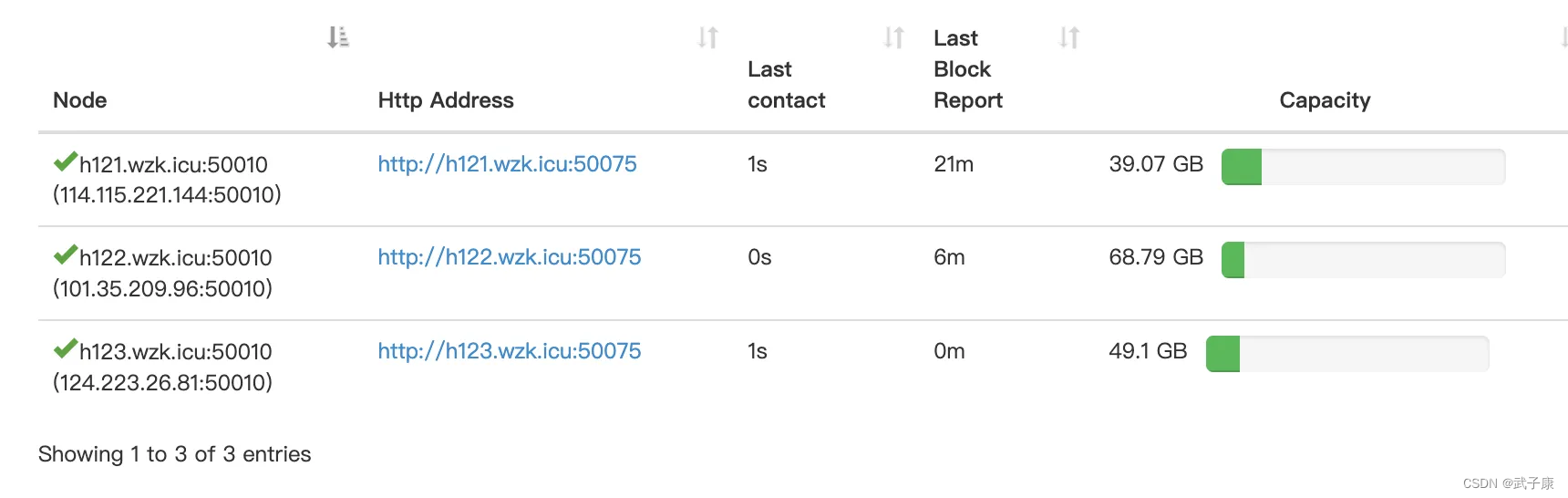
查看 DataNode 可以看到
Yarn启动
节点分配
我们需要启动
- Node Manager
- ResourceManager

h121启动
yarn-daemon.sh start nodemanager
jps
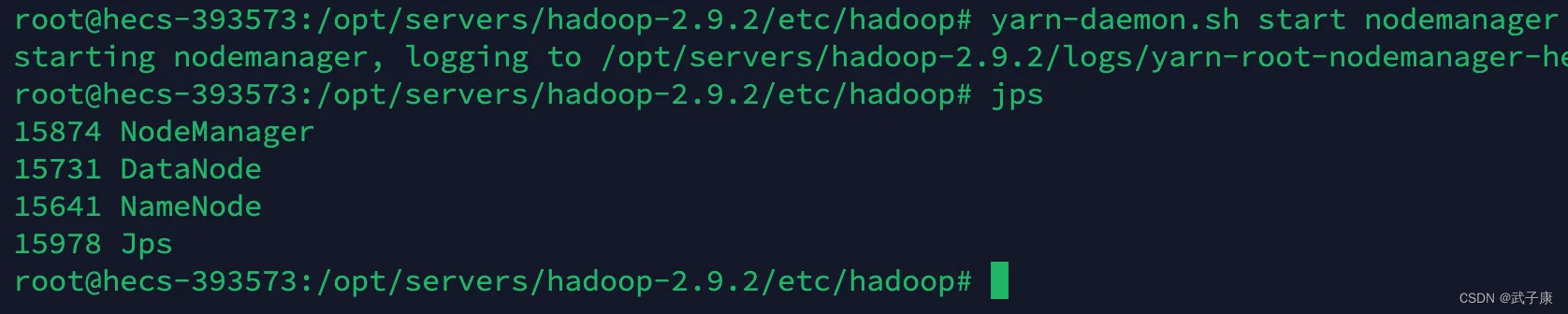
h122 启动
yarn-daemon.sh start nodemanager
jps

h123 启动
yarn-daemon.sh start nodemanager
yarn-daemon.sh start resourcemanager
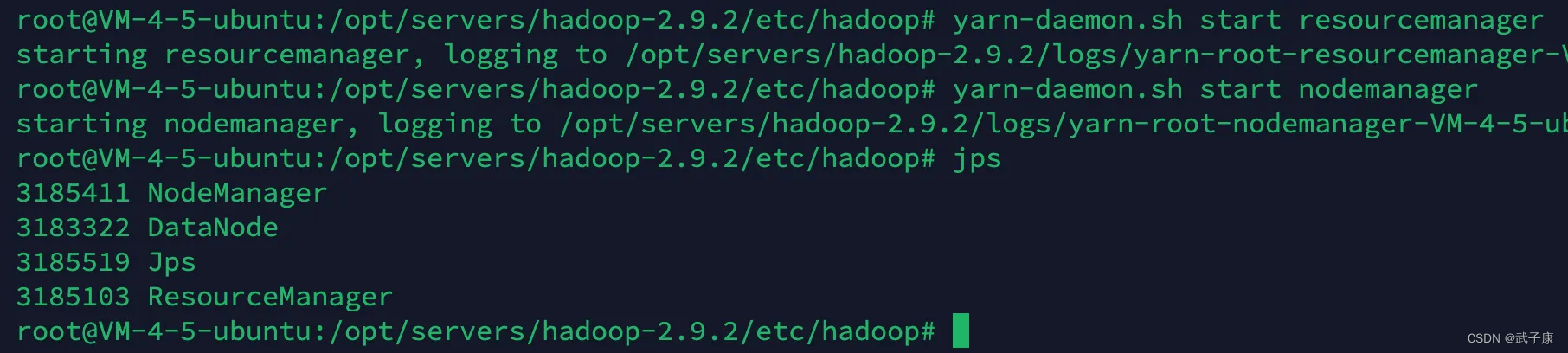
访问服务
http://h123.wzk.icu:8088/cluster
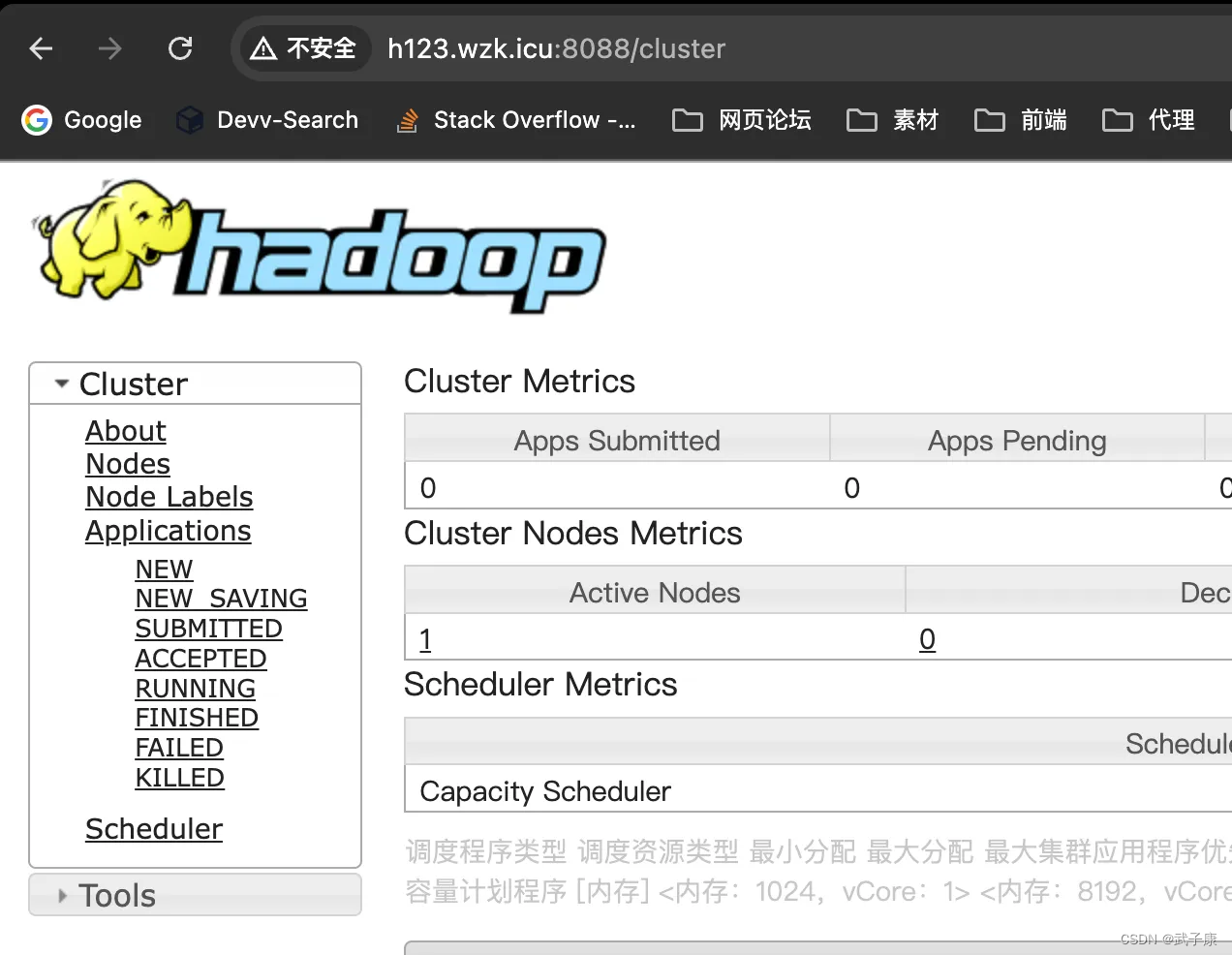
集群启动
如果你已经走到了这里,真的挺不容易的!恭喜你!一切顺利!
单节点启动后,就不需要再对 NameNode 进行格式化了,先停止之前节点的服务。
停止服务
需要在 h121 h122 h123 上都执行一次!!!
需要在 h121 h122 h123 上都执行一次!!!
需要在 h121 h122 h123 上都执行一次!!!
hadoop-daemon.sh stop datanode
hadoop-daemon.sh stop namenode
yarn-daemon.sh stop nodemanager
yarn-daemon.sh stop resourcemanager
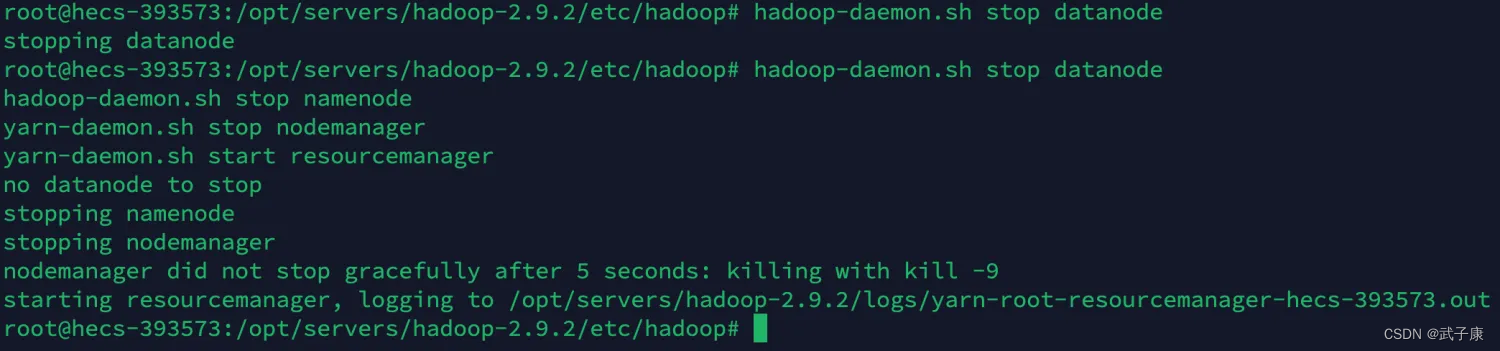
HDFS集群
在h121集群上进行执行!
start-dfs.sh
h121
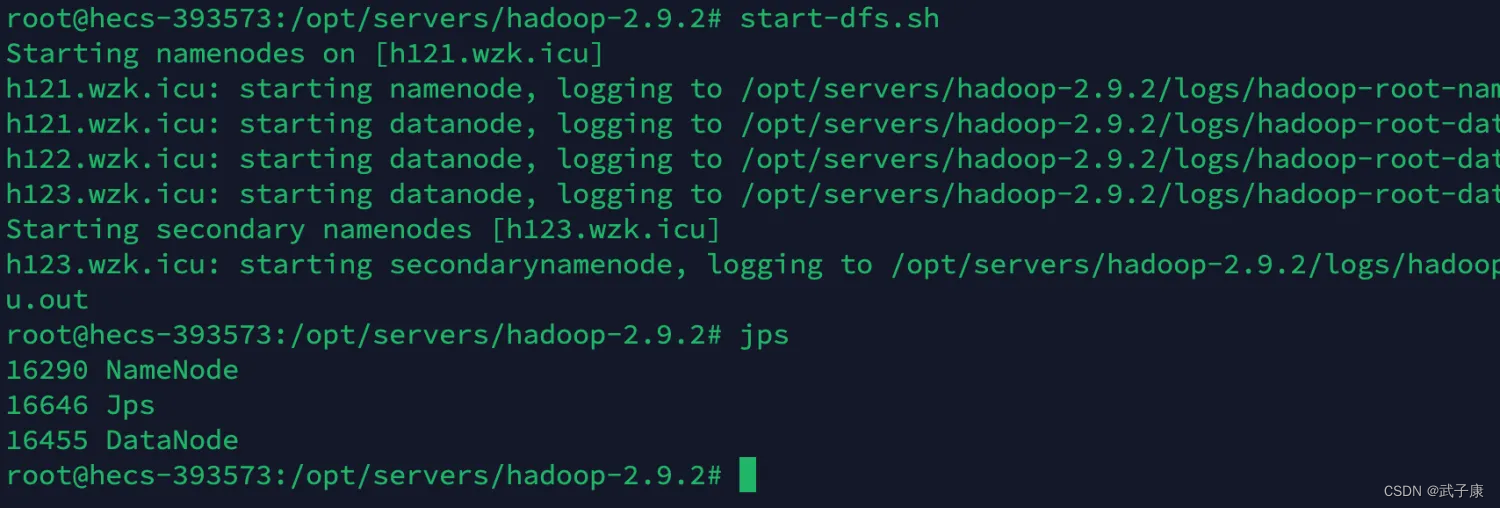
h122

h123

Yarn集群
在h123集群上进行执行!
注意:NameNode 和 ResourceManager 不在同一个机器上,不能在 NameNode 节点上启动 Yarn,应该在ResourceManager上启动。
start-yarn.sh
h123
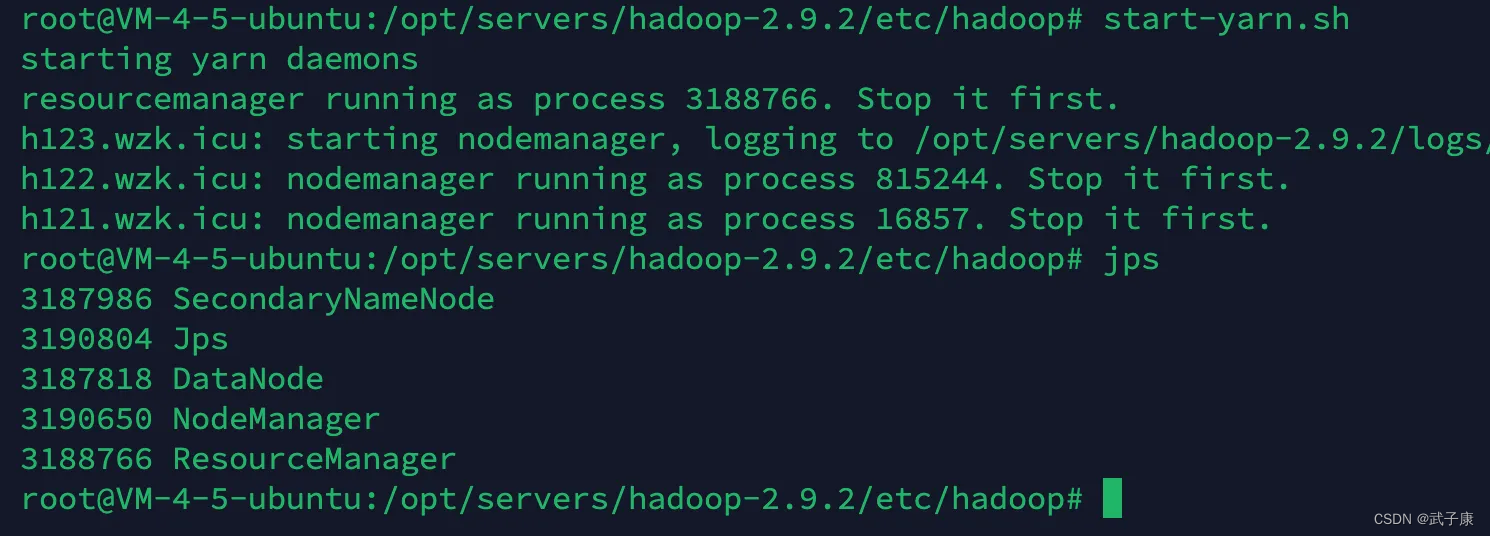
h121
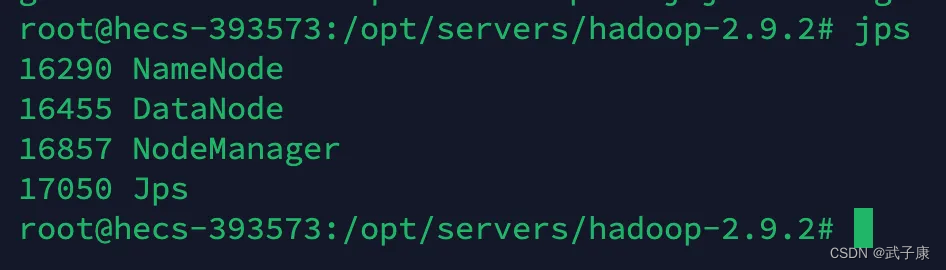
h122
















 1711
1711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









