









1从视频中获取图片
安装opencv
pip3 install opencv-python
# 视频分解成图片
# 1 load加载视频 2 读取info 3 解码 单帧视频parse 4 展示 imshow
import cv2
# 获取一个视频打开cap
cap = cv2.VideoCapture('1.mp4')
# 判断是否打开
isOpened = cap.isOpened
print(isOpened)
#帧率
fps = cap.get(cv2.CAP_PROP_FPS)
#宽度
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
#高度
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
print(fps,width,height)
i = 0
while(isOpened):
if i == 100:
break
else:
i = i+1
(flag,frame) = cap.read() # 读取每一张 flag读取是否成功 frame内容
fileName = 'imgs/'+str(i) + '.jpg'
print(fileName)
if flag == True:
#写入图片
cv2.imwrite(fileName,frame,[cv2.IMWRITE_JPEG_QUALITY,100])
print('end!')
a.全局变量的赋值
b.hog对象的创建
c.SVM分类的创建
d.计算hog以及label标签
e.训练
f.检测
# 1 准备样本 2 训练 3 预测
# 1 样本
# pos是正样本,包含需要检测的物体 neg是负样本,不包含需要检测的物体
# 图片大小是64*128
# 如何获取样本? 1 来源于网络 2 源自公司内部 3 自己收集
# 一个好的样本 远胜过一个复杂的神经网络
# 正样本:尽可能的多样 环境多样 干扰多样 820 负样本 1931 1:2或者1:3之间
# 2 训练
# 1.参数 2 hog 3.SVM 4.computer hog 5.label 6.train 7.predicr 8.draw
import cv2
import numpy as np
import matplotlib.pyplot as plt
#1 设置全局变量 在一个windows窗体中有105个block,每个block下有4个cell,每个cell下有9个bin,总共3780维
PosNum = 820 # 正样本的个数
NegNum = 1931 # 负样本的个数
winSize = (64,128) # 窗体大小
blockSize = (16,16) # 105个block
blockStride = (8,8) # block的步长
cellSize = (8,8)
nBin = 9
#2 hog对象的创建
hog = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nBin)
#3 SVM分类器的创建
svm = cv2.ml.SVM_create()
#4 5 计算hog label
featureNum = int(((128-16)/8+1)*((64-16)/8+1)*4*9) # 3780
featureArray = np.zeros(((PosNum+NegNum),featureNum),np.float32)
labelArray = np.zeros(((PosNum+NegNum),1),np.int32)
# SVM 监督学习 样本和标签 SVM学习的是image的hog特征
for i in range(0,PosNum):
fileName = 'pos/'+str(i+1)+'.jpg'
img = cv2.imread(fileName)
hist = hog.compute(img,(8,8)) # 当前hog的计算 3780维的数据
for j in range(0,featureNum):
featureArray[i,j] = hist[j] # hog特征的装载
labelArray[i,0] = 1 # 正样本标签为1
for i in range(0,NegNum):
fileName = 'neg/'+str(i+1)+'.jpg'
hist = hog.compute(img,(8,8))
for j in range(0,featureNum):
featureArray[i+PosNum,j] = hist[j]
labelArray[i+PosNum,0] = -1 # 负样本标签为-1
# 设置SVM的属性
svm.setType(cv2.ml.SVM_C_SVC)
svm.setKernel(cv2.ml.SVM_LINEAR)
svm.setC(0.01)
# 6 train
ret = svm.train(featureArray,cv2.ml.ROW_SAMPLE,labelArray)
# 7 检测(创建myHog--->myDect参数得到-->来源于resultArray(公式得到) rho(训练得到))
# rho
alpha = np.zeros((1),np.float32)
rho = svm.getDecisionFunction(0,alpha)
print(rho)
print(alpha)
# resultArray
alphaArray = np.zeros((1,1),np.float32)
supportVArray = np.zeros((1,featureNum),np.float32)
resultArray = np.zeros((1,featureNum),np.float32)
alphaArray[0,0] = alpha
resultArray = -1*alphaArray*supportVArray #计算公式
# mydect参数
myDetect = np.zeros((3781),np.float32)
for i in range(0,3780):
myDetect[i] = resultArray[0,i]
myDetect[3780] = rho[0]
# 构建好myHog
myHog = cv2.HOGDescriptor()
myHog.setSVMDetector(myDetect)
# 待检测图片的加载
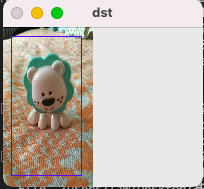
imageSrc = cv2.imread('Test.jpg',1)
# 检测小狮子 (8,8)winds的滑动步长 1.05 缩放系数 (32,32)窗口大小
objs = myHog.detectMultiScale(imageSrc,0,(8,8),(32,32),1.05,2)
# 起始位置、宽和高 objs三维信息
x = int(objs[0][0][0])
y = int(objs[0][0][1])
w = int(objs[0][0][2])
h = int(objs[0][0][3])
# 目标的绘制 图片 起始位置 终止位置 颜色
cv2.rectangle(imageSrc,(x,y),(x+w,y+h),(255,0,0))
# 目标的展示
cv2.imshow('dst',imageSrc)
cv2.waitKey(0)
















 1923
1923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









